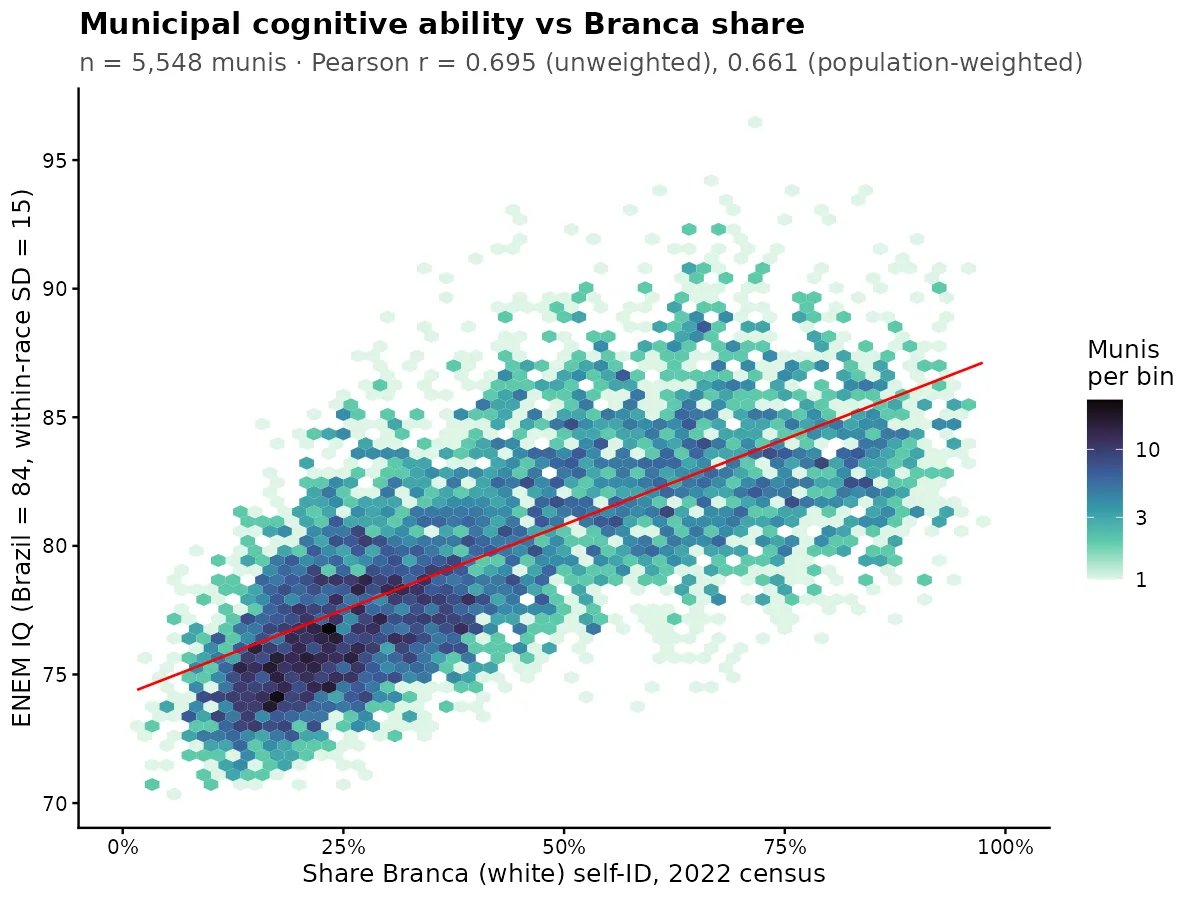
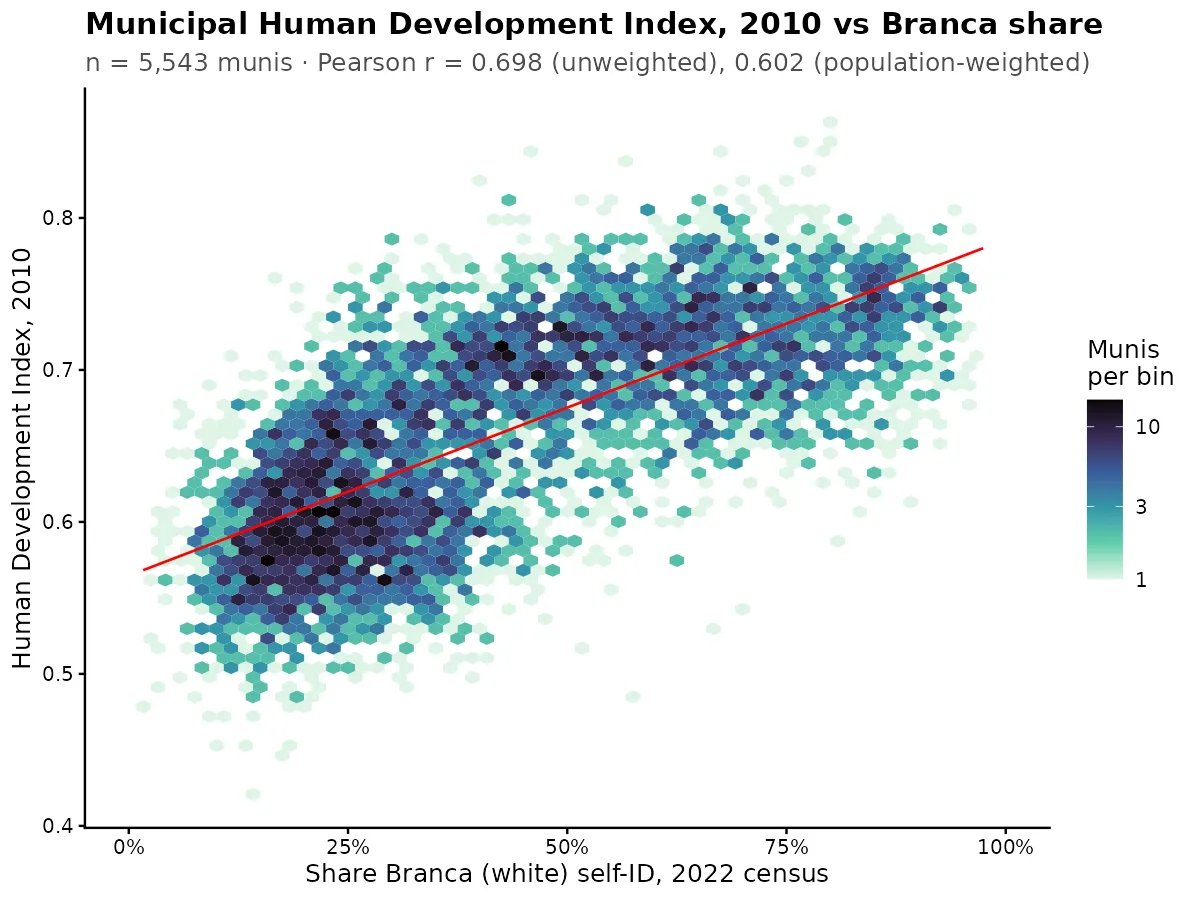
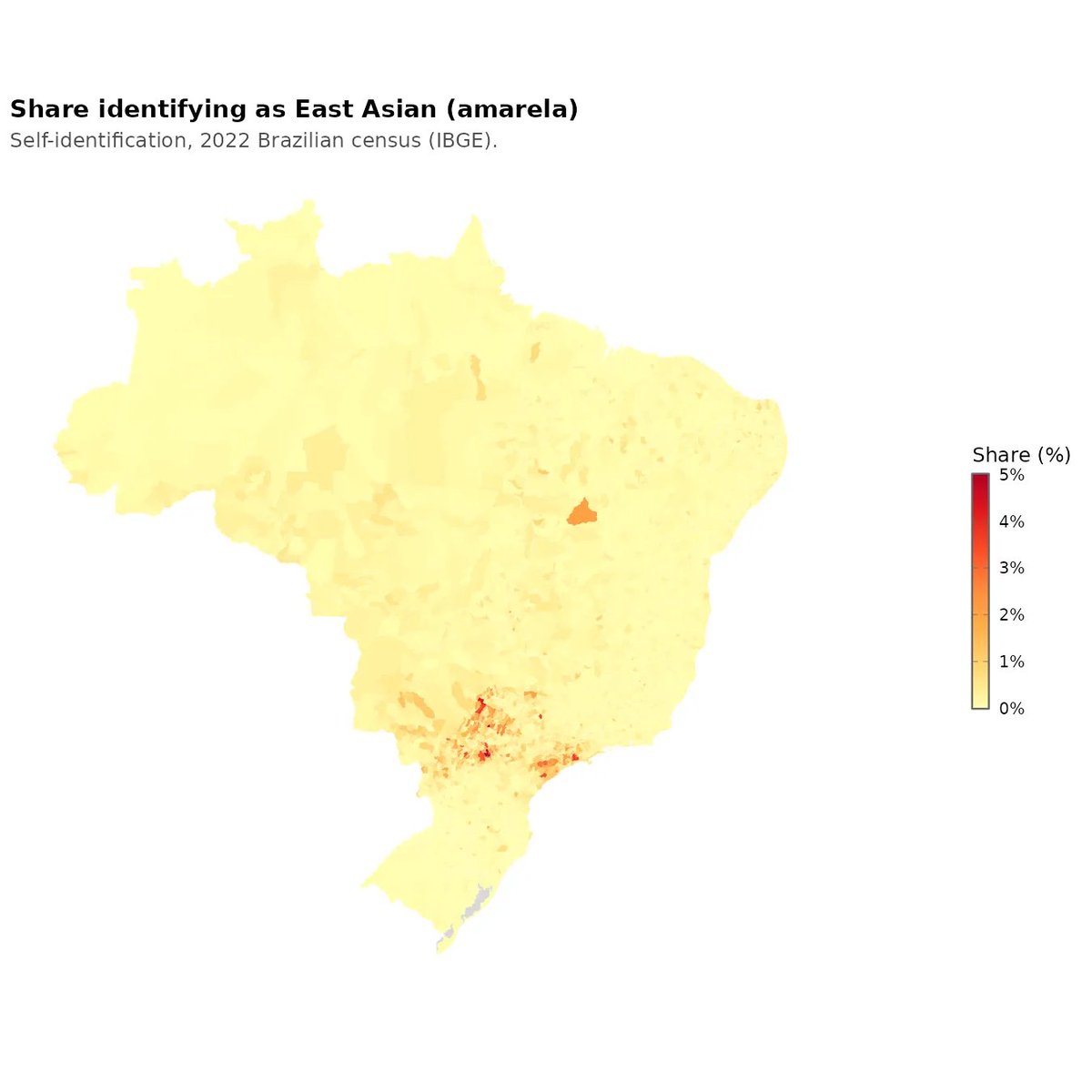
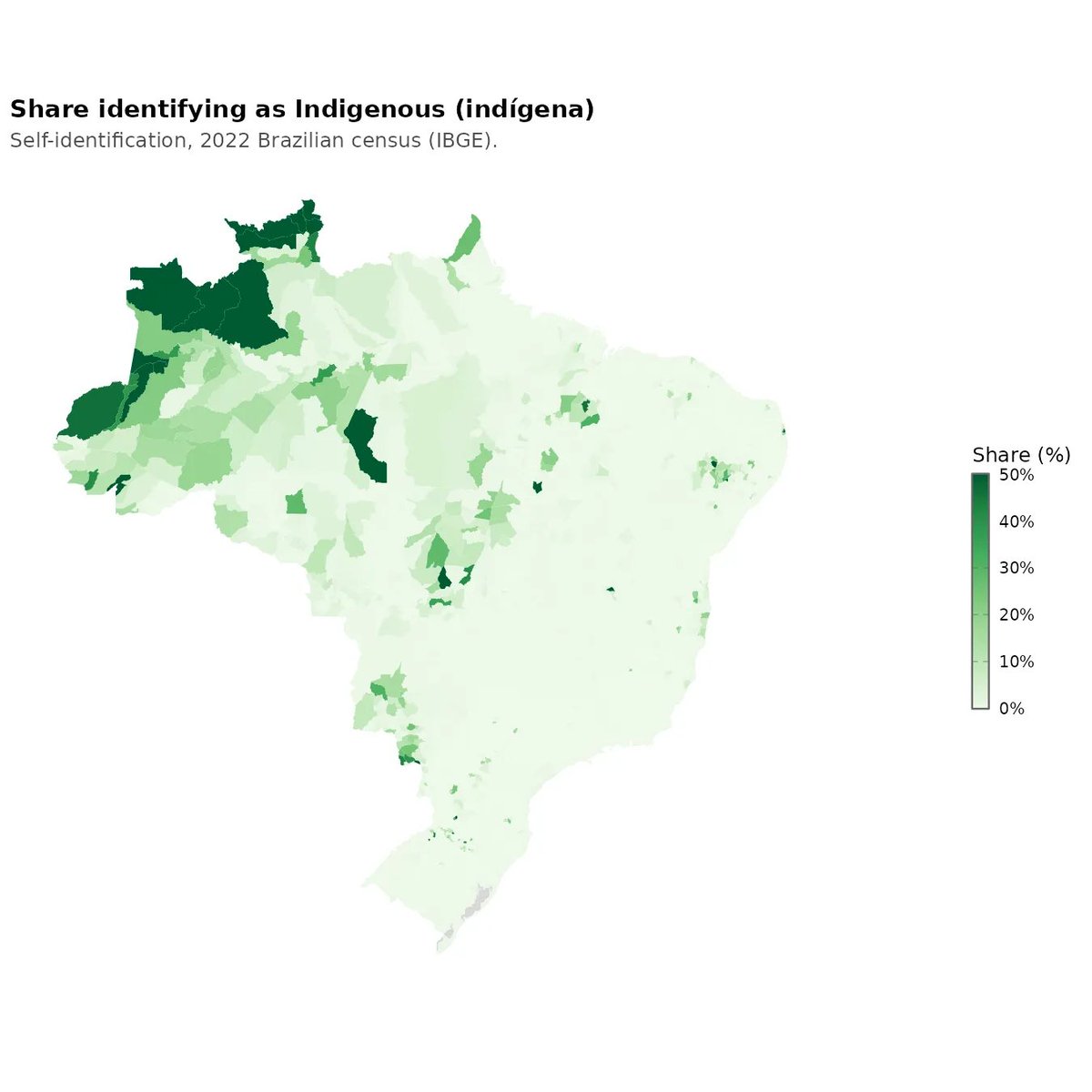
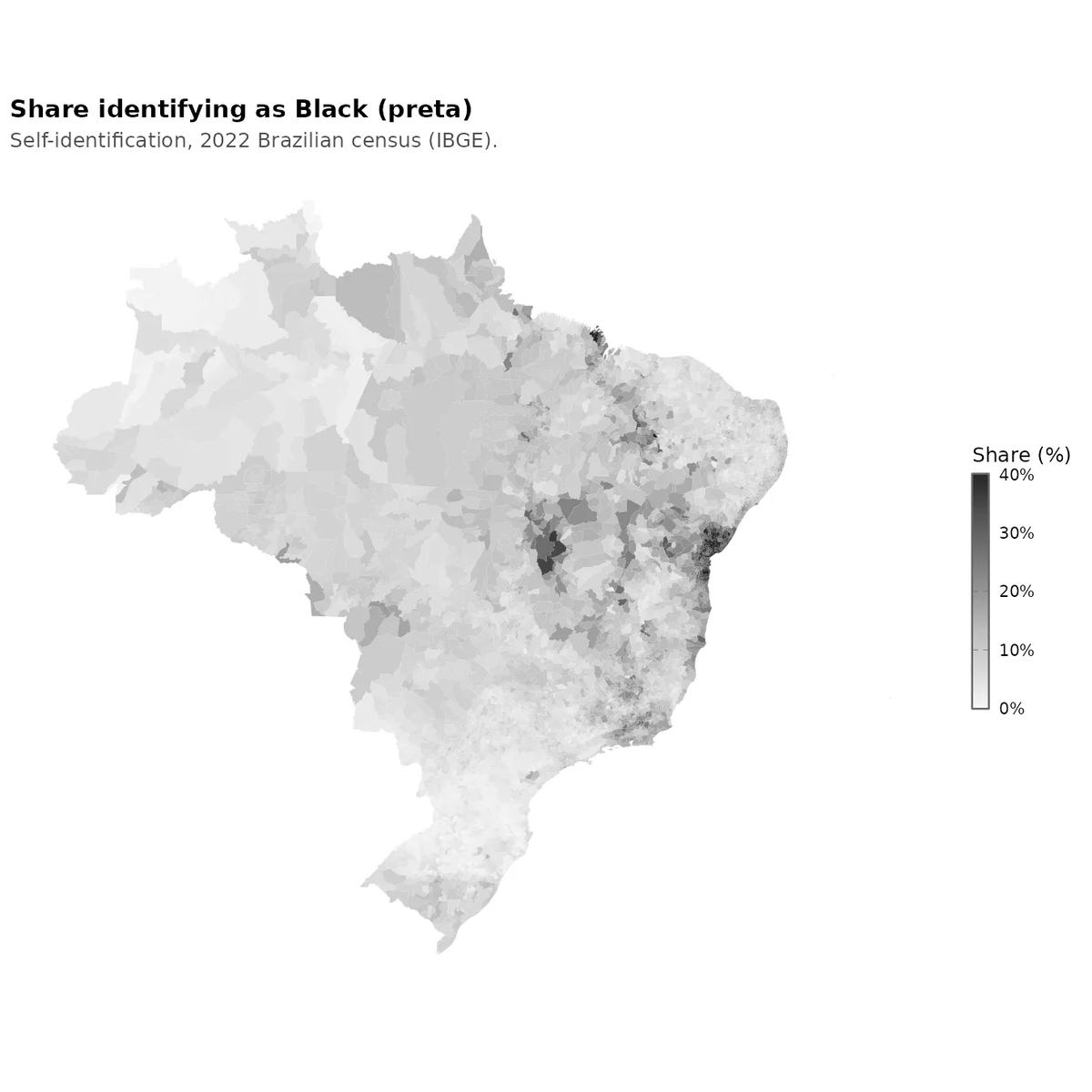
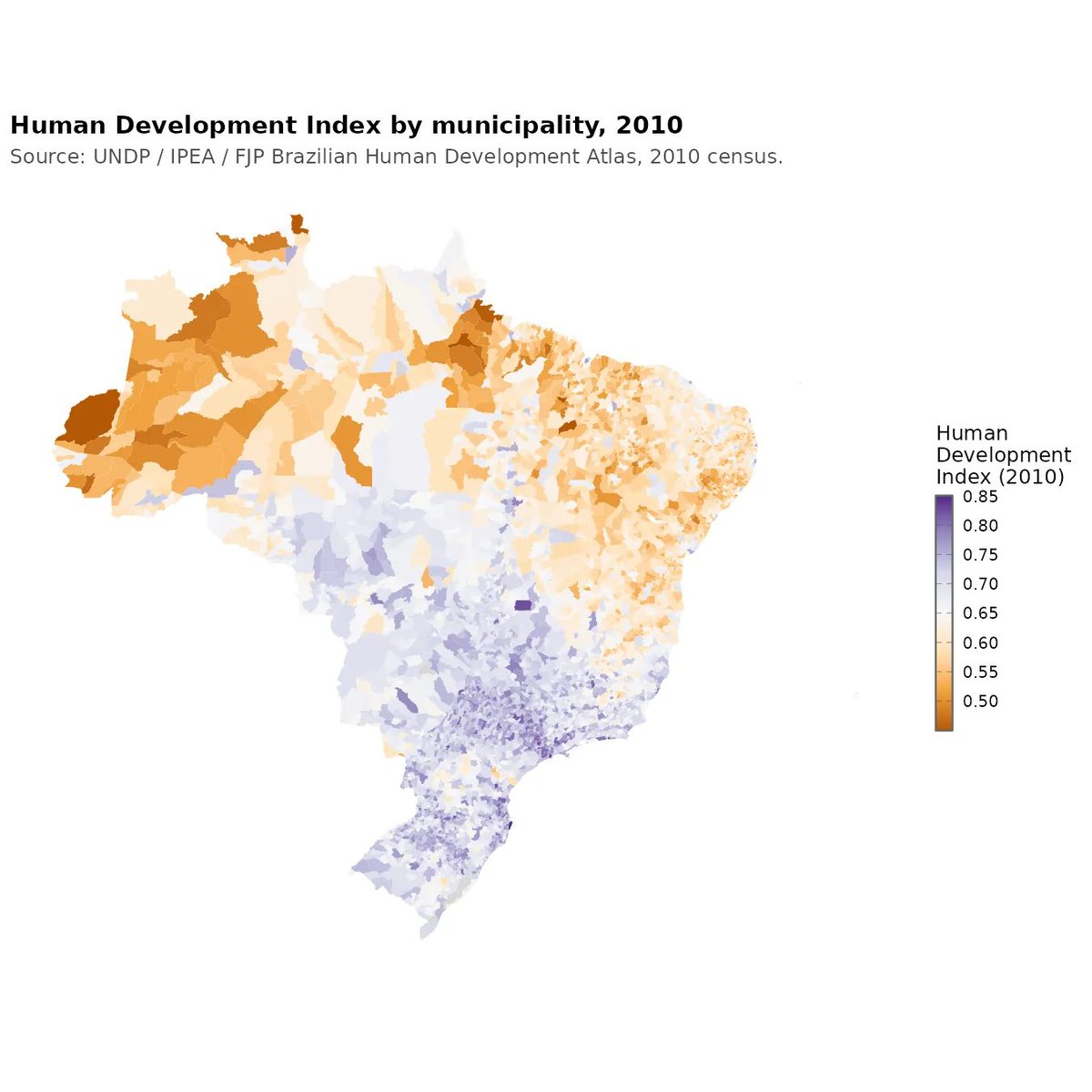
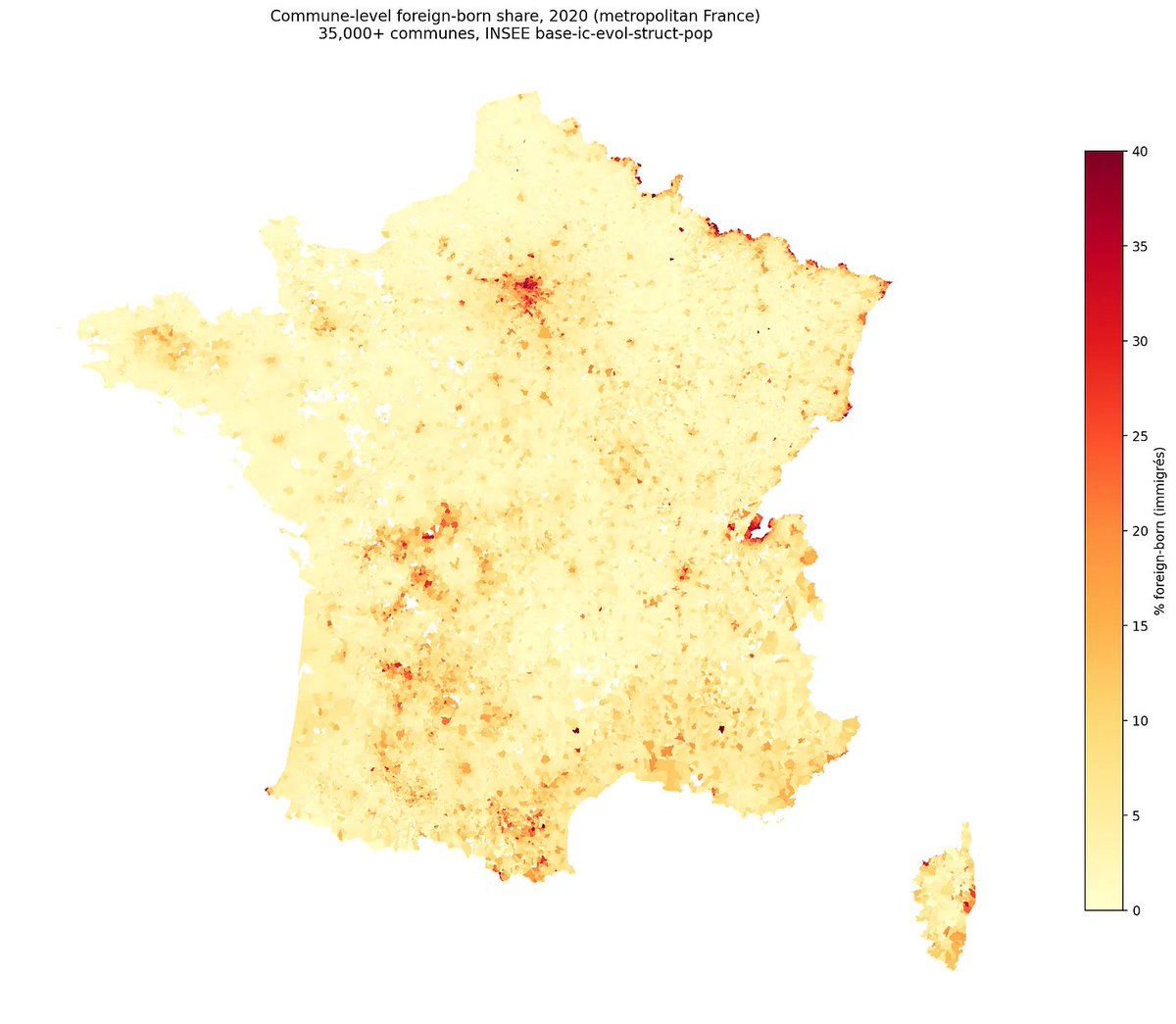
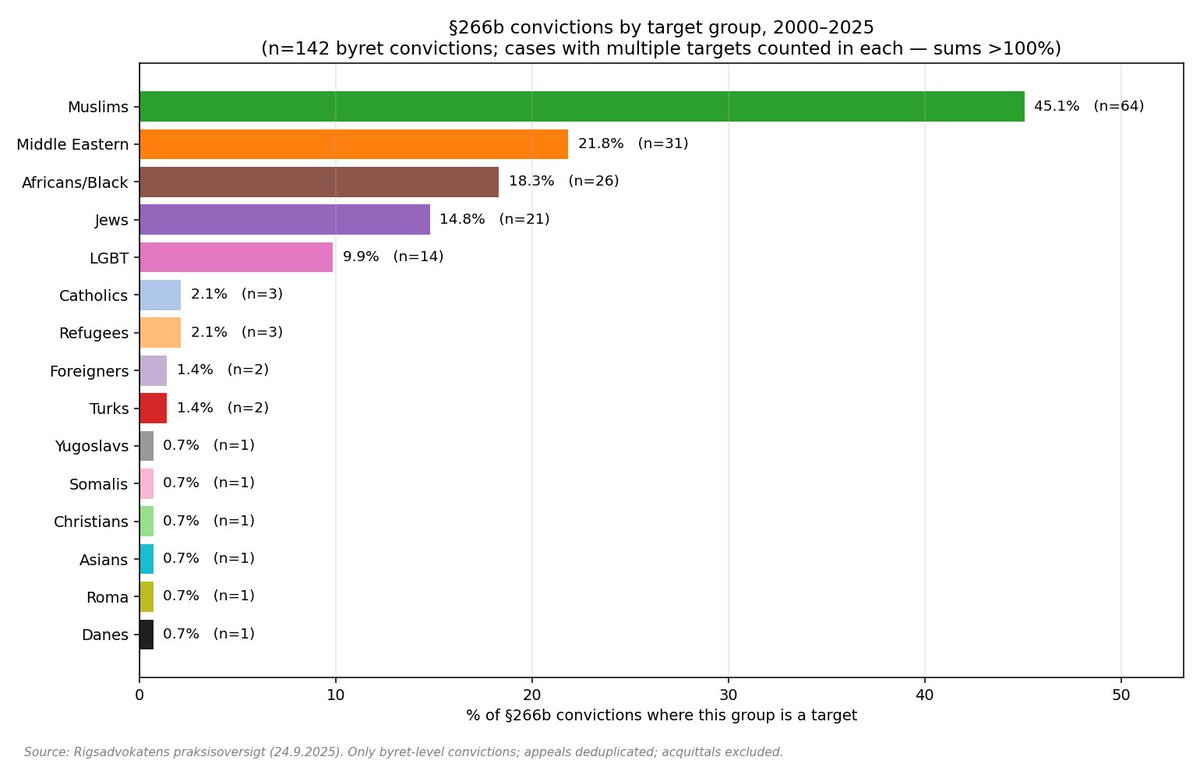
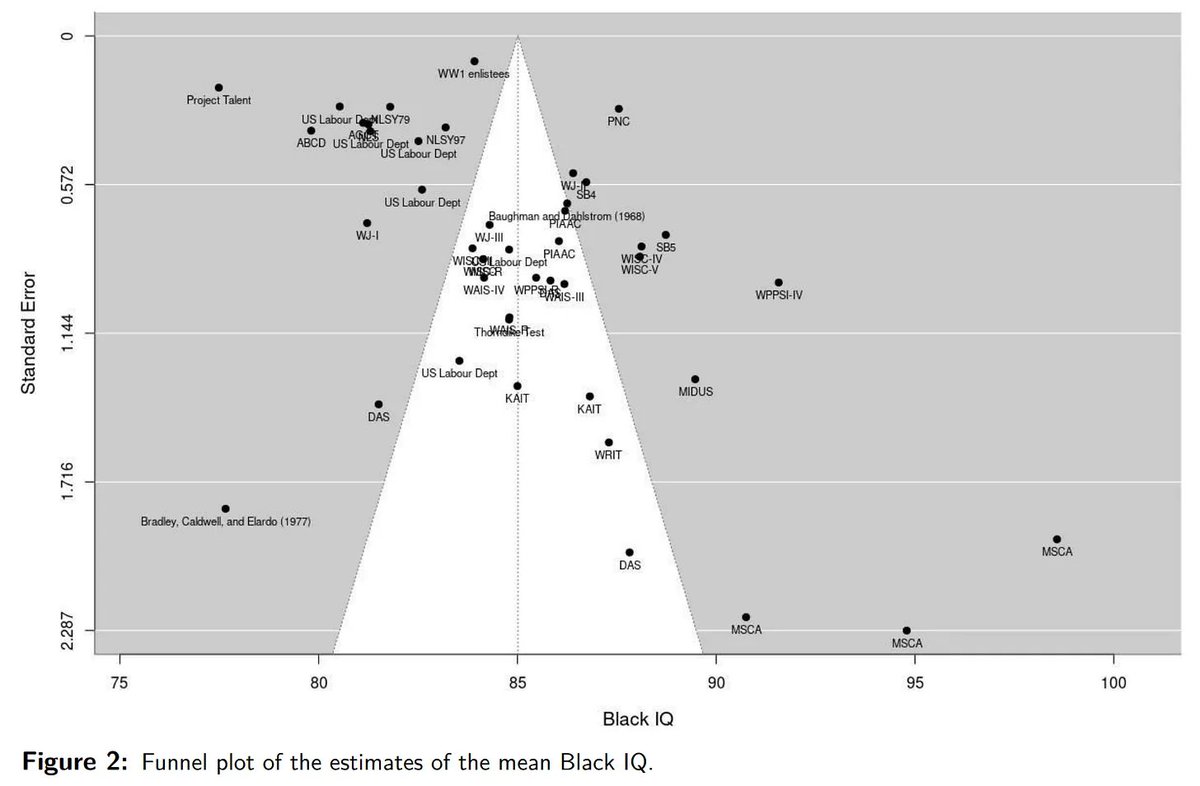
So there is a new Dunning-Kruger paper out by Gignac and Zajenkowski. It goes like this:
Dunning Kruger pattern is trivial given 1) people overestimate themselves, and 2) self-estimate x criterion value is r < 1.00. I agree, I wrote that years ago.
Dunning Kruger pattern is trivial given 1) people overestimate themselves, and 2) self-estimate x criterion value is r < 1.00. I agree, I wrote that years ago.

So they collect some new data, typical weird format students self-rating and Raven's test. Looks like the usual deal.


A nice twist is that they realize the DK claim is a test for heteroscedasticity (what? inconstant variance). Well, I recently spent a lot of time thinking about this and they posted their data on OSF, so all is good, time for re-analysis!
rpubs.com/EmilOWK/hetero…
rpubs.com/EmilOWK/hetero…
So downloading their data, scoring it by simple z-transform, and computing the 10/90th centiles, I get this plot which shows quite clearly there is HS like DK model says, on the low end.

This plot is made using the neat qgam() function, quantile generalized additive models, allowing us to capture nonlinear heteroscedasticity if such exists and visualize it easily.
It's from this package, in case you are curious.
cran.r-project.org/web/packages/q…
It's from this package, in case you are curious.
cran.r-project.org/web/packages/q…
But we are not lazy, so we apply some tests that give p values & effect sizes. Now, I also came up with some 'new tests' and metrics, so let's try them!
They confirm the visual results: there data have good evidence of HS, and it's somewhat nonlinear. 2/3 old tests agree.
They confirm the visual results: there data have good evidence of HS, and it's somewhat nonlinear. 2/3 old tests agree.



Oh, by the way, for that point about writing it years, ago, I built a simulator that you can play around with!
(Published Jul 13, 2015)
emilkirkegaard.dk/understanding_…
(Published Jul 13, 2015)
emilkirkegaard.dk/understanding_…

So I talked with Gignac about this, and he pointed out that I plotted the data the wrong way around. Good point! If we do it the right now around, we get these.
So there is some upwards tick at the very low end, but these are just a few lizardmen out of 2400 people.
So there is some upwards tick at the very low end, but these are just a few lizardmen out of 2400 people.


Here's the same but with the 10/90th quantiles. There's basically nothing to see here. It's very linear and homoscedastic.
So, this n=2400 replication (about 2.5x sample size) finds essentially the same result when done properly.
Main difference is that my cors are stronger.
So, this n=2400 replication (about 2.5x sample size) finds essentially the same result when done properly.
Main difference is that my cors are stronger.


• • •
Missing some Tweet in this thread? You can try to
force a refresh