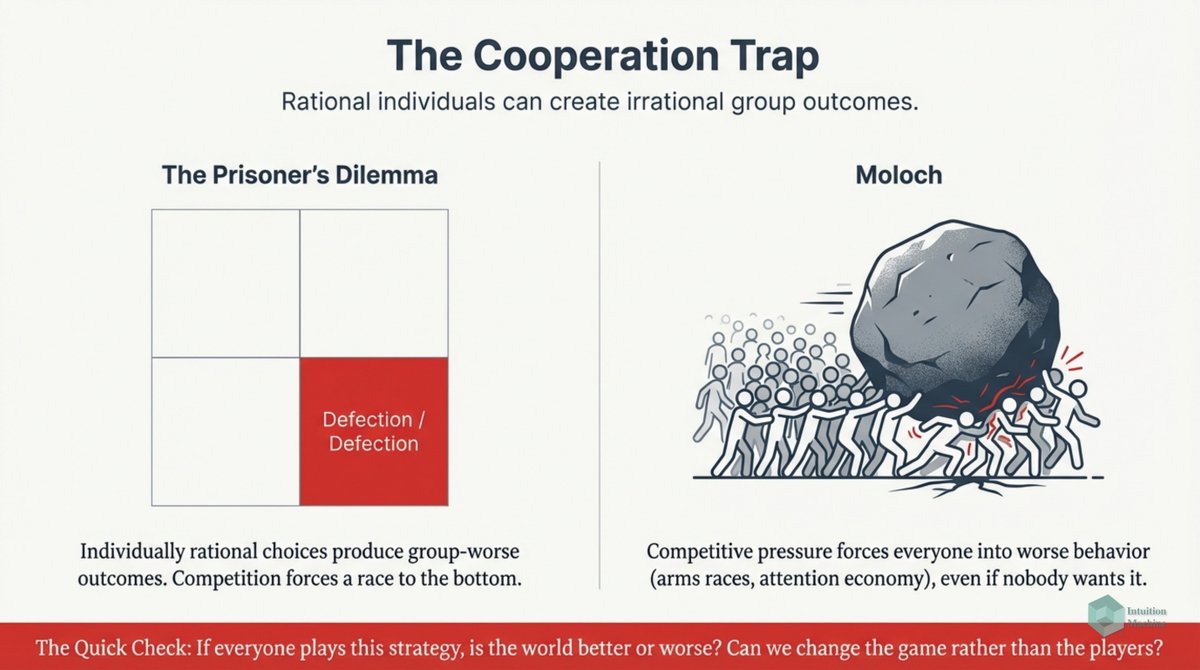
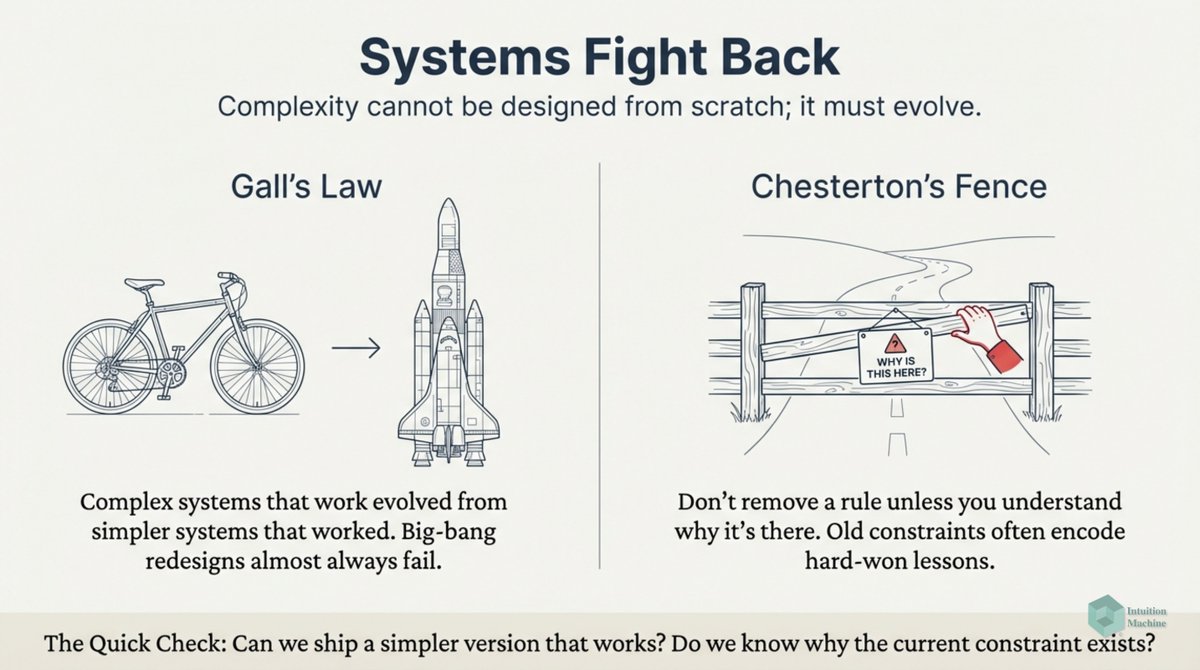
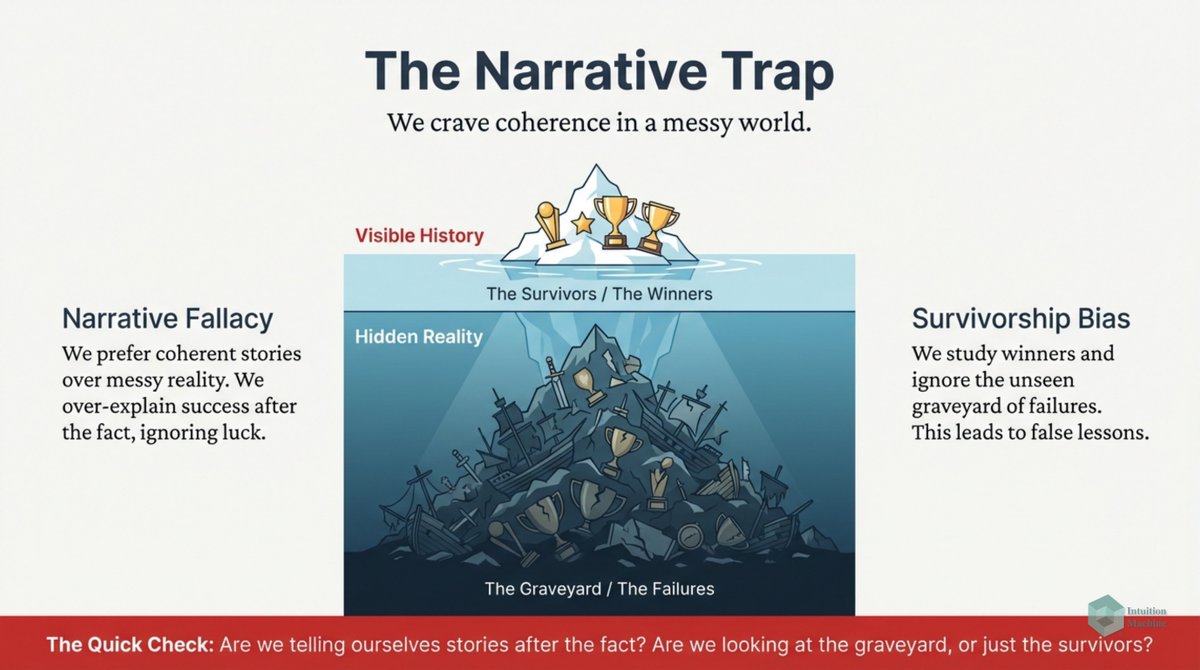
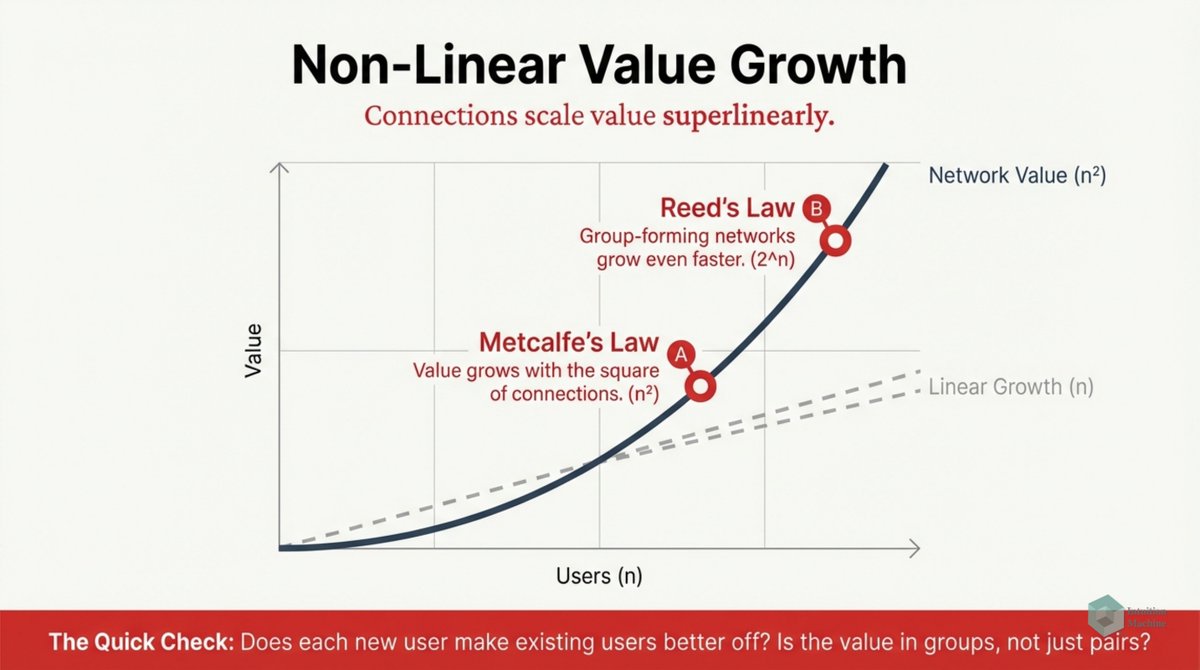
I confess I don't understand philosophy. I don't understand the language nor do I understand the train of thinking. I suspect that my comfort in understanding how the mind works relate to my inability to understand philosophy!
I have an intuition for Wittgenstein, but I can't follow most philosopher arguments. It seems that they are following mental scripts that I have not studied. Different philosophers have different mental scripts and it seems the task is to stitch together these scripts.
The validity of a script is based on the stature of the philosopher. So it's kind of like a franchise of comic books with different narratives and the task is to come up with a universe story where everything fits.
Imagine you are Stan Lee (Marvel comics) and you have to fit the idea of gods (Thor), the idea of magic (Dr. Strange), the idea of evolution (X-men), the idea of technological enablement (Ironman), the idea of serums (Capt. America) all in one universe.
This is what philosophy seems to me. A universe of improvised connectivity. A universe absent consistency. Other than the local consistency of every philosopher.
To be a good philosopher, you two choices (1) make up your own self-consistent universe or (2) know how to craft why one universe relates to another universe.
• • •
Missing some Tweet in this thread? You can try to
force a refresh