
"Finite Versus Infinite Neural Networks: an Empirical Study." arxiv.org/abs/2007.15801 This paper contains everything you ever wanted to know about infinite width networks, but didn't have the computational capacity to ask! Like really a lot of content. Let's dive in.
Infinite width Neural Network Gaussian Process (NNGP) and Neural Tangent Kernel (NTK) predictions can outperform finite networks, depending on architecture and training practices. For fully connected networks the infinite width limit reliably outperforms the finite network. 

The NNGP (corresponding to infinite width Bayesian networks) typically outperforms the NTK (corresponding to infinite width networks trained by gradient descent).

Centering and ensembling of finite width networks both lead to more kernel-like performance. Centering leads to faster training.


Large learning rates and L2 regularization both drive differences between finite networks and kernels, and lead finite width networks to perform better. The combined effect of large learning rates and L2 regularization is superlinear. (repeat figure image for this one)

L2 regularization unexpectedly works better for NTK-parameterized networks than for standard-parameterized networks. We emulate this with matching layerwise L2 regularization coefficients, leading to better generalization in standard-parameterized networks (ie, typical networks).

The generalization performance of certain finite width networks (especially CNNs without pooling) is non-monotonic in width, in a way not explained by double descent phenomena. (!?!)

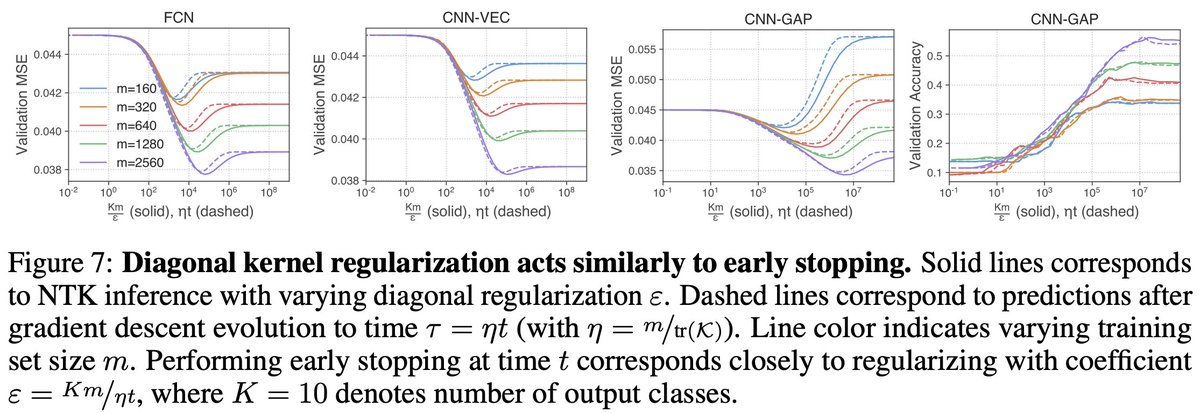
Diagonal regularization of kernel methods behaves like early stopping of training. There is a simple mapping between regularization strength and early stopping time (previously proposed in arxiv.org/abs/1810.10082).
Floating point precision determines the critical dataset size at which kernel methods will fail for numerical reasons. For CNNs with pooling, it's around 10^4 samples for float32.

Regularized ZCA whitening of input images improves model accuracy by a surprising amount, especially for infinite width NNGP and NTK predictions.

Equivariance is a commonly used to motivate the strong performance of CNNs. We show the property of equivariance is only (and can only be) beneficial for narrow networks far from the kernel regime.

Finally, we present a simple method for ensembling the predictions of NNGP and NTK models, making it practical to use data augmentation with infinite width networks. (data augmentation is otherwise impractical, due to the cubic dependence of kernel methods on dataset size)

All of these experiments were made possible by the Neural Tangents software library. You should use it for all your infinite width network needs! github.com/google/neural-…
This paper took an amazing amount of work by amazing collaborators. @hoonkp did the most, and @sschoenholz, Jeffrey Pennington, Ben Adlam, @Locchiu, and @ARomanNovak also all put in more than a usual paper's worth of effort.

