
私については https://t.co/WbWjr95AmF と https://t.co/P7WOMn2ay1 と https://t.co/ouhJUcBE7E と https://t.co/Zzel9GBOCm を見て下さい。
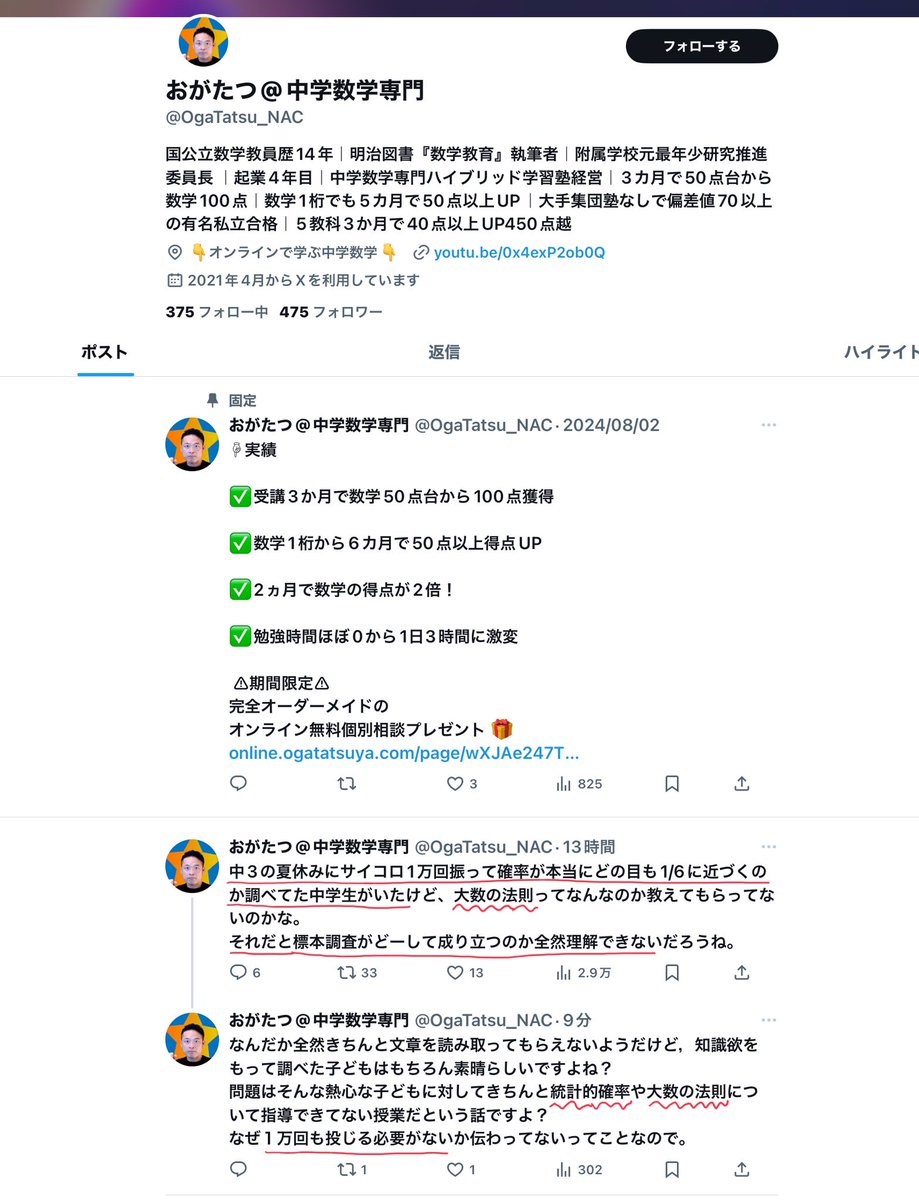 #統計 以下のリンク先の反応も理解していない側に分類されると私は思いました。
#統計 以下のリンク先の反応も理解していない側に分類されると私は思いました。
 #統計 「違いがない」の型の帰無仮説のP値をnull P値と呼びます。
#統計 「違いがない」の型の帰無仮説のP値をnull P値と呼びます。

 #統計 実際、natureの記事 nature.com/articles/d4158… ではcompati{ble,bility}が重要キーワードになっており、P値が
#統計 実際、natureの記事 nature.com/articles/d4158… ではcompati{ble,bility}が重要キーワードになっており、P値が



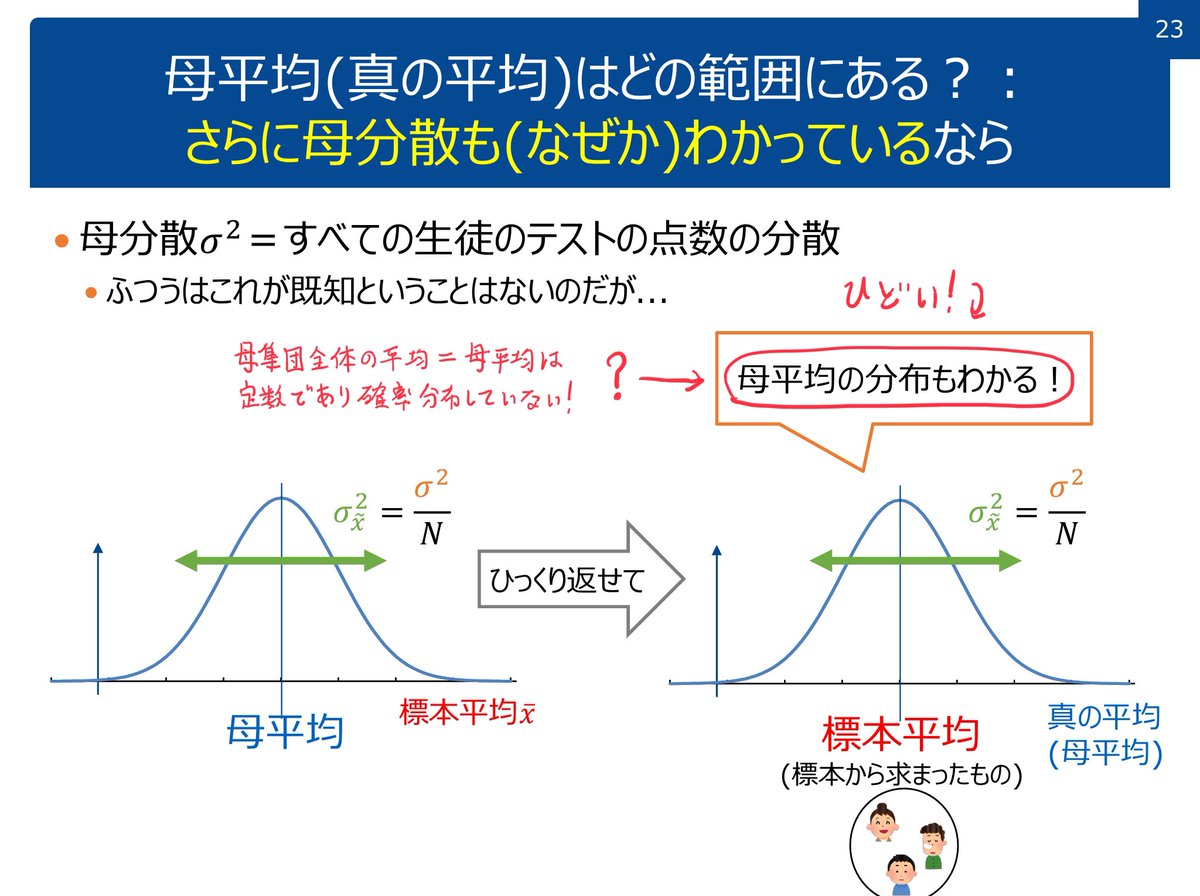
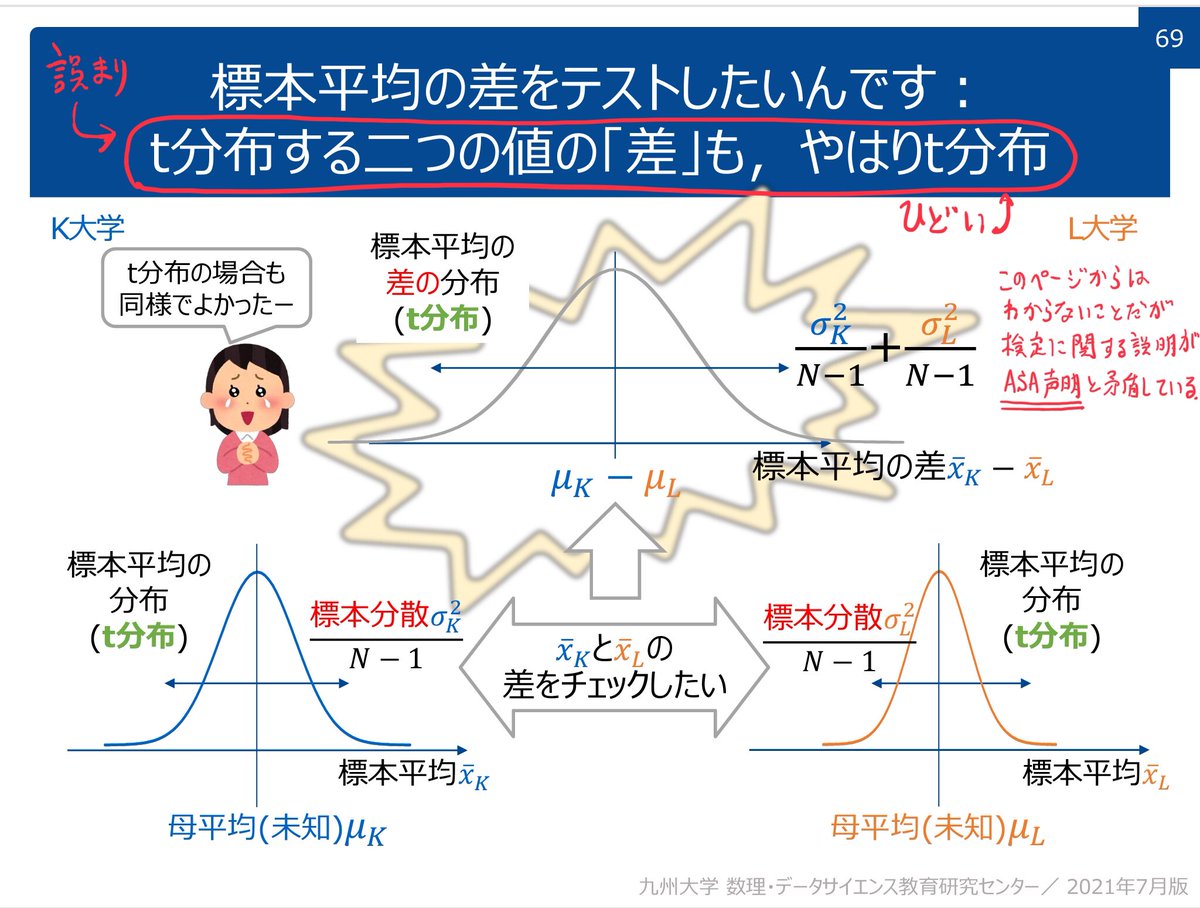
 #統計 P値や信頼区間に関するより現代的な知識は論文 journals.sagepub.com/doi/10.1177/02… で得られる。
#統計 P値や信頼区間に関するより現代的な知識は論文 journals.sagepub.com/doi/10.1177/02… で得られる。
 さらに冷えた。
さらに冷えた。 


