#Julia言語 コメント
T<:AbstractFloatについて
f(x::Vector{T})
g(x::AbstractVector{T})
h(x)
を sin(sum(x)) で定義すると、不動小数点数のベクトルxでのコンパイル結果は同じになります。
続く
Juliaでのジェネリクス的な関数の書き方(Parametric Methods) qiita.com//honey32/items… #Qiita
T<:AbstractFloatについて
f(x::Vector{T})
g(x::AbstractVector{T})
h(x)
を sin(sum(x)) で定義すると、不動小数点数のベクトルxでのコンパイル結果は同じになります。
続く
Juliaでのジェネリクス的な関数の書き方(Parametric Methods) qiita.com//honey32/items… #Qiita


#Julia言語 スクショのソースコードは
nbviewer.jupyter.org/gist/genkuroki…
にあります。スクショのコードを手で打ち込ませる行為はできるだけ避けたい。(数行までなら問題ないと思う。)
f(x::Vector) は g(::AbstractVector) や h(x) と違って、Vector型とは異なるベクトルのようなもの達に適用できない。続く
nbviewer.jupyter.org/gist/genkuroki…
にあります。スクショのコードを手で打ち込ませる行為はできるだけ避けたい。(数行までなら問題ないと思う。)
f(x::Vector) は g(::AbstractVector) や h(x) と違って、Vector型とは異なるベクトルのようなもの達に適用できない。続く


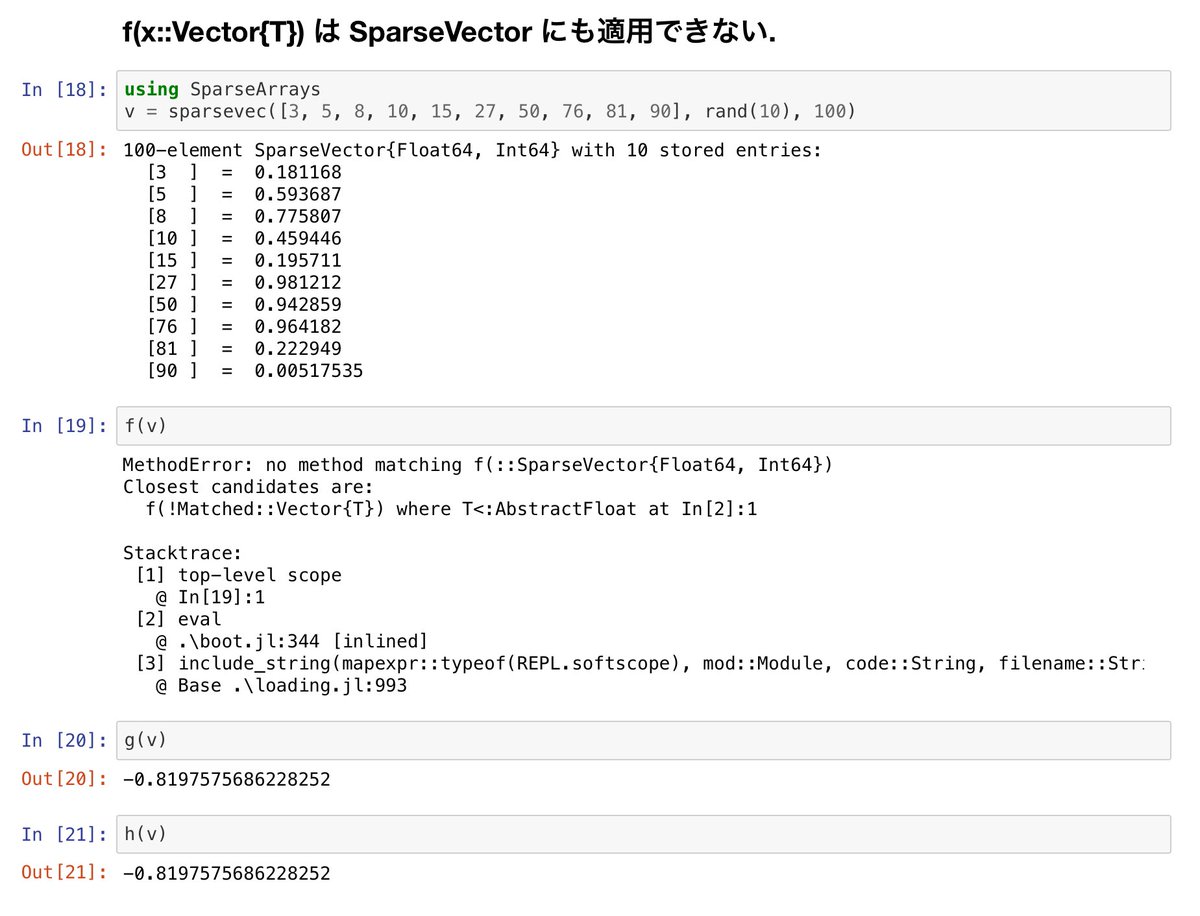
#Julia言語 Vectorではないベクトルのようなもの達全体で使える函数が欲しい場合には f(x::Vector) や f(x::Vector{T}) where T のような形式で函数を定義してはいけません。
そのように定義しても、コンパイル結果のネイティブコードは引数の型を指定しなかった場合と変わらない。
そのように定義しても、コンパイル結果のネイティブコードは引数の型を指定しなかった場合と変わらない。

#Julia言語 さらに、f(x::Vector) だけではなく、 g(x::AbstractVector) も Generator 達には適用できません。

#Julia言語 このように、引数の型を指定するごとに、引数の型を指定していなければ自然に適用可能だった場合が次々に適用不可能な場合になります。
ネイティブコードが同じになる場合には計算速度の改善も起こらない。
ネイティブコードが同じになる場合には計算速度の改善も起こらない。
#Julia言語 は函数に引数を与えたときに、その函数をコンパイルします。だから、Juliaのコンパイラは、函数の引数の型を宣言していない場合であっても、コンパイル時に引数の型を全て知っています。
Juliaでは「コンパイラにヒントを与えるために引数の型宣言を書く」という考え方は通用しません。
Juliaでは「コンパイラにヒントを与えるために引数の型宣言を書く」という考え方は通用しません。
#Julia言語 コンパイル時にコンパイラは函数の引数の具体的型を全て知っているので、
function f(x) ~ end
のように函数を書くときには、
引数xの具体的な型がすでに決まっている
という状況を想定して、「~」の部分にxの型から他の変数の型が自然に決まるようなコードを書きます。
function f(x) ~ end
のように函数を書くときには、
引数xの具体的な型がすでに決まっている
という状況を想定して、「~」の部分にxの型から他の変数の型が自然に決まるようなコードを書きます。
#Julia言語 xが不動小数点数の配列のようなもののとき、
s =sum(x)
の値の型はxの成分の型になります。 sが不動小数点のとき
y = sin(s)
の値の型は s の型に等しくなる。
こういう感じで引数 x の型から他の諸々のモノの型が自動的に決まって行く。
s =sum(x)
の値の型はxの成分の型になります。 sが不動小数点のとき
y = sin(s)
の値の型は s の型に等しくなる。
こういう感じで引数 x の型から他の諸々のモノの型が自動的に決まって行く。
#Julia言語 そういう型の伝搬がうまく行きそうな場合には、引数の型の制限をできるだけ除いた方が、適用可能な範囲の広い函数ができあがります。
そのようなスタイル(函数の引数の型宣言を書かないことが多いというスタイル)で書いても、速度的な劣化が起こらない点がJuliaの面白い点だと思います。
そのようなスタイル(函数の引数の型宣言を書かないことが多いというスタイル)で書いても、速度的な劣化が起こらない点がJuliaの面白い点だと思います。
#Julia言語 Juliaによる型推論の様子は
@ code_warntype f(rand(10))
のようにして見ることができます。@ の後の空白は除く。
これの確認はほぼ必須に近い。
あと、@ timeで実行時間とメモリ割当も確認することが多い。
小さな函数を書く
→テスト
→@ code_warntypeや@ timeも確認
@ code_warntype f(rand(10))
のようにして見ることができます。@ の後の空白は除く。
これの確認はほぼ必須に近い。
あと、@ timeで実行時間とメモリ割当も確認することが多い。
小さな函数を書く
→テスト
→@ code_warntypeや@ timeも確認
#Julia言語
小さな函数を書く
→テスト
→@ code_warntypeや@ timeも確認
(BenchmarkToolsやjulia --track-allocation=userなども使用)
の繰り返しになるので、REPLやJupyter notebookなどのインタラクティブな環境にどっぷりつかることは必須だと思う。
小さな函数を書く
→テスト
→@ code_warntypeや@ timeも確認
(BenchmarkToolsやjulia --track-allocation=userなども使用)
の繰り返しになるので、REPLやJupyter notebookなどのインタラクティブな環境にどっぷりつかることは必須だと思う。
#Julia言語 Juliaでは「コンパイラにヒントを与えるために函数の引数の型注釈を書く」ことが無用になっています。
函数の引数の型注釈は純粋にdispatchのために利用されます。
同じ名前の函数であっても、引数の型の組み合わせが異なれば、別のコードが実行されるようにできる。
函数の引数の型注釈は純粋にdispatchのために利用されます。
同じ名前の函数であっても、引数の型の組み合わせが異なれば、別のコードが実行されるようにできる。
#Julia言語 multiple dispatchはJuliaの最大の特徴なので、「コンパイラの最適化の効率を上げるために函数の引数の型注釈を書く」のような類の考え方はJuliaにおいては最大のナンセンスだと思います。
「函数の引数の型指定はmultiple dispatchのために行う」と理解しておく必要がある。
「函数の引数の型指定はmultiple dispatchのために行う」と理解しておく必要がある。
#Julia言語 multiple dispatchについては
juliaopt.org/meetings/santi…
The Unreasonable Effectiveness of Multiple Dispatch
Stefan Karpinski
2019
JuliaCon 2019
The Unreasonable Effectiveness of Multiple Dispatch
Stefan Karpinski
を参照。
juliaopt.org/meetings/santi…
The Unreasonable Effectiveness of Multiple Dispatch
Stefan Karpinski
2019
JuliaCon 2019
The Unreasonable Effectiveness of Multiple Dispatch
Stefan Karpinski
を参照。
• • •
Missing some Tweet in this thread? You can try to
force a refresh