Inspired by @yoavgo 's poll, I looked at the views for papers in three tracks -- Ethics, Summarization, and Theme (69 papers in total).
The median views per paper was 104.
In these three tracks, the most-viewed papers at time of writing are ...
The median views per paper was 104.
In these three tracks, the most-viewed papers at time of writing are ...
https://twitter.com/yoavgo/status/1282087972553338880
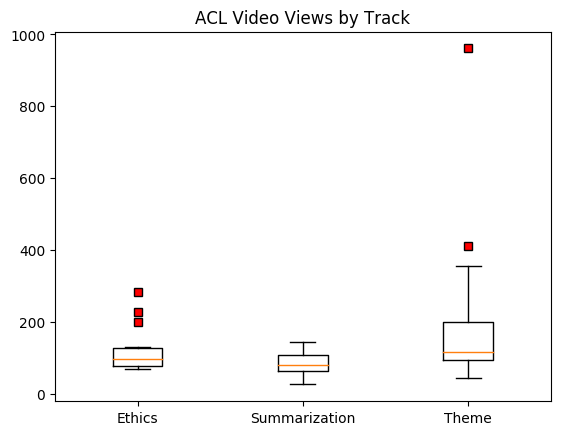
1. Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data by @emilymbender and @alkoller (961 views)
2. How Can We Accelerate Progress Towards Human-like Linguistic Generalization? by @tallinzen (410 views)
2. How Can We Accelerate Progress Towards Human-like Linguistic Generalization? by @tallinzen (410 views)
3. The Unstoppable Rise of Computational Linguistics in Deep Learning by @JamieBHenderson (356 views)
4. (Re)construing Meaning in NLP by @Sean_Trott @TorrentTiago @nancy_c_chang @complingy (291 views)
4. (Re)construing Meaning in NLP by @Sean_Trott @TorrentTiago @nancy_c_chang @complingy (291 views)
5. Language (Technology) is Power: A Critical Survey of "Bias" in NLP @sulin_blodgett @haldaume3 @s010n @hannawallach (283 views)
6. To Test Machine Comprehension, Start by Defining Comprehension @jdunietz @GregHBurnham Bharadwaj, @OwenRambow @jchucarroll Ferrucci (239 views)
6. To Test Machine Comprehension, Start by Defining Comprehension @jdunietz @GregHBurnham Bharadwaj, @OwenRambow @jchucarroll Ferrucci (239 views)
7. Social Bias Frames: Reasoning about Social and Power Implications of Language by @MaartenSap Saadia Gabriel, @Lianhuiq @jurafsky @nlpnoah @YejinChoinka (227 views)
• • •
Missing some Tweet in this thread? You can try to
force a refresh