
I've been working on a project that is a bit niche. It's not finished yet as I have to finish other stuff, but it tries to tap into the iconic status of the Countdown show. It is running since 1982 en.wikipedia.org/wiki/Countdown…
A show typically has letter/word rounds (I'm less interested in those) and number rounds (yes!). EVen from when I was young - in the Netherlands we had a variant called 'cijfers and letters'- I have been intrigued by solution processes.
For example many players would just do a number times 100 and then add some other numbers. Others seemed to have more insight in arithmetical properties.
The rules. 6 numbers are chosen from stacks of numbers. There are two groups: 20 "small numbers" (two each of 1 through 10), four "large numbers" of 25, 50, 75 and 100. A random number is generated from a uniform distribution (101 to 999 I think).
Then in 30 seconds you need to try and get as close as possible to the target number, using the four main operations. Only whole numbers, you can use every number only once. You get the picture (you will probably recognise it).
Sometimes solutions are mindblowing, for example this one:
Numbers given: 25 50 75,100 3 6
Target: 952
The contestant came up with:
100 + 6 = 106
3*106 = 318
318*75 = 23,850
23,850–50 = 23,800
23,800/25 = 952
Numbers given: 25 50 75,100 3 6
Target: 952
The contestant came up with:
100 + 6 = 106
3*106 = 318
318*75 = 23,850
23,850–50 = 23,800
23,800/25 = 952
Sure it could be done more economically, but these strategies fascinate me.
Could they be studied?
Could they be studied?
I encountered a website that manually keeps historical records of all Countdown episodes.
Ah, a mining challenge!
I wrote a script that scaroed all 6373 epsiodes from the website and then extracted more than 40000 number rounds from them.
Ah, a mining challenge!
I wrote a script that scaroed all 6373 epsiodes from the website and then extracted more than 40000 number rounds from them.
As these are manual records there were some issues, typos, inconsistencies etc, but it worked quite nicely. I especially wanted to automatically double-check if the calculation really led to the answer.
After all, any syntax error should be corrected. I think there were about 2000 that had to be corrected manually. I'm still doing that, it's the boring part.... :-)
Mind you, I have to rely on these historical records, of course, I've already noted some omissions. But tens of thousands calculations is already interest, I think.
These sums can be studied regarding structure.
These sums can be studied regarding structure.
The plan is to use sequence analysis to study the solution patterns, also in relation to success and achievement. I've actually done some already but there are some conceptual choices still to make.
As there are too many combinations of unique numbers, I make the same distinction as in the game show, Big and Small numbers. There are nice statistical and visual ways, I think, to make strategies more visible. An experiment below. 

What I didn't realise, while parsing the sums, is the large role of (superfluous) brackets.
(100+1)*6
((100+1)*6)
((((100+1)*6)))
So, I'm looking at for example Reverse Polish Notation to remove them en.wikipedia.org/wiki/Reverse_P…
(100+1)*6
((100+1)*6)
((((100+1)*6)))
So, I'm looking at for example Reverse Polish Notation to remove them en.wikipedia.org/wiki/Reverse_P…
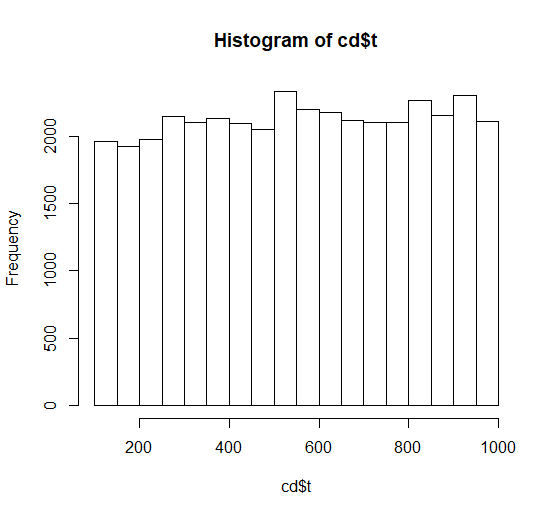
I was happy to see that the taregt numbers indeed seem to adhere to a uniform distribution :-)
I'm excited I am using data from an iconic game show. Will pick up again soon.
I'm excited I am using data from an iconic game show. Will pick up again soon.
One operational challenge is that the matrices for sequence analysis with 34000+ rows with up to 23 'elements' (longest formula, with brackets) amount to Gigabytes...systems at home are struggling, really need the better system in my office.....
• • •
Missing some Tweet in this thread? You can try to
force a refresh




