
So an artist said online that “skill is important” in an assertive tone, coincidentally on the same day as a really cool hashtag on up and coming artist trying to get more followers is happening, and it made you mad/confused. Behold yet another long ass thread:
1/ Note: skip to #7 if you dont care to catch up on art twitter stuff!
First a quick recap. A frustrated professional saw conversations from the day before on pricing and commissions and dropped serious truth saying SOME artists aren’t getting noticed because of skill.
First a quick recap. A frustrated professional saw conversations from the day before on pricing and commissions and dropped serious truth saying SOME artists aren’t getting noticed because of skill.
2/ That’s not a mind blowing statement, for * some artist this is true. In fact, ALL of us have gone through that particular kind of introspection of where our skills were at any given time.
3/ However, this statement coincided with the start of a really good #NobodyArtistOb for those who wanted to grow their audiences. The hashtag had a lot of excellent up and coming talent, already working artists, and a lot of students who I’m excited to see their progress!
4/ The timing of each conversation created an odd flurry of misunderstandings, with good and bad faith discussions. On the artist’s part, she herself got crazy abuse which was completely unacceptable . I joined in, with a subtweet on the first post and got caught in the whirlwind
5/
However, seeing a lot of the conversations take place first hand, you get to dig past the anger and misunderstanding, and witness the real reason why this hits home for so many. A lack of opportunities and feeling helpless in an extraordinarily competitive industry.
However, seeing a lot of the conversations take place first hand, you get to dig past the anger and misunderstanding, and witness the real reason why this hits home for so many. A lack of opportunities and feeling helpless in an extraordinarily competitive industry.
6/Some folks just wanted to be angry. But others wanted answers to so many important questions. How do I gain followers? How do I get opportunities? All this skill talk, but how do I even know how to tell where I am?
7/ So I wish to dedicate a moment to try and answer some of these questions to the best if my ability, Note this isnt a definitive guide, or even an extensive one, just a basic starting point. Get ready for a lot of mf reading:
8/ Are followers important: 
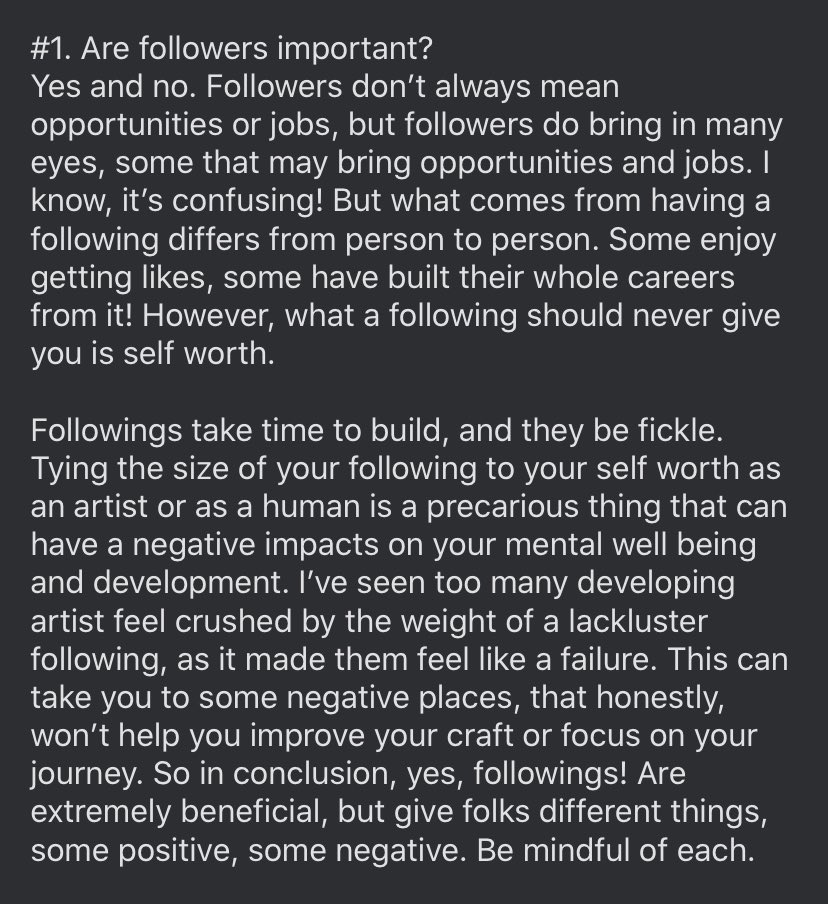
9/ How to gain a following:
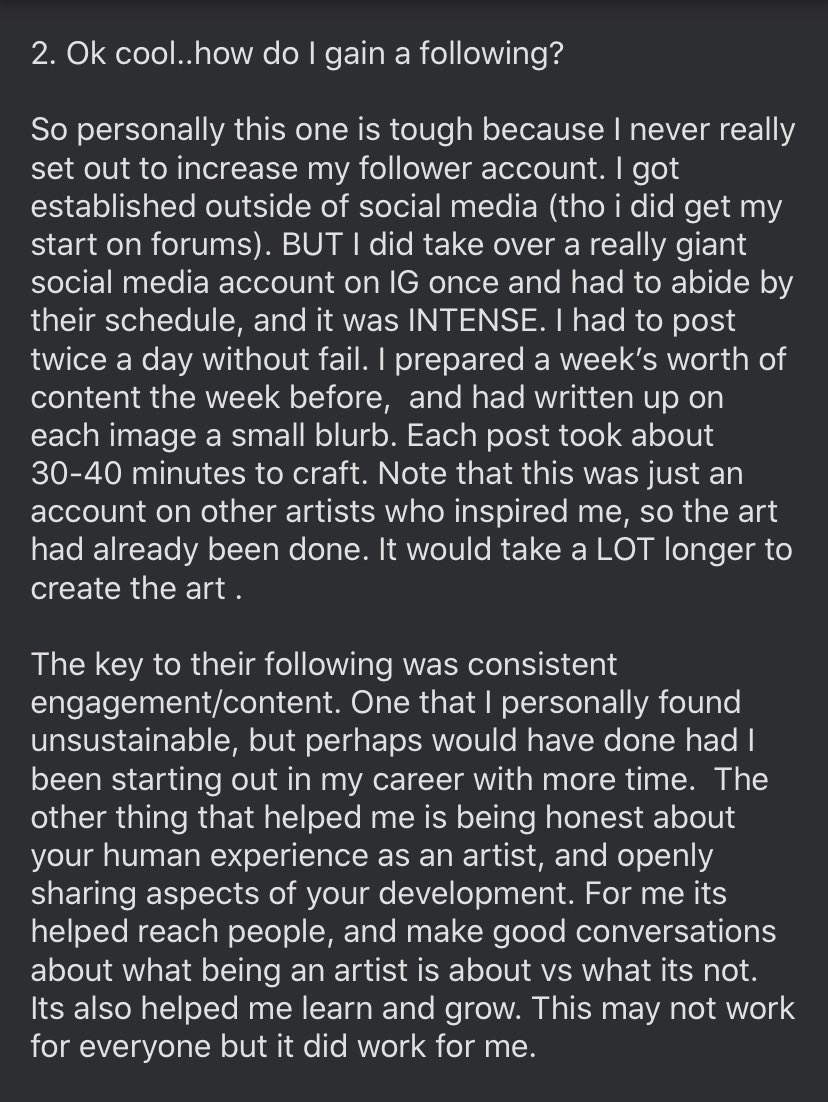
10/ What does skill have anything to do with this?
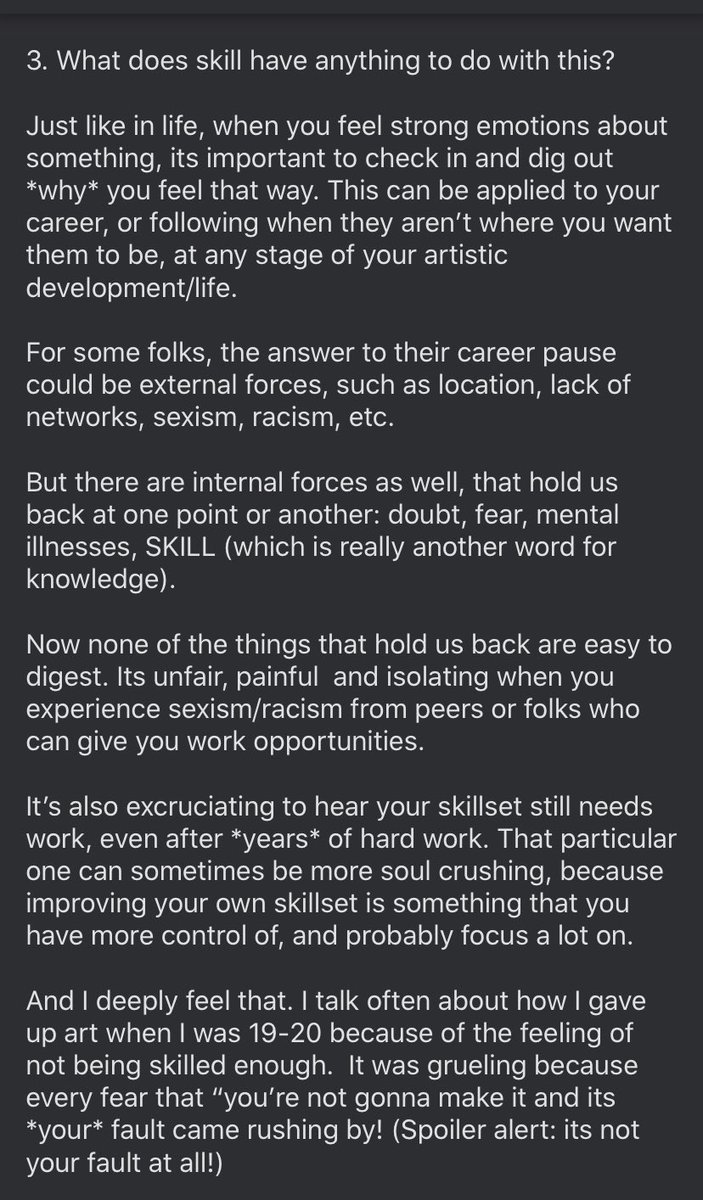

11/ What if I’m already skilled enough? Or wait, am I? How can I tell?
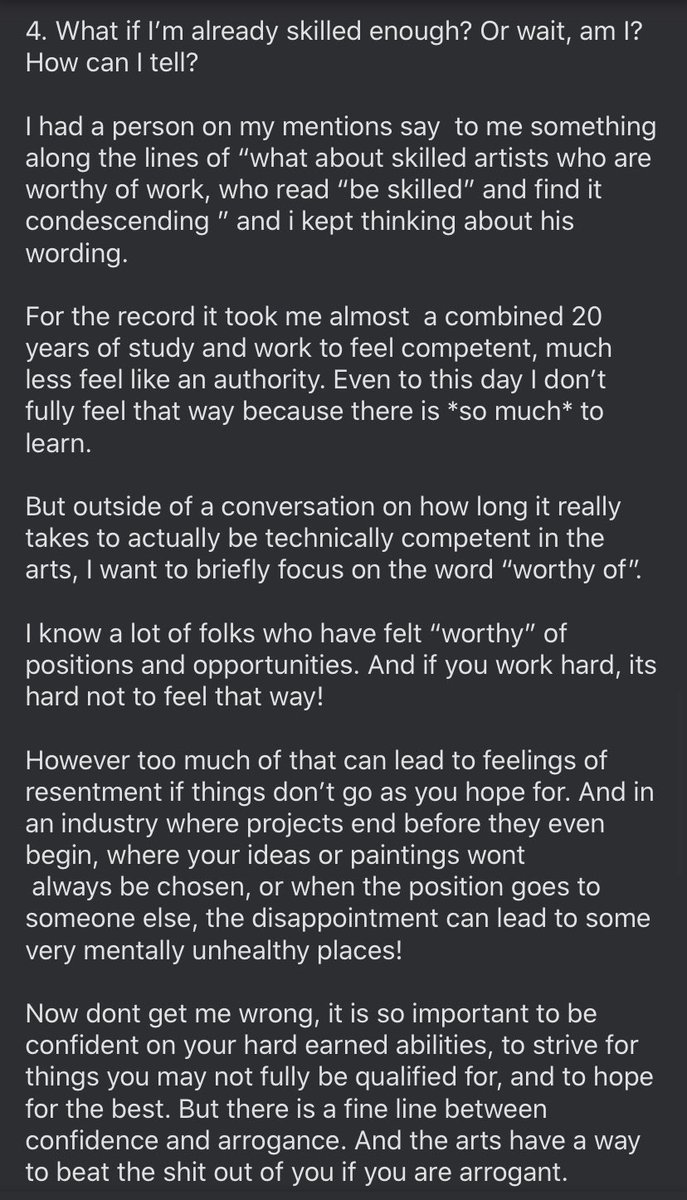

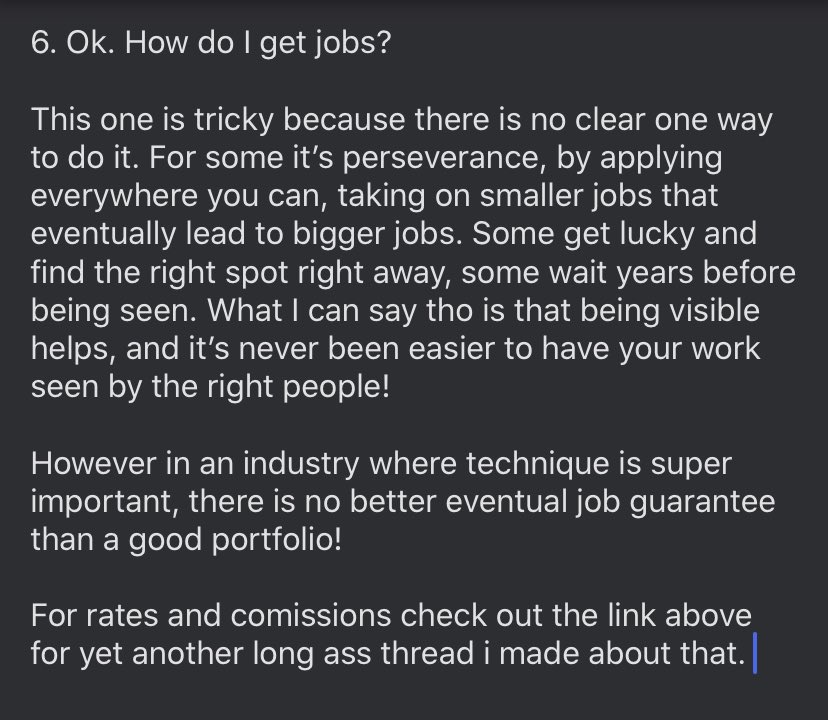
12/ How to get jobs:
Companion thread on Rates and Comissions:
Companion thread on Rates and Comissions:
https://twitter.com/kortizart/status/1282208106714238976?s=21
13/ Thats it. Some of the information that was missed and lost from days of anger on twitter dot com. To be fair this is a hellsite and we all know it ;) . But good things and conversations can and do come out of it!
Just please know that most artists, however fancy they-
Just please know that most artists, however fancy they-
14/ may seem, went through similar struggles and have walked the path you are on. You’re so welcome to disagree with their advice and thats fine too, but know that disagreement does not need to be coupled with abusive language. Even if that seems to be the way of this hellsite 😩
15/ Anyway thats all for now. I won’t be too responsive here because I got a ton of work to do, but I sincerely hope this was helpful. And it not, thats cool, ignore it and find your own way! :p
Either way take care y’alls and be safe! <3 .
Either way take care y’alls and be safe! <3 .
16/ typos include the wrong hashtag. Its #NobodyArtistClub . 🤦🏻♀️
I thrive in typos. I was forged by them. My brand is typos. My zodiac sign is typos with a rising of typos. I am typos personified. 😭
I thrive in typos. I was forged by them. My brand is typos. My zodiac sign is typos with a rising of typos. I am typos personified. 😭
• • •
Missing some Tweet in this thread? You can try to
force a refresh




















