
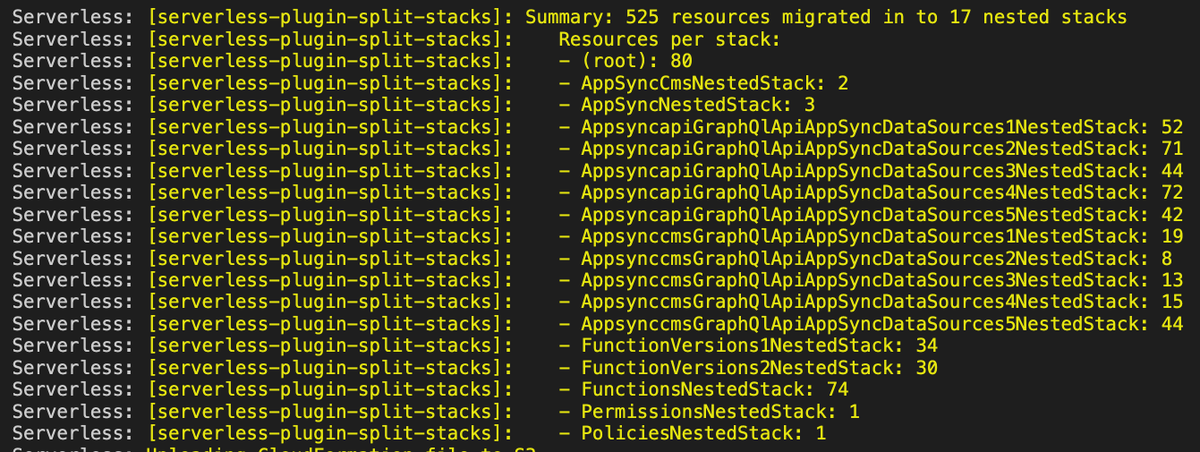
phew, spend a good few hours re-organizing a sizable AppSync project (150+ resolvers, ~600 resources), found a nice way to split them in the end, think now we've got some more room to grow this project 💪 here's the before and after for comparison #serverless #aws #appsync 


unfortunately, the solution wasn't to just "add more nested stacks" because you also reach the 60 parameters limit because the no. of different Lambda functions & DynamoDB tables involved
in the end, I had to find a way to slice along the data sources and pull everything up (DynamoDB tables/Lambda functions/log groups/IAM roles) and down (resolvers, function configurations, IAM roles) together
slicing it this way minimizes the no. of parameters, as each group of resources (centred around a data source) is as self-contained as possible, and then I can group them into nested stacks
btw, this work is already paying dividends as I added several queries and mutations to add a new feature the client wants and that pushed us over 600 resources! good to not have to worry about these CF limits for a while and focus on shipping features
• • •
Missing some Tweet in this thread? You can try to
force a refresh






