
1/ Dagster has been public over a year. Last week we pushed out a new version that marks a new level of maturity for the project. We now call Dagster a data orchestrator. Here is a post about what we’ve built, learned, and principles we've developed:
medium.com/dagster-io/dag…
medium.com/dagster-io/dag…
2/ Over the past decade, there have been huge advances in data technology. Advanced computational runtimes and cloud data warehouses built on infinite, cheap storage and elastic compute are available to any organization with the right tools and sufficient resources.
3/ We believe the primary challenges today are higher in the stack and are abstraction and tooling problems. Data computations are hard to test, slow to build, disorganized, and under-abstracted. Uncontrolled complexity is the norm. Their needs are not met by the ecosystem today.
4/ This state of affairs is why Dagster exists, which we first discussed publicly a year ago. (medium.com/dagster-io/int…).
5/ We believe in the concept of a data application, which unifies with a set of software practices, artifacts, and systems — such as ETL, ELT, and ML training — that have different historical roots but convergent needs and characteristics
6/ We’ve developed a few principles around data applications over the past year. First: Acknowledge and manage complexity. These things are hard. The complexity cannot be wished away. Acknowledge it and manage with appropriate processes and abstractions
7/ Second: Embrace heterogeneity. Data tools and systems are heterogeneous. People with diverse skill sets, needs, and tool preferences build them. They are deployed to a wide range of infrastructure. This isn't going to change. Don't enforce homogeneity.
8/ Third: Data-aware orchestration. Typed data dependencies mean correct, testable, and understandable software. Linking computation to produced assets forms a critical base layer for data catalogs, data lineage, and self-service ops.
9/ We view Dagster as a new type of workflow engine, a data orchestrator. Workflow engines focus on pure execution concerns, like ordering computations. We make different tradeoffs. We structure, organize, and interrelate computations and assets.
10/ Dagster has new abstractions. Computations (nodes in the graph, called solids) are coarse-grained functions and connected with data dependencies. Inputs and outputs are typed. The type system is gradual and optional. This means more testable, reliable code.
11/ Dagster artifacts also have strongly typed, self-describing configuration, and a concept called resources that provide an abstraction between business logic and the surrounding environment. This makes computations more testable, reusable, and flexible.
12/ They also emit a stream of structured event metadata. This is an immutable record of all activity in you data system. They track operational data and materialized assets. This is the basis for powerful tooling and asset tracking.
13/ On top of all this is Dagit, our tool for both local development and production operations, built over our API. Here is a screenshot of it at work.
14/ Dagster is designed to integrate with domain-specific data tools. Integrations manage the mapping of those tools to our programming model. Integrations with tools like dbt, Papermill, and others have been developed by us and our partners.
15/ Papermill is a way to parametrize and execute notebooks as functions, for both testing and production. Here is a code example of the integration. This integration is one of many. 

16/ By integrating it into Dagster, it is accessible and understandable with our tools:
17/ Dagster is pluggable and can deploy to arbitrary infrastructure. We also provide prefabricated solutions for substrates like Kubernetes. This flexibility allows both varied development but also separate dev, test, and prod environments

18/ Our users have deployed in many configurations: on Kubernetes, on a custom PaaS, in an air-gapped data center over Dask, with Docker-in-Docker with isolated step execution. All with modern principles, like ephemeral compute resources.
19/ Dagster also have support for isolating team code from system code, and teams from each other, while sharing infrastructure. User pipelines and solids are queried and operated over a grpc interface.

20/ This means isolated environments (e.g. differing Python versions and dependencies), independent deployment schedules, better stability (user code cannot crash the system), and better collaboration between platform and data teams.
21/ Dagster computations are data-aware. Their inputs and outputs are typed, and they emit a structured stream of metadata events that track the creation and quality of data assets.
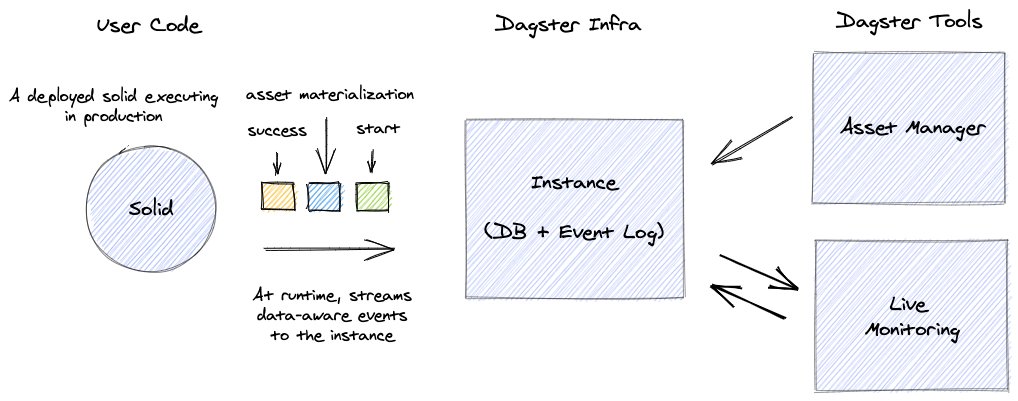
22/ Data-awareness has proved very valuable. Assets are linked to computation in verifiable ways. This forms a new base of information for data cataloging. We’ve also found it enables self-service ops and autonomy for data teams that think in terms of assets, not computations.
23/ We have found Dagster improves development and operations for full-stack data engineers/scientists as well as for data platform teams. Between increased productivity, reliability, testability, reuse, etc, our users are able to manage more complexity.
24/ This represents a new, more public phase of the project. The system is ready for more users and more use cases. More mature, much better docs, etc. We’re excited to grow our community. Join our slack! join.slack.com/t/dagster/shar…
25/ Please check out our docs. (docs.dagster.io) And we are fully open-source so check our repo (github.com/dagster-io/dag…). And we are hiring at Elementl elementl.com , the team behind Dagster :-)

