
Senior Staff Research Scientist @GoogleDeepMind | Affiliated Lecturer @Cambridge_Uni | Assoc @clarehall_cam | GDL Scholar @ELLISforEurope. Monoids. 🇷🇸🇲🇪🇧🇦




 There's been a rightful surge of AI-powered competitive programming systems, typically deployed on classical contests such as Codeforces.
There's been a rightful surge of AI-powered competitive programming systems, typically deployed on classical contests such as Codeforces.

 We start by asking a frontier LLM a simple query: copy the first & last token of bitstrings.
We start by asking a frontier LLM a simple query: copy the first & last token of bitstrings. 



 🌐 In "Reasoning-Modulated Representations", Matko Bošnjak, @thomaskipf, @AlexLerchner, @RaiaHadsell, Razvan Pascanu, @BlundellCharles and I demonstrate how to leverage arbitrary algorithmic priors for self-supervised learning. It even transfers _across_ different Atari games!
🌐 In "Reasoning-Modulated Representations", Matko Bošnjak, @thomaskipf, @AlexLerchner, @RaiaHadsell, Razvan Pascanu, @BlundellCharles and I demonstrate how to leverage arbitrary algorithmic priors for self-supervised learning. It even transfers _across_ different Atari games! 
 What to expect in the 2022 iteration?
What to expect in the 2022 iteration?
 Why an algorithmic benchmark?
Why an algorithmic benchmark?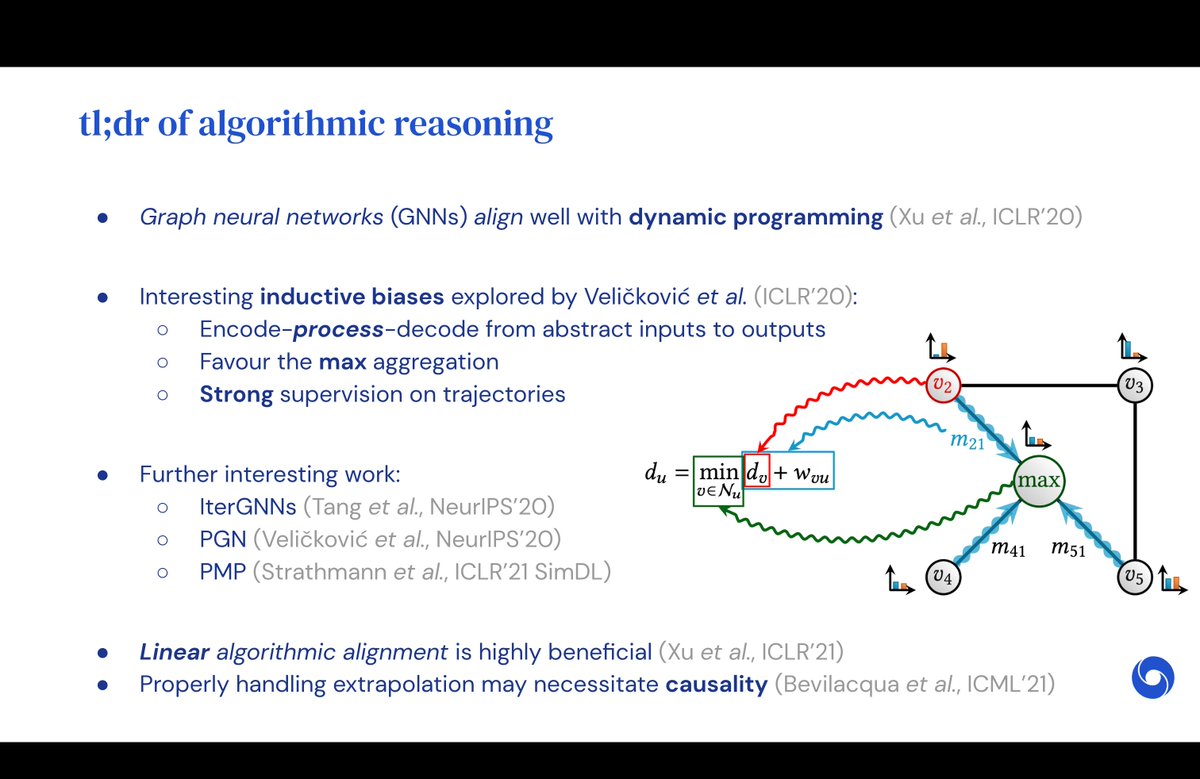
 Trend #1: Geometry becomes increasingly important in ML. Quotes from Melanie Weber (@UniofOxford), @pimdehaan (@UvA_Amsterdam), @Francesco_dgv (@Twitter) and Aasa Feragen (@uni_copenhagen).
Trend #1: Geometry becomes increasingly important in ML. Quotes from Melanie Weber (@UniofOxford), @pimdehaan (@UvA_Amsterdam), @Francesco_dgv (@Twitter) and Aasa Feragen (@uni_copenhagen).
 (1) "Neural Algorithmic Reasoners are Implicit Planners" (Spotlight); with @andreeadeac22, Ognjen Milinković, @pierrelux, @tangjianpku & Mladen Nikolić.
(1) "Neural Algorithmic Reasoners are Implicit Planners" (Spotlight); with @andreeadeac22, Ognjen Milinković, @pierrelux, @tangjianpku & Mladen Nikolić.


 For large-scale transductive node classification (MAG240M), we found it beneficial to treat subsampled patches bidirectionally, and go deeper than their diameter. Further, self-supervised learning becomes important at this scale. BGRL allowed training 10x longer w/o overfitting.
For large-scale transductive node classification (MAG240M), we found it beneficial to treat subsampled patches bidirectionally, and go deeper than their diameter. Further, self-supervised learning becomes important at this scale. BGRL allowed training 10x longer w/o overfitting.
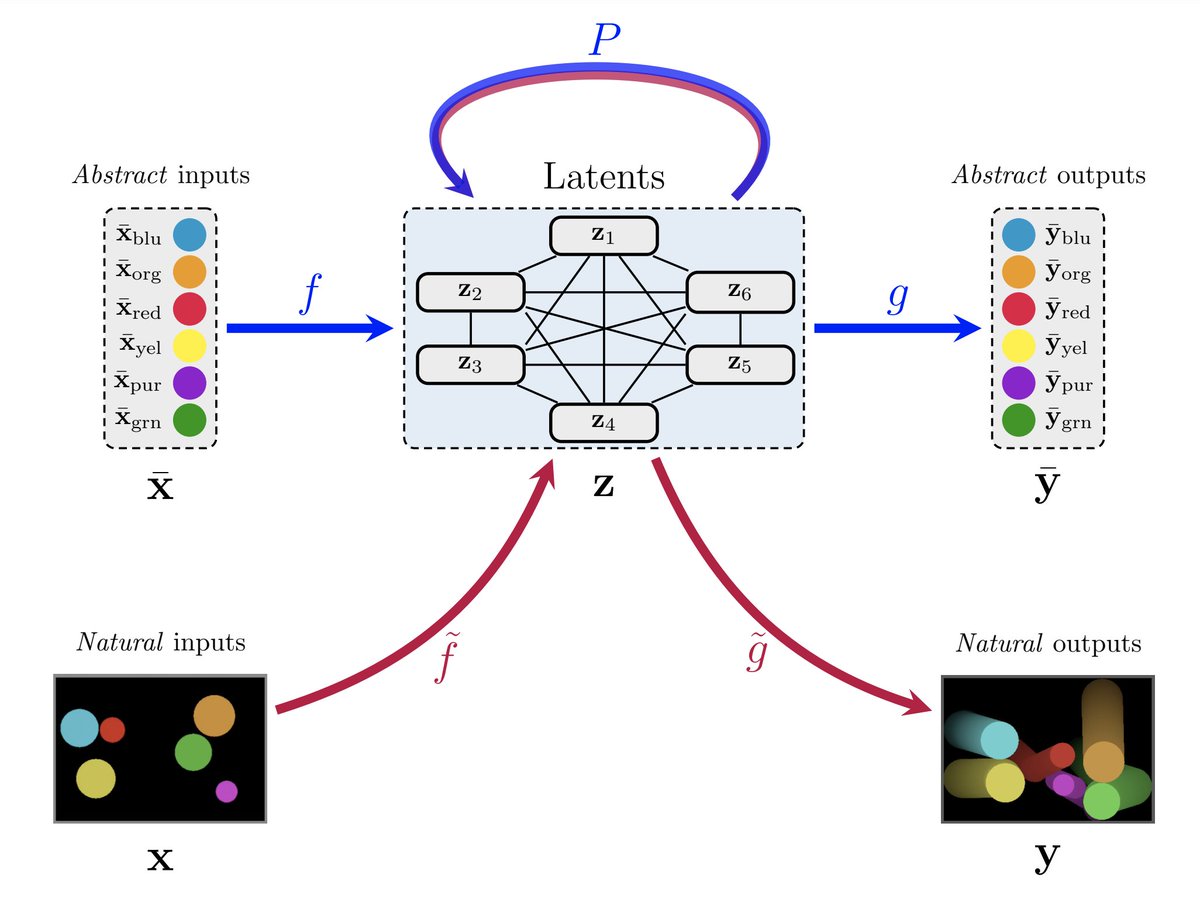 We study a very common representation learning setting where we know *something* about our task's generative process. e.g. agents must obey some laws of physics, or a video game console manipulates certain RAM slots. However...
We study a very common representation learning setting where we know *something* about our task's generative process. e.g. agents must obey some laws of physics, or a video game console manipulates certain RAM slots. However... 
 We have investigated the essence of popular deep learning architectures (CNNs, GNNs, Transformers, LSTMs) and realised that, assuming a proper set of symmetries we would like to stay resistant to, they can all be expressed using a common geometric blueprint.
We have investigated the essence of popular deep learning architectures (CNNs, GNNs, Transformers, LSTMs) and realised that, assuming a proper set of symmetries we would like to stay resistant to, they can all be expressed using a common geometric blueprint. 
 For blogs, I'd recommend:
For blogs, I'd recommend: