
If your treatment variable has bunching, this is good news! It may be possible to use this bunching to build a correction for endogeneity. We show how this may be done in our new paper. Follow the thread. #EconTwitter #econometrics 1/
https://twitter.com/fedresearch/status/1307012310502957057
We focus here on bunching at one of the ends of the support, which turns out to be very common. For example, TV watching, enrichment activities, maternal labor supply, smoking amounts, all have bunching at zero, and the list of variables where this happens goes on and on. 2/ 
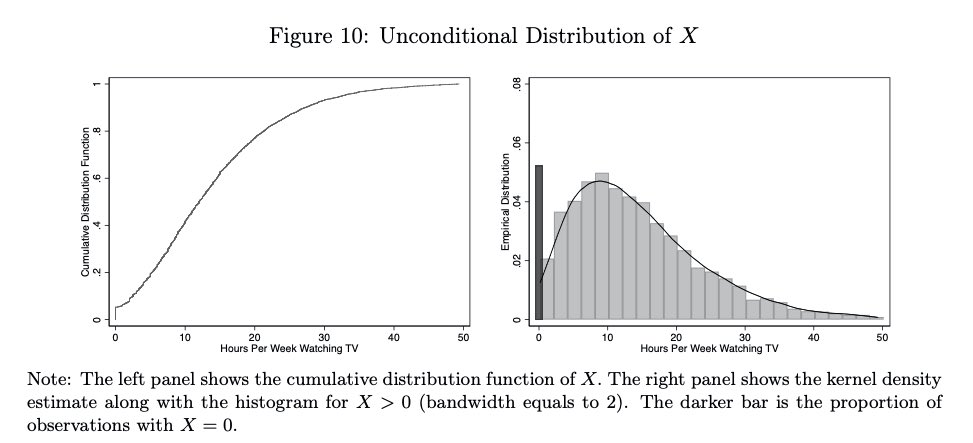
Take the amount of time children spend watching TV. You can't watch a negative amount of time. Even if your characteristics would place you as a negative watcher, you will still watch zero, and you will be bunched with all the other extreme people. 3/
So, at the bunching point, there are discontinuities in the confounders. When we compare zero TV per week with a few minutes of TV per week, the treatment difference is irrelevant, but the confounder difference is substantial. 4/
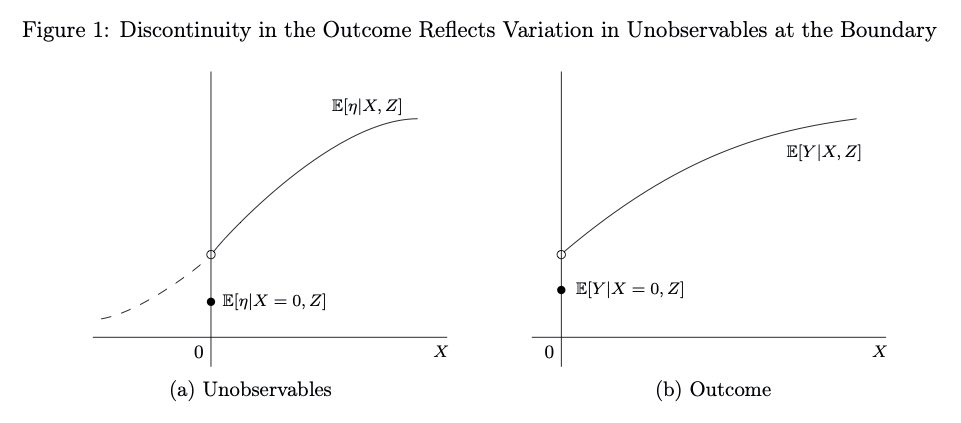
Thus, a discontinuity in the outcome at the bunching point will only reflect the effect of the confounders, separate of the effect of the treatment. This reveals information about the endogeneity bias. We can use this information to build the correction of the endogeneity bias.5/
The main requirement is that the information the confounders give you at the bunching point can be used to infer the endogeneity bias in other places. This is often testable. 6/
The second requirement is that we must be able to use the choice of TV on the positive side to infer what the choice of TV would have been in the negative side if there was no constraint. This is an out-of-sample prediction exercise. Read the next tweet. 7/
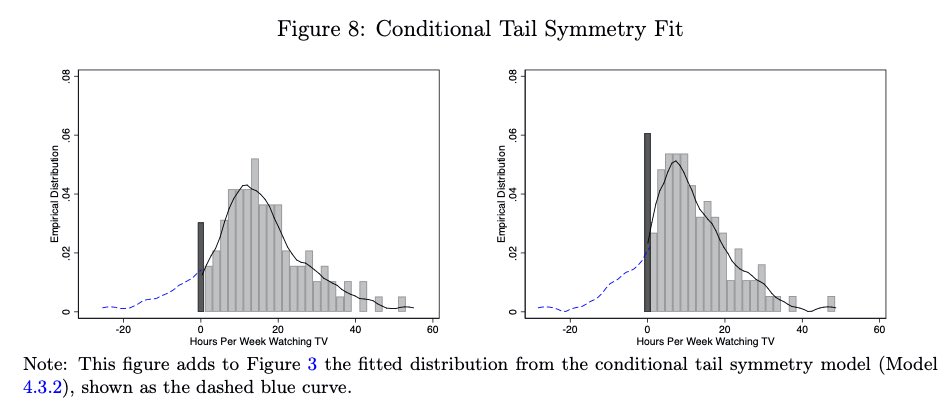
We went pretty far studying how to do this: partial identification, using families of distributions with parametric and nonparametric parameters, tail symmetry conditions, and using clustering methods. We also propose several tests of the assumptions. 8/
As for the TV, turns out that watching TV will not affect the child’s cognitive skills on the net, but will decrease non-cognitive skills.
https://twitter.com/FedResearch/status/1307012430120194048?s=209/
In a linear model the correction is an estimated regressor which gets added to the main regression. Our estimation results allow for very general estimators of that regressor, and you can bootstrap the standard errors. go.usa.gov/xGQjw 10/

If you prefer to learn the method in an applied paper, we apply this technique in this paper: bit.ly/3mFQUIi.

• • •
Missing some Tweet in this thread? You can try to
force a refresh





