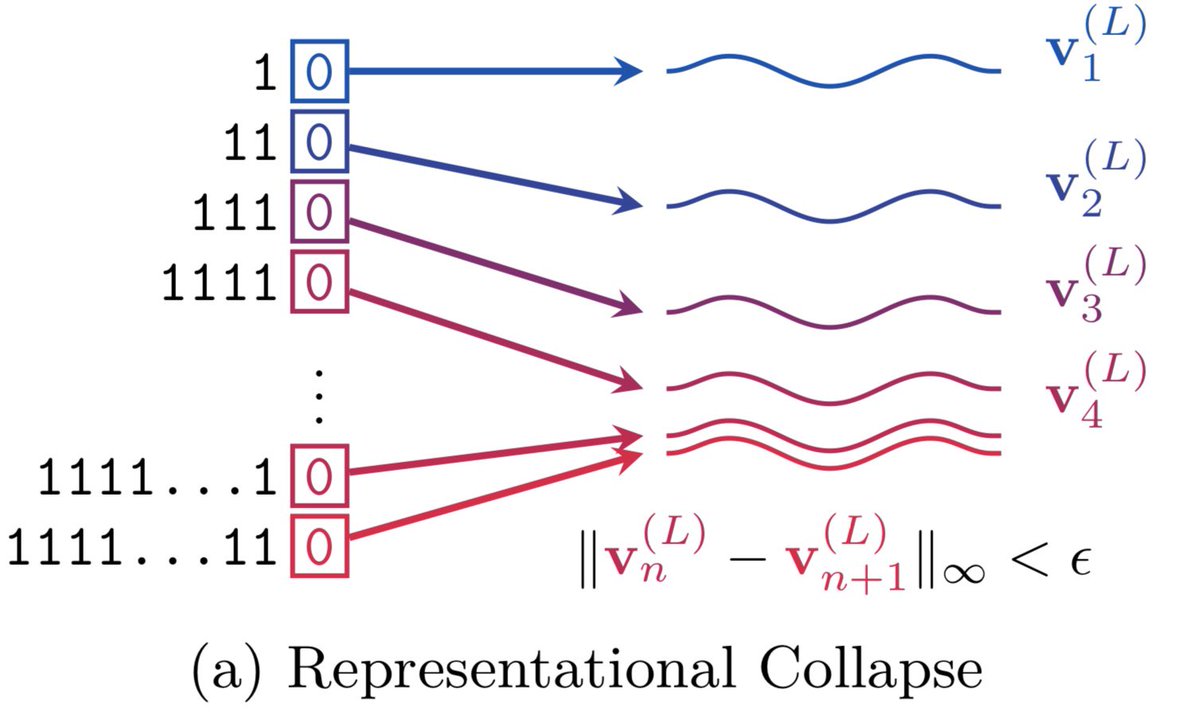
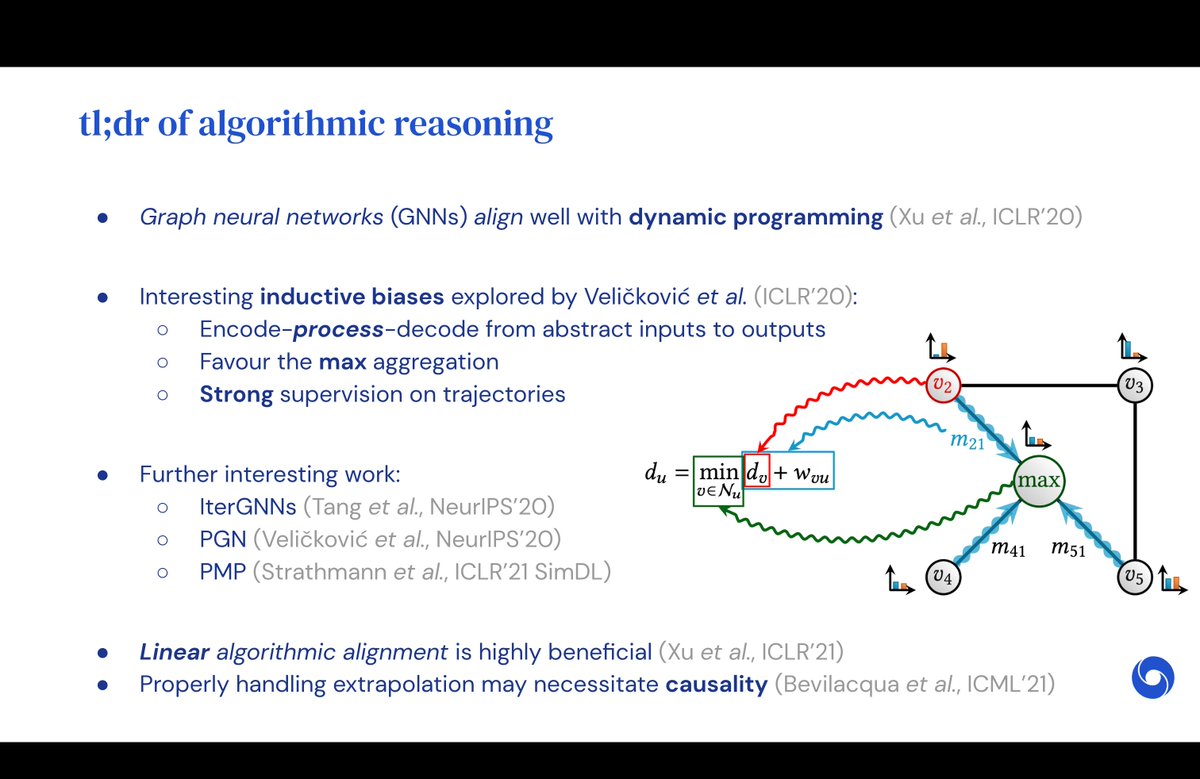
As requested , here are a few non-exhaustive resources I'd recommend for getting started with Graph Neural Nets (GNNs), depending on what flavour of learning suits you best.
Covering blogs, talks, deep-dives, feeds, data, repositories, books and university courses! A thread 👇
Covering blogs, talks, deep-dives, feeds, data, repositories, books and university courses! A thread 👇

For blogs, I'd recommend:
- @thomaskipf's post on Graph Convolutional Networks:
tkipf.github.io/graph-convolut…
- My blog on Graph Attention Networks:
petar-v.com/GAT/
- A series of comprehensive deep-dives from @mmbronstein: towardsdatascience.com/graph-deep-lea…
- @thomaskipf's post on Graph Convolutional Networks:
tkipf.github.io/graph-convolut…
- My blog on Graph Attention Networks:
petar-v.com/GAT/
- A series of comprehensive deep-dives from @mmbronstein: towardsdatascience.com/graph-deep-lea…
For a comprehensive overview of the area in the form of a talk, I would highly recommend @xbresson's guest lecture at NYU's Deep Learning course:
https://twitter.com/alfcnz/status/1300134720886497286
For keeping up with the latest trends in graph representation learning, @SergeyI49013776 maintains a very useful Telegram feed: ttttt.me/graphML, as well as a recently-launched GRL newsletter: newsletter.ivanovml.com/issues/gml-new…
For access to the most recent strong GRL benchmark datasets, I would recommend the OGB (ogb.stanford.edu) by @weihua916 et al., and Benchmarking-GNNs: github.com/graphdeeplearn… by @vijaypradwi, @chaitjo et al.
For quickly getting started with GRL implementations, check out PyTorch Geometric by @rusty1s: github.com/rusty1s/pytorc… and DGL by @GraphDeep: dgl.ai
For a repository containing the most curated set of GRL papers, tutorials etc, check out: github.com/naganandy/grap…
For a repository containing the most curated set of GRL papers, tutorials etc, check out: github.com/naganandy/grap…
For an awesome over-arching textbook resource on the entire field, consult the recent GRL book by @williamleif: cs.mcgill.ca/~wlh/grl_book/
For excellent university courses, check out CS224W by @jure: web.stanford.edu/class/cs224w/ and COMP 766 by @williamleif: cs.mcgill.ca/~wlh/comp766/
For excellent university courses, check out CS224W by @jure: web.stanford.edu/class/cs224w/ and COMP 766 by @williamleif: cs.mcgill.ca/~wlh/comp766/
Any further resources I might have missed? Feel free to comment at any part of this thread.
Hope you'll find it useful! 😊
Hope you'll find it useful! 😊
• • •
Missing some Tweet in this thread? You can try to
force a refresh