
Here I go, on another #Econometrics related thread.
Today, I want to talk about the "debate" related to health policies, economic growth and the 1918 Spanish flu.
Everything I have to say is here (with codes): pedrohcgs.github.io/posts/Spanish_…
Let's get to it!
1/n
Today, I want to talk about the "debate" related to health policies, economic growth and the 1918 Spanish flu.
Everything I have to say is here (with codes): pedrohcgs.github.io/posts/Spanish_…
Let's get to it!
1/n
Recently, Correia, Luck and Verner (2020) (CLV) put forward a very interesting paper that, among other things, analyze whether non-pharmaceutical interventions helped mitigate the adverse economic effects of the 1918 Spanish Flu pandemic on economic growth.
2/n
2/n
CLV find suggestive evidence that NPIs mitigate the adverse economic consequences of a pandemic.
Although today's society has a different structure from 100 years ago, these findings can help shape the current debate about covid policies.
3/n
Although today's society has a different structure from 100 years ago, these findings can help shape the current debate about covid policies.
3/n
However, not everyone bought their results. For example, Lilley, Lilley and Rinaldi (2020) (LLR) raised some valid points about CLV results not being "robustness", that their results could be driven by population growth between 1910 to 1917, before any NPIs were made.
4/n
4/n
There was a lot of exchanges between CLV and LLR, and, in my opinion, this is a win for science!!!
As an econometrician, however, I got super curious bout the methods used behind the scenes in the debate. This is where I jump in.
5/n
As an econometrician, however, I got super curious bout the methods used behind the scenes in the debate. This is where I jump in.
5/n
My main concerns were related to 1) the entire discussion was tied together with the linear TWFE regression specification, 2) treatment variables here are continuous, making this a non-standard DiD setup, and 3) inference procedures didn't account for multiple testing.
6/n
6/n
At the moment, we do not have a deep understanding of how we can interpret TWFE coefficients in these types of regressions if treatment effects are allowed to be heterogeneous.
We also do not really understand what are the assumptions being made here, too.
7/n
We also do not really understand what are the assumptions being made here, too.
7/n
So I decided to take an alternative route and discretize the treatment. I know this can be a sin, and I totally get it, but I wanted to map everything back to the more traditional DiD setup with binary treatment groups.
At least here, we know more about what is going on.
8/n
At least here, we know more about what is going on.
8/n
Now I can use some of my own work on DiD, too! More precisely, I can combine Sant'Anna and Zhao (2020) (SZ) Doubly-Robust DiD estimators with the methodology put forward in Callaway and Sant’Anna (2019) (CS) to handle DiD with multiple time periods.
9/n
9/n

Links for the papers are here:
Sant'Anna and Zhao (2020): arxiv.org/abs/1812.01723
Callaway and Sant'Anna (2020, new version coming soon): papers.ssrn.com/sol3/papers.cf…
Estimand is not hard to understand: simple combination of regression and propensity scores!
10/n
Sant'Anna and Zhao (2020): arxiv.org/abs/1812.01723
Callaway and Sant'Anna (2020, new version coming soon): papers.ssrn.com/sol3/papers.cf…
Estimand is not hard to understand: simple combination of regression and propensity scores!
10/n
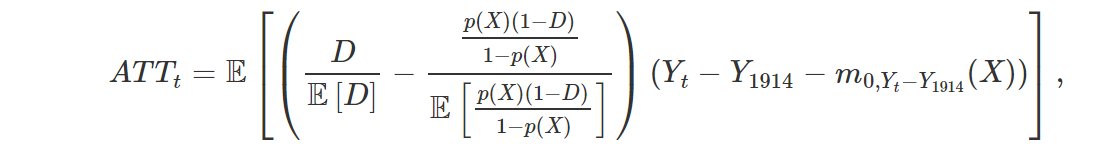
To implement it, I use the covariates considered by CLV and added log population in 1900. This is what CLV did in response to LLR concerns about pop. growt.
Results are below. Black and red lines are 90% pointwise and simultaneous confidence intervals, respectively.
11/n
Results are below. Black and red lines are 90% pointwise and simultaneous confidence intervals, respectively.
11/n

These results provide suggestive evidence that cities who were "more" aggressive/faster (above median) in terms of NPI did not perform worse than those who were less aggressive/faster (below median). In fact, there is some evidence that they can perform better!
12/n
12/n
Now, it is possible that some cities are considered "treated" when we consider NPI internsity, but "comparison" group if we consider NPI speed. This is can be bit odd.
13/n
13/n
Thus, I redefined a city to be "treated" if it is above the median in both NPI measures, and "comparison" if it is below the median in both NPI measures.
Six cities were therefore dropped: Albany, Denver, Indianapolis, Nashville, New Orleans and Rochester.
14/n
Six cities were therefore dropped: Albany, Denver, Indianapolis, Nashville, New Orleans and Rochester.
14/n
Results for post-treatment periods are still similar.
15/n
15/n

The picture about pre-trends here is more complicated, especially if one puts more attention to 1899 and 1904.
Although results do not find any evidence against pre-trends here, this may be because test has little power. At the end of the day, we have 37 observations!
16/n
Although results do not find any evidence against pre-trends here, this may be because test has little power. At the end of the day, we have 37 observations!
16/n
Although this is a totally legit concern, this type of pre-trends analysis comes full of caveats.
1) zero pre-trends are not necessary nor suffient for identification if we use SZ-CS procedure.
2) "post" pre-treatment periods: 1900, 1910, 1914 and 1917. This can be odd.
17/n
1) zero pre-trends are not necessary nor suffient for identification if we use SZ-CS procedure.
2) "post" pre-treatment periods: 1900, 1910, 1914 and 1917. This can be odd.
17/n
Personally, I tend to not put much emphasis on the "very early" data points as they are more than 10 years before the "treatment" took place and that the structure of the U.S. economy and U.S. cities changed quickly around the turn of the 20th century. But you can disagree!
18/n
18/n
Ultimately, the "reliability" of the results here, which are in agreement with those originally reported by CLV, crucially depend on whether you buy the argument in favor of counterfactual parallel trends or not.
19/n
19/n
After reading all these exchanges and talking to some friends, I personally believe that conditional parallel trends is a plausible assumption here.
But again, this is a matter of *subjective* judgment, and reasonable people can disagree here.
20/n
But again, this is a matter of *subjective* judgment, and reasonable people can disagree here.
20/n
That's all I have!
Hope you enjoy reading this as much as I enjoyed writing it.
Again, the entire discussion can be found here: pedrohcgs.github.io/posts/Spanish_…
Take care!
21/21
Hope you enjoy reading this as much as I enjoyed writing it.
Again, the entire discussion can be found here: pedrohcgs.github.io/posts/Spanish_…
Take care!
21/21
Tagging CLV: @Ogoun @StephanLuck @EmilVerner
Tagging Andrew Lilley of LLR (couldn't find the others): @alil9145
Tagging Andrew Lilley of LLR (couldn't find the others): @alil9145


