
Ahh damn it, I again didn't managed a super fast rambling video about Renoir vs. Tiger Lake.
So it's time for a picture thread with rambling, less than 30 minutes to go.
1/x
So it's time for a picture thread with rambling, less than 30 minutes to go.
1/x
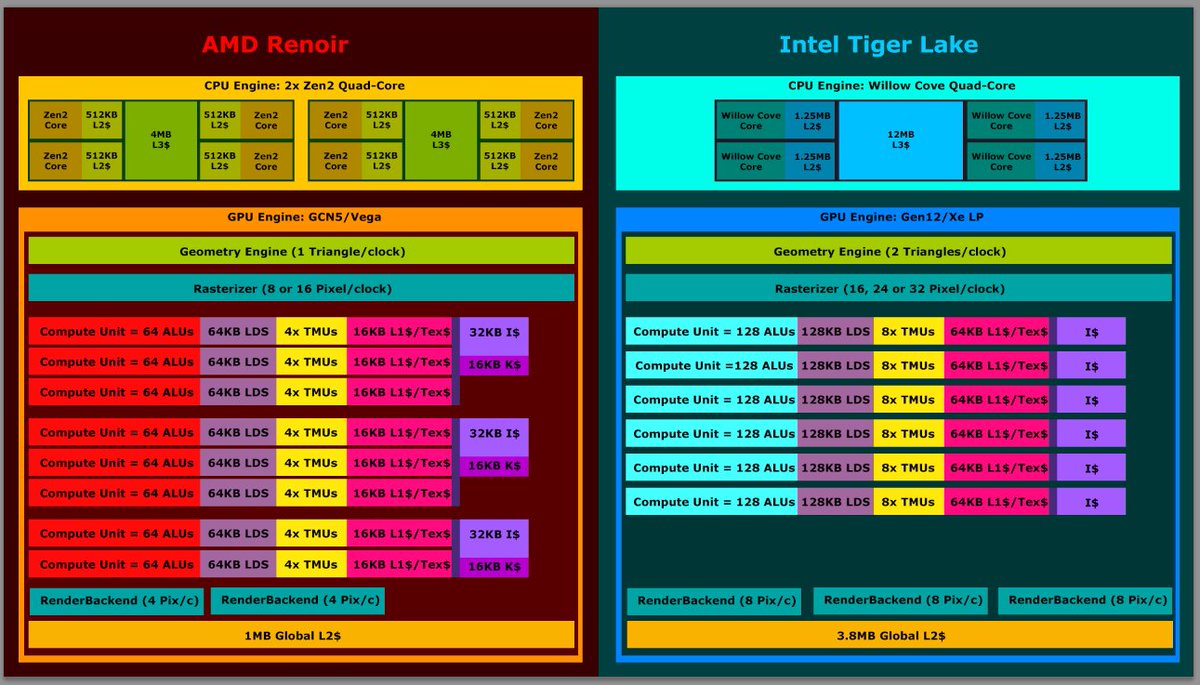
I really like the CPU engine from Intel.
Willow Cove has a massive amount of cache and should do over 20% better per clock than Renoir.
Under 15-30W I'm also sceptical how well the 8 cores on Renoir scale but the results are out there, I just didn't had the time to look.
2/x
Willow Cove has a massive amount of cache and should do over 20% better per clock than Renoir.
Under 15-30W I'm also sceptical how well the 8 cores on Renoir scale but the results are out there, I just didn't had the time to look.
2/x
IIRC some 3DMark results showed ~50% higher CPU scores on Renoir vs. Tiger Lake models but that would be totally okay.
For me the device will be mostly for browsing and some casual games, I rather take the better ST performance.
3/x
For me the device will be mostly for browsing and some casual games, I rather take the better ST performance.
3/x
Now a little look into some numbers.
4800U top Renoir vs. what's out there for i7-1185G7 as the top model(?).
Even with 8 cores on Renoir, Willow Cove has 25% more L2$.
5MiB total vs. 4MiB total.
And 50% more L3$, 12MiB vs. 2x4MiB (8 total).
4/x
4800U top Renoir vs. what's out there for i7-1185G7 as the top model(?).
Even with 8 cores on Renoir, Willow Cove has 25% more L2$.
5MiB total vs. 4MiB total.
And 50% more L3$, 12MiB vs. 2x4MiB (8 total).
4/x

That's great to keep more data local, it's one of the reasons why the performance per core is higher and also very important for the GPU.
Since both share the same system memory, the less needy the CPU is, the more effective bandwidth is available for the GPU.
5/x
Since both share the same system memory, the less needy the CPU is, the more effective bandwidth is available for the GPU.
5/x
To round it up on the CPU side, it also supports AVX512.
That's just a killer feature for every grandma and casual pleb out there.
Seriously, I'm happy that Intel increases the base for it. Skylake-X was just for a few high-end users, Cannon Lake was extreme low volume
6/x
That's just a killer feature for every grandma and casual pleb out there.
Seriously, I'm happy that Intel increases the base for it. Skylake-X was just for a few high-end users, Cannon Lake was extreme low volume
6/x
And Ice Lake was also still limited volume.
Tiger Lake should have a larger volume.
On AMD's side maybe not even Zen3 will support AVX512, but fingers crossed.
7/x
Tiger Lake should have a larger volume.
On AMD's side maybe not even Zen3 will support AVX512, but fingers crossed.
7/x
Now to some GPU details, that's where I like Xe LP quite more than Renoir GCN5 graphics.
The theoretical throughput from the rendering Front- and Backend wasn't increased by AMD since the first APU in 2011 with Llano.
1 Triangle per clock.
I think 16 pixels per clock...
8/x
The theoretical throughput from the rendering Front- and Backend wasn't increased by AMD since the first APU in 2011 with Llano.
1 Triangle per clock.
I think 16 pixels per clock...
8/x
Maybe AMD also has a reduced logic block which only does 8 pixel per clock but I believe it's 16 Pixels/clock as on the larger GPU designs.
But the rendering backend definitely can only output 8 Pixel/clock.
9/x
But the rendering backend definitely can only output 8 Pixel/clock.
9/x
Okay the live event is over and it's time to continue the rambling.
Intel throws more resources at the problem.
Xe LP in Tiger Lake can do 2 Triangles/clock and the render backend can output 24 Pixels/clock, that's a level above Renoir's theoretical capabilities.
10/x
Intel throws more resources at the problem.
Xe LP in Tiger Lake can do 2 Triangles/clock and the render backend can output 24 Pixels/clock, that's a level above Renoir's theoretical capabilities.
10/x
With three Renderbackends it also shows that Intel is not tying it to the memory controllers in a 1:1 fashion like Nvidia.
Now the question becomes what can the Raster-Engine deliver?
I guess at least 24 Pixel/clock otherwise Intel wouldn't have built such a wide backend.
11/x
Now the question becomes what can the Raster-Engine deliver?
I guess at least 24 Pixel/clock otherwise Intel wouldn't have built such a wide backend.
11/x
Time to look into the "shader cores".
Intel didn't unveiled all details, so there is further guesswork.
Since Intel doubled the amount of cores per sub slice I think that the Local Data Share (LDS) capacity was also doubled to 128KiB, Intel calls it Shared Local Memory (SLM)
12/x
Intel didn't unveiled all details, so there is further guesswork.
Since Intel doubled the amount of cores per sub slice I think that the Local Data Share (LDS) capacity was also doubled to 128KiB, Intel calls it Shared Local Memory (SLM)
12/x
The "core" to LDS ratio would be the same between GCN5 graphics and Xe LP, however the L1$/Tex$ capacity is effectivly twice as large on Xe vs. GCN5.
64KiB for 128 "cores" vs. 16KiB for 64 "cores".
Again more data local, higher practical performance possible.
13/x
64KiB for 128 "cores" vs. 16KiB for 64 "cores".
Again more data local, higher practical performance possible.
13/x
Another couple of nice details about the "core" design from Xe vs. GCN5 in Renoir.
Special Function Math/(EM = Extended Math) are done by seperate SIMD units.
SIMD4 on GCN, SIMD2 on Xe.
GCN5 can't co-execute, SFU operations have to run for 16 cycles, blocking the SIMD16 unit
14/x
Special Function Math/(EM = Extended Math) are done by seperate SIMD units.
SIMD4 on GCN, SIMD2 on Xe.
GCN5 can't co-execute, SFU operations have to run for 16 cycles, blocking the SIMD16 unit
14/x


Xe can co-execute, SFU/EM ops do not stall the main SIMD unit.
Since RDNA1 AMD can also co-execute main ops and SFU ops.
I suspect SFU ops are used rarely in applications but it's a small bonus point for Xe.
Another bonus point are dot product instructions...
15/x
Since RDNA1 AMD can also co-execute main ops and SFU ops.
I suspect SFU ops are used rarely in applications but it's a small bonus point for Xe.
Another bonus point are dot product instructions...
15/x
Xe in TGL has dot product instructions for 4x INT8 elements, which Intel also showcased in their live event, claiming 5x AI performance vs. the previous gen.
There was also a demonstration vs. 4800U where a photo filter was accelerated by such instructions.
16/x
There was also a demonstration vs. 4800U where a photo filter was accelerated by such instructions.
16/x
Vega20 was AMD's first GPU which included dot product ops for 4xINT8 and 8xINT4.
Navi12, Navi14 and Navi21 also support those instructions.
Renoir Vega or Navi10 do not.
But it's likely an area which will grow with WinML + DirectML in general applications and games.
17/x
Navi12, Navi14 and Navi21 also support those instructions.
Renoir Vega or Navi10 do not.
But it's likely an area which will grow with WinML + DirectML in general applications and games.
17/x

A missing detail about Xe's architecture was the execution model.
One cool feature from Intel's Gen graphics was a variable SIMD execution model.
Intel could use SIMD8, SIMD16 or SIMD32.
Depending on the code a narrow or wider workset is better.
Intel could adapt.
18/x
One cool feature from Intel's Gen graphics was a variable SIMD execution model.
Intel could use SIMD8, SIMD16 or SIMD32.
Depending on the code a narrow or wider workset is better.
Intel could adapt.
18/x
GCN always uses SIMD64 large wavefronts and a physical SIMD16 unit would execute one for 4 cycles.
Since RDNA1 AMD supports SIMD64 and SIMD32.
Nvidia uses a logical SIMD size of 32 elements, they called it a warp.
But what does Xe support and use?
19/x
Since RDNA1 AMD supports SIMD64 and SIMD32.
Nvidia uses a logical SIMD size of 32 elements, they called it a warp.
But what does Xe support and use?
19/x
Currently I suspect that the flexible SIMD size is still supported, which is a really nice feature if implementation costs are not too high because of it.
"Per core performance" should be good on Xe LP and Intel has 768 "cores" vs. 512 "cores" on Renoir.
20/x
"Per core performance" should be good on Xe LP and Intel has 768 "cores" vs. 512 "cores" on Renoir.
20/x
At 1.75GHz the 4800U has 1.792 FP32 TFLOPs, Core i7-1185G7 at 1.55GHz achieves ~33% higher theoretical throughput with 2.381 FP32 TFLOPs.
4700G desktop Renoir at 2.1 GHZ = 2.150 FP32 TFLOPs.
Obviously you need something to feed the engine otherwise iGPU perf won't scale.
21/x
4700G desktop Renoir at 2.1 GHZ = 2.150 FP32 TFLOPs.
Obviously you need something to feed the engine otherwise iGPU perf won't scale.
21/x
The CPU has large caches that helps, since it reduces pressure from that side on system memory bandwidth.
Xe LP has effectively per "core" twice as much L1$/Tex$.
And a large bonus is the L2$ on the GPU side.
Xe has 3.8MB L2$, Renoir just 1MB.
22/x
Xe LP has effectively per "core" twice as much L1$/Tex$.
And a large bonus is the L2$ on the GPU side.
Xe has 3.8MB L2$, Renoir just 1MB.
22/x
So even if we take 50% more "cores" into account on Xe vs. Renoir, the L2$ capacity would still be over twice as much vs. Renoir.
Intel had spent a lot of area because DDR4-3200 is the maximum speed or LPDDR4X with up to 4266.
With large caches Intel gets perf scaling
23/x
Intel had spent a lot of area because DDR4-3200 is the maximum speed or LPDDR4X with up to 4266.
With large caches Intel gets perf scaling
23/x
And vs. the 4800U if you would trust Intel, the Xe LP has 53% higher FPS in Codemasters racing game.
In Gears Tactics a snapshot showed 87% better perf though I'm not sure if Variable Rate Shading was used.
iirc vrs tier 1 showed artifacts on the blue lines, not in this ...
24/x
In Gears Tactics a snapshot showed 87% better perf though I'm not sure if Variable Rate Shading was used.
iirc vrs tier 1 showed artifacts on the blue lines, not in this ...
24/x


snapshot from the livestream.
Currently 40% better GPU perf vs. Renoir is what I expect in many games.
I would say now the game is "fair".
7nm TSMC vs. 10nm SF.
Haswell or Broadwell already won vs. Kaveri or Carrizo but Intel had a massive process advantage + eDRAM.
25/x
Currently 40% better GPU perf vs. Renoir is what I expect in many games.
I would say now the game is "fair".
7nm TSMC vs. 10nm SF.
Haswell or Broadwell already won vs. Kaveri or Carrizo but Intel had a massive process advantage + eDRAM.
25/x
Intel is not yet on the dGPU market but integrated graphics is now lead by Intel.
Cezanne will again use 512 Cores with GCN5, Van Gogh RDNA2 with Zen2 cores.
It's a weird mix where Intel will win on one or the other front.
26/x
Cezanne will again use 512 Cores with GCN5, Van Gogh RDNA2 with Zen2 cores.
It's a weird mix where Intel will win on one or the other front.
26/x
I'm not done yet abusing Twitter as a blog.
Tiger Lake has AV1 decoding, Thunderbolt4, USB4 and PCIe4 for a SSD vs. Renoir which has no AV1 decoding, no Thunderbolt4, no USB4 and only PCIe3 to external devices.
For me Tiger Lake is really the superior platform.
27/x
Tiger Lake has AV1 decoding, Thunderbolt4, USB4 and PCIe4 for a SSD vs. Renoir which has no AV1 decoding, no Thunderbolt4, no USB4 and only PCIe3 to external devices.
For me Tiger Lake is really the superior platform.
27/x
Last but not least a quick look into the chips.
Renoir's design is about 149.41mm² small, for TGL ~141mm² were floating around.
Zen2+512KB L2$ = 3.61mm²
Willow Cove + 1.25MB L2$ = 6.11mm² (+69% vs. Zen2).
Zen2 core = 2.8mm²
Willow Cove core ~ 4.53mm² (+62% vs Zen2)
28/x
Renoir's design is about 149.41mm² small, for TGL ~141mm² were floating around.
Zen2+512KB L2$ = 3.61mm²
Willow Cove + 1.25MB L2$ = 6.11mm² (+69% vs. Zen2).
Zen2 core = 2.8mm²
Willow Cove core ~ 4.53mm² (+62% vs Zen2)
28/x
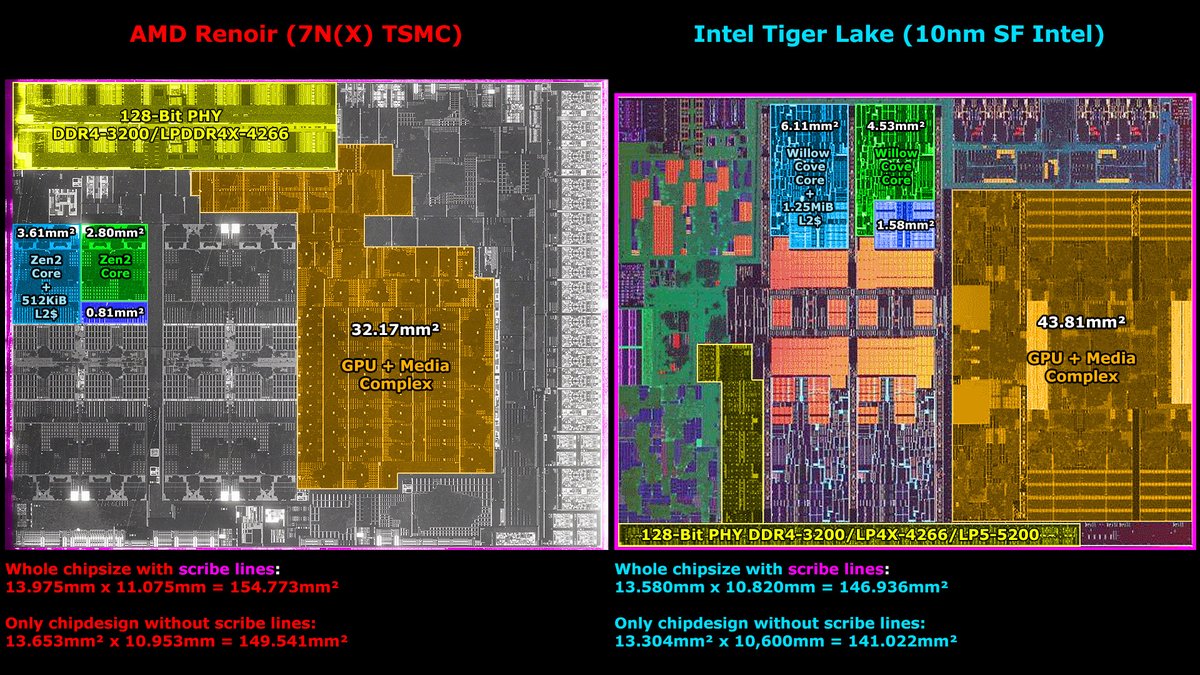
For TGLs whole chip size I took the width from @_rogame's calculation for TGL:
----
And yes Willow Cove is a big boi but higher performance per clock has to come from somewhere.
29/x
----
And yes Willow Cove is a big boi but higher performance per clock has to come from somewhere.
29/x
For the GPU complex+media area I based the estimates on @GPUsAreMagic annotation for Renoir:
32.17mm² for Renoir vs. 43.81mm² for Tiger Lake (+36%).
One glaring aspect is the PHY area for memory.
It's a massive portion on Renoir vs. TGL.
30/30
32.17mm² for Renoir vs. 43.81mm² for Tiger Lake (+36%).
One glaring aspect is the PHY area for memory.
It's a massive portion on Renoir vs. TGL.
30/30









