🔥 Did you like the NEJM NY study?
Let’s have a look at the Lancet’s!
TLTR: again, the surprising stuff is in the appendix.
Let’s have a look at the Lancet’s!
TLTR: again, the surprising stuff is in the appendix.
So, wow! 96032 hospitalised patients from 671 hospitals!
This is huge, unprecedented. And therefore it must be SUPER reliable, right?
Well, not everyone agrees.
Steven Phillips MD doesn't think that bigger is better.
This is huge, unprecedented. And therefore it must be SUPER reliable, right?
Well, not everyone agrees.
Steven Phillips MD doesn't think that bigger is better.
As for Samuel Brown, he mentions the “indication bias”, which is the bias that occurs when the risk of an adverse event is related to the indication for medication use but not the use of the medication itself...
The indication bias is very problematic in observational studies. And also very common. (Fun fact: follow the link below then in the Example section, follow the “An observational study” link and see where it was published).
catalogofbias.org/biases/confoun…
catalogofbias.org/biases/confoun…
It is even more problematic regarding a treatment — which is supposed to work when administered early —, is given late:
1. You’re missing the chance to see it in action when it could work,
2. You’re observing that it does not work,
3. You gave it to more severely ill patients.
1. You’re missing the chance to see it in action when it could work,
2. You’re observing that it does not work,
3. You gave it to more severely ill patients.
👉 It looks like it’s worsening the patient’s condition !
In order to evaluate a possible bias, the first point of interest is the inclusion criteria. Or should we say "exclusion" here.
In most studies of this kind, the inclusion criteria is usually “at least 48h of treatment”.
In order to evaluate a possible bias, the first point of interest is the inclusion criteria. Or should we say "exclusion" here.
In most studies of this kind, the inclusion criteria is usually “at least 48h of treatment”.
In this study, it’s quite different,... and it matters a lot. 

It matters a lot, because as @JanieHsieh points out, “excluding patients treated after 48 hours of diagnosis in effect does nothing but possibly exclude less ill patients who probably didn’t need treatment as immediately as other cases”
Again, this concern is especially prominent in the context of a treatment which might be given preferentially to the most severely ill.
And precisely, it’s a known fact that hospitalists tend to treat COVID patients with HCQ only when they reach a certain level of illness.
And precisely, it’s a known fact that hospitalists tend to treat COVID patients with HCQ only when they reach a certain level of illness.
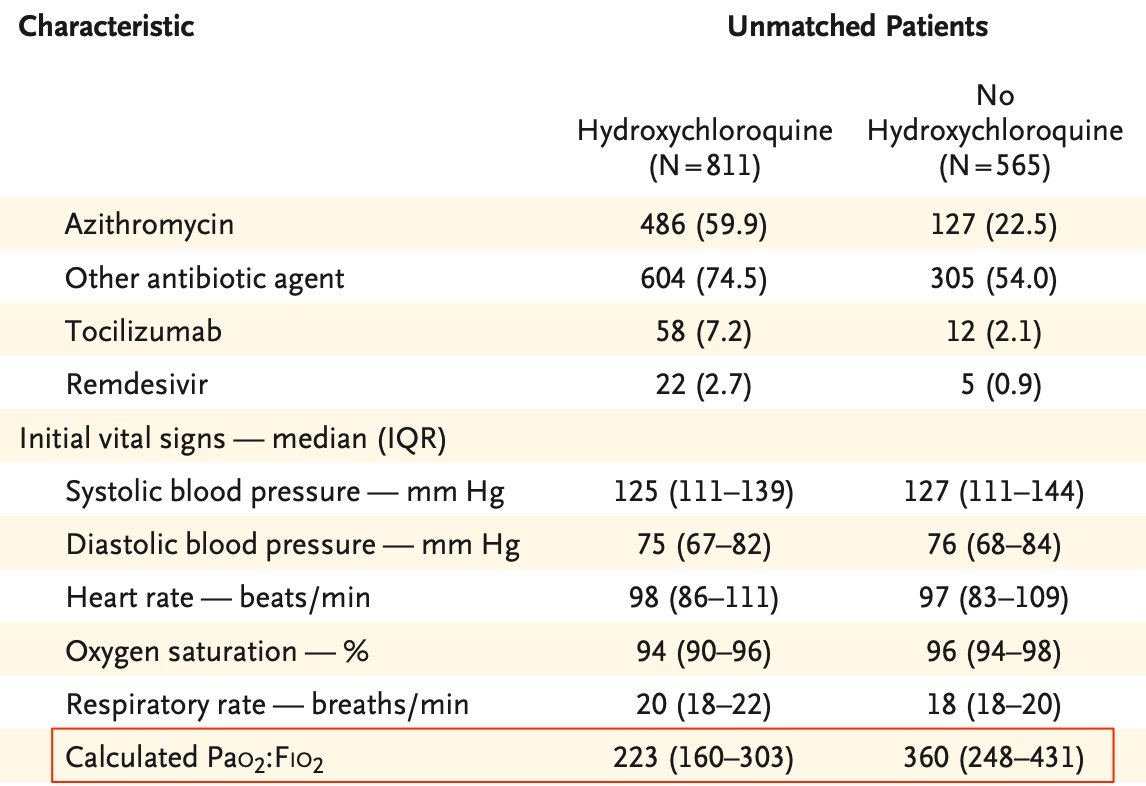
It has been very apparent in every single study so far, and so was it in the NEJM NY study:
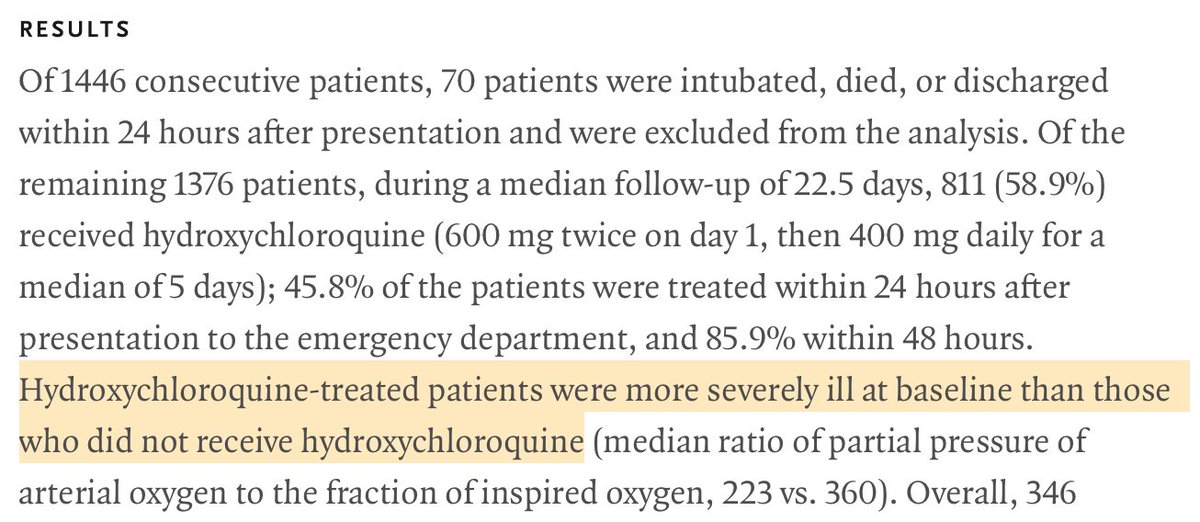
In the Lancet mega-dataset, it is also the case, but it’s a bit less obvious. Comorbidities and baseline disease severity indicators are slightly more severe…
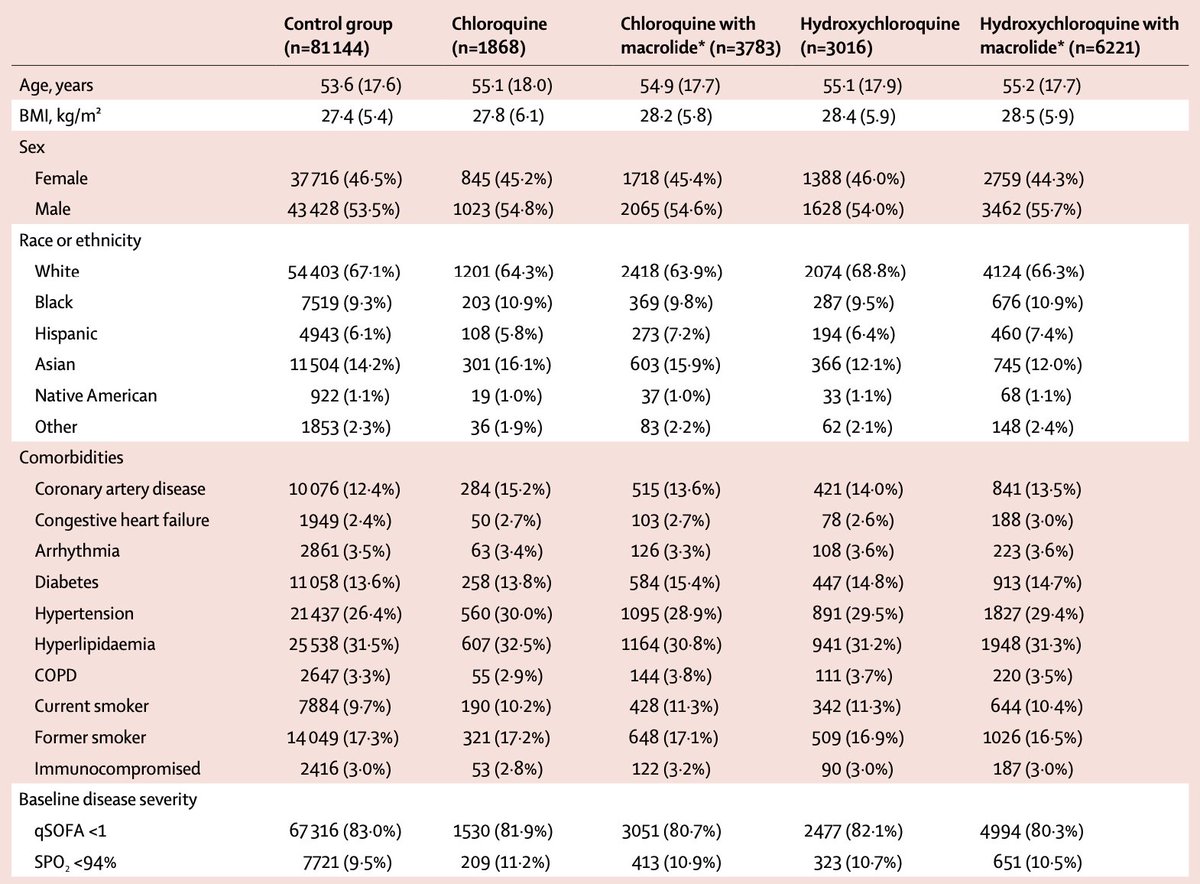
…but it is to be noted the baseline disease severity indicators are scarce and vague.

94% is quite a high cut-off SPO2 value when 94% is almost normal (I’ve been personally at 95% for weeks after a mild covid) and severe covid patients can be as low as 50%…
ecowatch.com/coronavirus-sy…
ecowatch.com/coronavirus-sy…

As for the “quick &̶ ̶d̶i̶r̶t̶y̶ SOFA” score, … hmmm, why is mentioned at all, as it has been established that it is not appropriate to identify Covid-19 patients to have poor outcomes typical of sepsis?
ncbi.nlm.nih.gov/pmc/articles/P…
ncbi.nlm.nih.gov/pmc/articles/P…


Relying on this qSOFA score is all the more surprising that the authors of the study, which is a shameless plug for @surgisphere, are not even leveraging their own praised scoring index.
So basically, we are left with incredibly poor indicators of the degree of illness of the patients at the baseline of the study despite the touted capabilities of @surgisphere diagnostic tools. 🤔
businesswire.com/news/home/2020…
businesswire.com/news/home/2020…
In spite of that, since the authors needed to compensate the unbalance between groups, those variables were used (along with comorbidities data) to calculate propensity scores. “Propensity scores”. Does it ring a bell ?
Propensity score matching (PSM) is a quite recent (1983) statistical technique which is used to “compute” control groups that you can compare to the treatment group. The problem is,…
…PSM is known, according to Harvard professors “often accomplish the opposite of its intended goal, thus increasing imbalance, inefficiency, model dependence, and bias”.
gking.harvard.edu/publications/w…
gking.harvard.edu/publications/w…
Dr Samuel Brown obviously shares that concern:
Apparently, the authors of the study fell into every possible pitfall in that regard.
So, wow, running a dubious statistical processing method on poor value clinical data, what could go wrong ?
Well, of course, this. ⤵️
Well, of course, this. ⤵️

But let’s be rigorous and dive into the data, Supplementary Appendix, pages 15, 16, 17, 18.
🤓
🤓
Remember the NEJM NY study that showed “no significant association between hydroxychloroquine use and intubation or death” ?

Well, that exact same composite endpoint reveals a strikingly different outcome this time, with a 29.1% “ventilator or mortality” in the HCQ group vs 14.9% in the NONE group.
This is TWICE as much! 🤯
This is TWICE as much! 🤯

Remember, the main finding of the NEJM NY study (which was touted as state of the art) was that this “ventilator or mortality” endpoint was identical, HCQ or not. This should be a hint that something is going on here.
According to the authors (who are cardiologists), the underlying explanation for this increased mortality seems to be the cardiovascular toxicity of HCQ. To be honest, it sounds plausible since HCQ and AZT are known to increase the risk of arrhythmia, which is also observed here.
However, let’s have a look at the “mechanical ventilation” outcome separately, which makes sense since arrhythmia is not really known to require patients to be intubated.
And now that’s almost a x2.5 factor! 🤯
And now that’s almost a x2.5 factor! 🤯

This is a VERY surprising value, considering that even the most negative studies so far never reported such an effect.
Ex: Mahevas: medrxiv.org/content/10.110…

Or the "Veterans study"

Such a striking result would deserve a comment from the authors.
There is none.
There is none.
But there is more. The full table reveals a very low p-value for Hypertension, while the values in the NONE and the HCQ are significantly different.

It means the authors were not able to match the control group as far as hypertension is concerned, which is VERY UNEXPECTED; considering that the PSM group is N=3783 out of a N=81144 raw group.

How couldn’t the authors possibly achieve to match this very critical factor when they have a n=81144 group at their disposal ⁉️
Please note that it has the effect of worsening the control group, as hypertension is a critical risk factor for severe illness and mortality in COVID‐19.
onlinelibrary.wiley.com/doi/full/10.11…
onlinelibrary.wiley.com/doi/full/10.11…
👉 In other words, had the control group been properly matched, the PSM control group would exhibit better outcomes and the discrepancy with the HCQ group would be EVEN MORE STRIKING… but even more questionable.
Was it “tweaked” on purpose in order to soften the anomaly and avoid drawing too much attention?
Let’s sum up.
We’re in front of unprecedented, striking results which were obtained using a touchy statistical tool run on a gigantic, sparse data set exhibiting scarce, unreliable and vague, baseline severity indicators in the context of a known indication bias.
We’re in front of unprecedented, striking results which were obtained using a touchy statistical tool run on a gigantic, sparse data set exhibiting scarce, unreliable and vague, baseline severity indicators in the context of a known indication bias.
So either:
- HCQ alone at the lupus treatment dose yields in just 4 days twice to three times as many mechanical ventilation events,
OR:
- the study is flawed from the ground up and what we are seeing here is the effect of the infamous indication bias.
- HCQ alone at the lupus treatment dose yields in just 4 days twice to three times as many mechanical ventilation events,
OR:
- the study is flawed from the ground up and what we are seeing here is the effect of the infamous indication bias.

Honestly, I want to know.
And thankfully, it’s technically possible to clarify those uncertainties thanks to the Power of ©SurgiSphere!
And thankfully, it’s technically possible to clarify those uncertainties thanks to the Power of ©SurgiSphere!

Hey, @surgisphere, your raw data is available in open data, right? Personal records from all over the world. A public good.
You wouldn’t mind sharing it, would you?
Can you please provide us with it, along with the R code that was used to do the computations?
Thanks. 🙏
You wouldn’t mind sharing it, would you?
Can you please provide us with it, along with the R code that was used to do the computations?
Thanks. 🙏
☝️I actually meant to use that tweet here ⤵️