
Member of the technical staff @ Anthropic. Most (in)famous for inventing diffusion models. AI + physics + neuroscience + dynamics.
 No notes, just a talk outline.
No notes, just a talk outline. 

 Most work on AI misalignment risk is based on an assumption that more intelligent AI will also be more coherent. This is an assumption we can test! I collected subjective judgements of intelligence and coherence from colleagues in ML and neuro.
Most work on AI misalignment risk is based on an assumption that more intelligent AI will also be more coherent. This is an assumption we can test! I collected subjective judgements of intelligence and coherence from colleagues in ML and neuro. 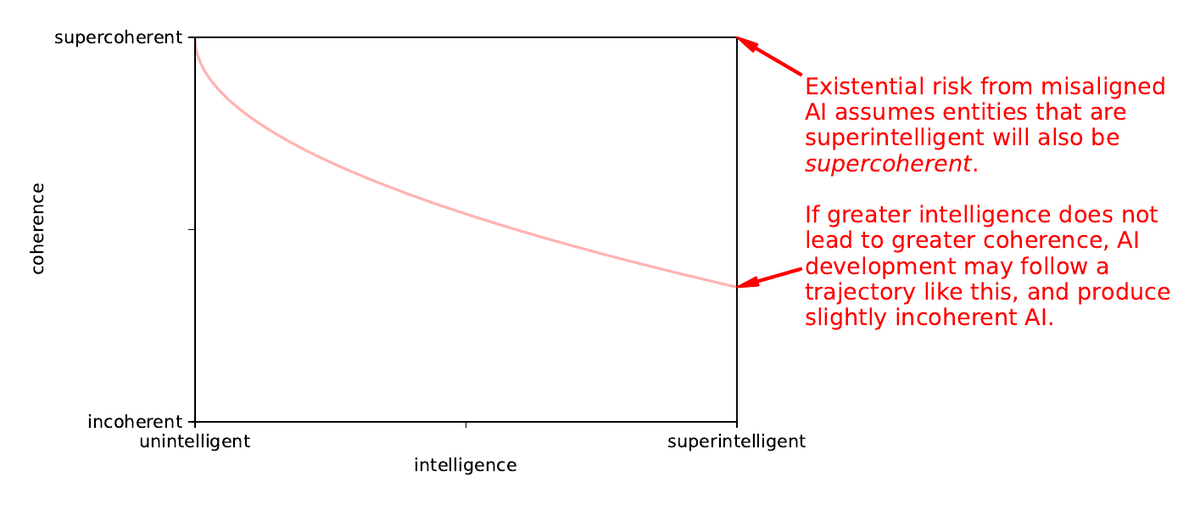
 If you are training models with < 5e8 parameters, for < 2e5 training steps, then with high probability this LEARNED OPTIMIZER will beat or match the tuned optimizer you are currently using, out of the box, with no hyperparameter tuning (!).
If you are training models with < 5e8 parameters, for < 2e5 training steps, then with high probability this LEARNED OPTIMIZER will beat or match the tuned optimizer you are currently using, out of the box, with no hyperparameter tuning (!).

 The phenomenon of overfitting in machine learning maps onto a class of failures that frequently happen in the broader world: in politics, economics, science, and beyond. Doing too well at targeting a proxy objective can make the thing you actually care about get much, much worse.
The phenomenon of overfitting in machine learning maps onto a class of failures that frequently happen in the broader world: in politics, economics, science, and beyond. Doing too well at targeting a proxy objective can make the thing you actually care about get much, much worse. 

 All accepted task submitters will be co-authors on the paper releasing the benchmark. Teams at Google and OpenAI will further evaluate BIG-Bench on their best-performing model architectures, across models spanning from tens of thousands through hundreds of billions of parameters.
All accepted task submitters will be co-authors on the paper releasing the benchmark. Teams at Google and OpenAI will further evaluate BIG-Bench on their best-performing model architectures, across models spanning from tens of thousands through hundreds of billions of parameters.
