
Associate Professor @EmoryEconomics | Econometrics | Causal Inference | Difference-in-Differences. Dad 5x
 We---Andrew Baker, Brant Callaway, @causalinf , @agoodmanbacon , and I--- are really happy with how it turned out.
We---Andrew Baker, Brant Callaway, @causalinf , @agoodmanbacon , and I--- are really happy with how it turned out. 4 big lessons:
4 big lessons: What do we do in the paper?
What do we do in the paper? We will cover a great deal of material, from the very basic to the more advanced topics.
We will cover a great deal of material, from the very basic to the more advanced topics. 
 We’ve noticed that, um, a few people have been asking about this:
We’ve noticed that, um, a few people have been asking about this:
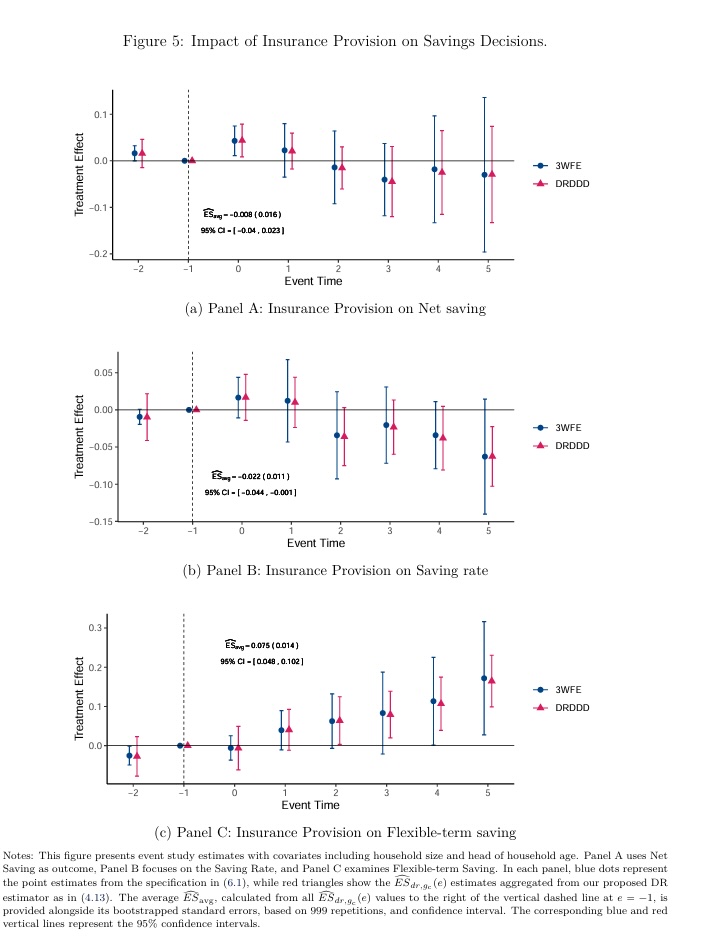
 Long-story-short: In setups where treatment timing is as-good-as-random, DiD procedures can leave "too much money on the table". We can get much more precise estimates!
Long-story-short: In setups where treatment timing is as-good-as-random, DiD procedures can leave "too much money on the table". We can get much more precise estimates! 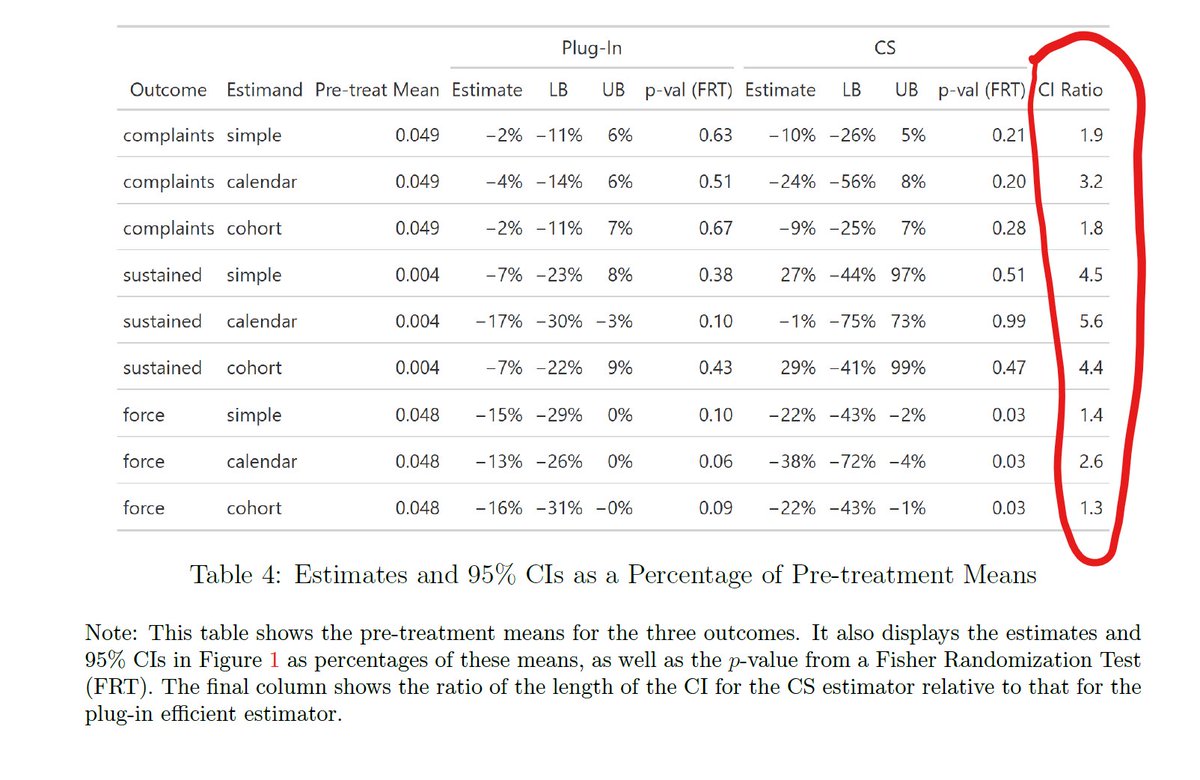
 Our main goal here is to explain how one can transparently use DiD procedures in setups with (a) multiple time periods, (b) variation in treatment timing (staggered adoption), and (c) when a parallel trends is plausible potentially only after conditioning on covariates.
Our main goal here is to explain how one can transparently use DiD procedures in setups with (a) multiple time periods, (b) variation in treatment timing (staggered adoption), and (c) when a parallel trends is plausible potentially only after conditioning on covariates.
 Before I go on, let me make it clear that everything that I say here or that we proposed in the paper can be easily implemented in #R via the package DRDID: pedrohcgs.github.io/DRDID/
Before I go on, let me make it clear that everything that I say here or that we proposed in the paper can be easily implemented in #R via the package DRDID: pedrohcgs.github.io/DRDID/
