
Ok this thread is for all you Stata junkies out there that use reshape regularly.
Sometimes I have to do “unbalanced” reshapes, which is a task that is super inefficient using the standard reshape command.
So here's a hack you might find useful!
1/
Sometimes I have to do “unbalanced” reshapes, which is a task that is super inefficient using the standard reshape command.
So here's a hack you might find useful!
1/
I often reshape panels from wide to long that have many missings.
E.g. I have a panel of scientists with a wide list of pubmed identifiers for their papers. (In this case, these came from space-delimited strings that I split into a wide set of variables with the stub “pmids")
2/
E.g. I have a panel of scientists with a wide list of pubmed identifiers for their papers. (In this case, these came from space-delimited strings that I split into a wide set of variables with the stub “pmids")
2/

I call this panel “unbalanced” because the distribution of publications for the sample of scientists is very skewed. 37% of them have only one published paper, but 0.15% have more than 200, a handful have more than 1000 papers. Mean is 7, median is 2.
3/
3/

That distribution is relevant for reshape, because most of the wide panel is just missings. And the number of missings is directly linked to the max width of the panel (scientist with the max number of papers). Increasing the max by 1 increases your number of missings by N-1
4/
4/
Usually we don’t care too much about missings for computation time, because stata largely ignores them. But look what happens when you try to reshape this panel to long. Stata holds on to the missings, and creates a ton of new data when it replicates your identifiers
5/
5/
In this example, I’ve restricted the panel to have a max width of just 19 papers. In the long shape, each name has 19 rows. Even though most of the pmids are missing, we have all this new data that stata created to identify each row with a name.
6/
6/

Usually the next step is to drop if pmids == “”. We don’t need those extra rows anyway, they’re just junk!
Especially when you’re identifying the data with names in a string type, that is a ton of useless data that stata is trying to carry around.
7/
Especially when you’re identifying the data with names in a string type, that is a ton of useless data that stata is trying to carry around.
7/
With a near-balanced panel, this exercise is not too costly for run time. But my dataset has upwards of 500,000 scientists with a max number of papers well over 1000. The more skewed the distribution is, the more reshape will slow down, and the time cost is exponential
8/
8/
I tried to do a standard reshape on a small subset of the data (21,000 names and a max number of papers about 1,000). It took 15 hours to run. So either you need a lot of parallel processing or you’re going to want a work-around.
9/
9/
So here’s the hack: You need to split up your data into groups of names that have the same number of papers and reshape them one at a time. The logic here is that you’re trying to minimize the number of useless rows that stata needs to create.
10/
10/
I wrote a loop that splits the data into groups with the same number of papers, then reshapes them one at a time.
The code is a little rough, and I had to deal with some issues like skipping groups that had no scientists. But you can get the gist from the screenshot.
/12
The code is a little rough, and I had to deal with some issues like skipping groups that had no scientists. But you can get the gist from the screenshot.
/12

So how much time does this hack save? I ran the standard reshape and the piecewise reshape on datasets where I’ve restricted the max width (number of papers). N mostly stays constant. Then I timed each routine.
/13
/13

As the width grows, reshape efficiency gets killed. The piecewise (hack) reshape routine is way faster and grows at a ~linear pace.
Like I said, with a width of 1000, the standard reshape is almost useless because stata is wasting so much time creating nuisance data.
/14
Like I said, with a width of 1000, the standard reshape is almost useless because stata is wasting so much time creating nuisance data.
/14
I think @Stata could easily augment the reshape command with a very simple option (maybe “unbalanced” or “dropmiss”) that speeds this up by ignoring the missings when it creates the long panel.
15/
15/
Unfortunately, I’m not a good enough programmer to ship you an .ado file that implements this work-around in a standard way. If stata users have other good ideas about how you would have worked around this differently, let me know!
16/
16/
BTW, Python can easily handle this problem (e.g. load the data as a .csv and use regular exp. to replace each comma with \n, id, and you’re pretty much there.)
Probably you #RStats evangelists will have 10 packages and/or a pithy (but unreadable) work-around of your own.
17/
Probably you #RStats evangelists will have 10 packages and/or a pithy (but unreadable) work-around of your own.
17/
Anyway, that was my day yesterday, so I thought you might be interested.
/end
/end
UPDATE!! Thanks to @_belenchavez for pointing me to the user-written package called sreshape. It is specifically designed to reshape quickly with missings and it appears to be super fast. (stata journal article: stata-journal.com/article.html?a…
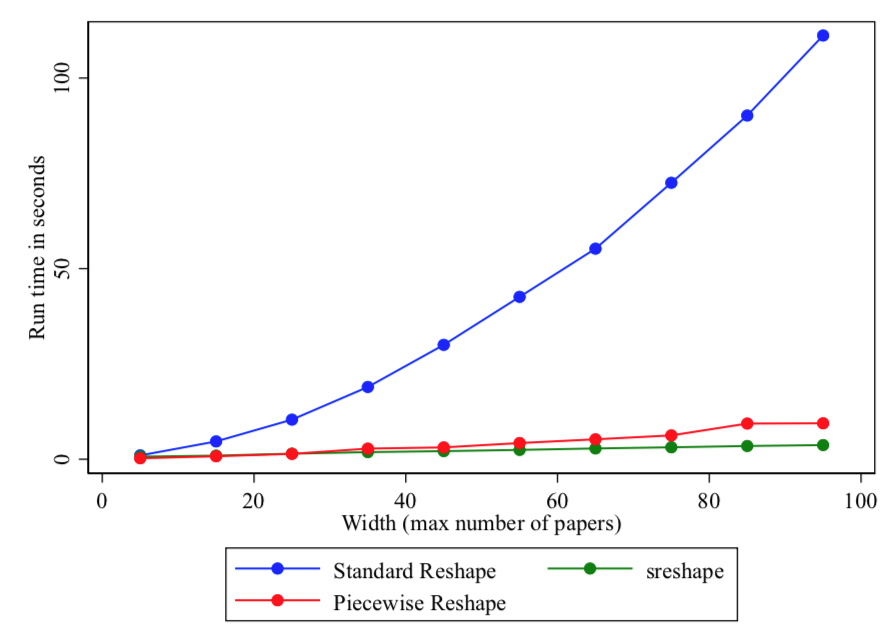
I added it to my test and you can see that it is definitely the fastest option. Search for sreshape from your stata window and click the link to install. Use the option missing(drop) to ignore the wide missing values. Thanks Kenneth L. Simmons for writing this up back in 2016!
• • •
Missing some Tweet in this thread? You can try to
force a refresh






