
Quaternion Process Theory, Artificial (Intuition, Fluency, Empathy), Patterns for (Gen, LRM, Agentic, Skill) AI,
https://t.co/fhXw0zk5MX
 Wordcells remain captured by the abstractions encoded in language, while shape rotators recognize abstractions as movable frames. They can zoom out, zoom in, and rotate perspective rather than merely elaborate the current verbal frame.
Wordcells remain captured by the abstractions encoded in language, while shape rotators recognize abstractions as movable frames. They can zoom out, zoom in, and rotate perspective rather than merely elaborate the current verbal frame. 



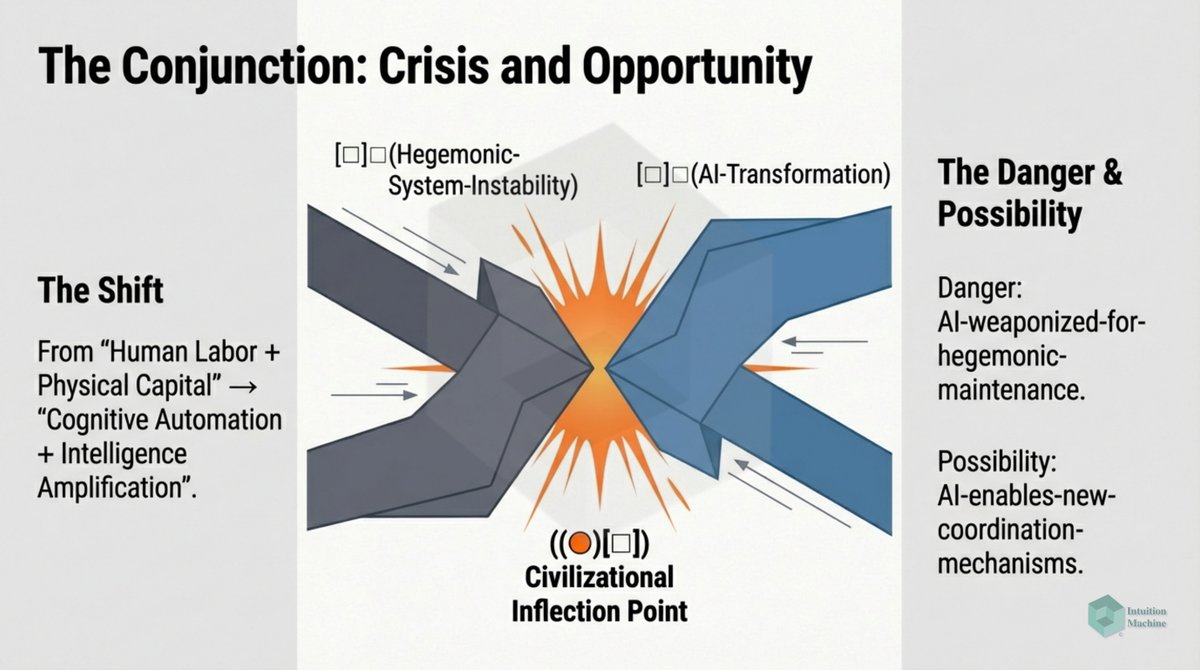
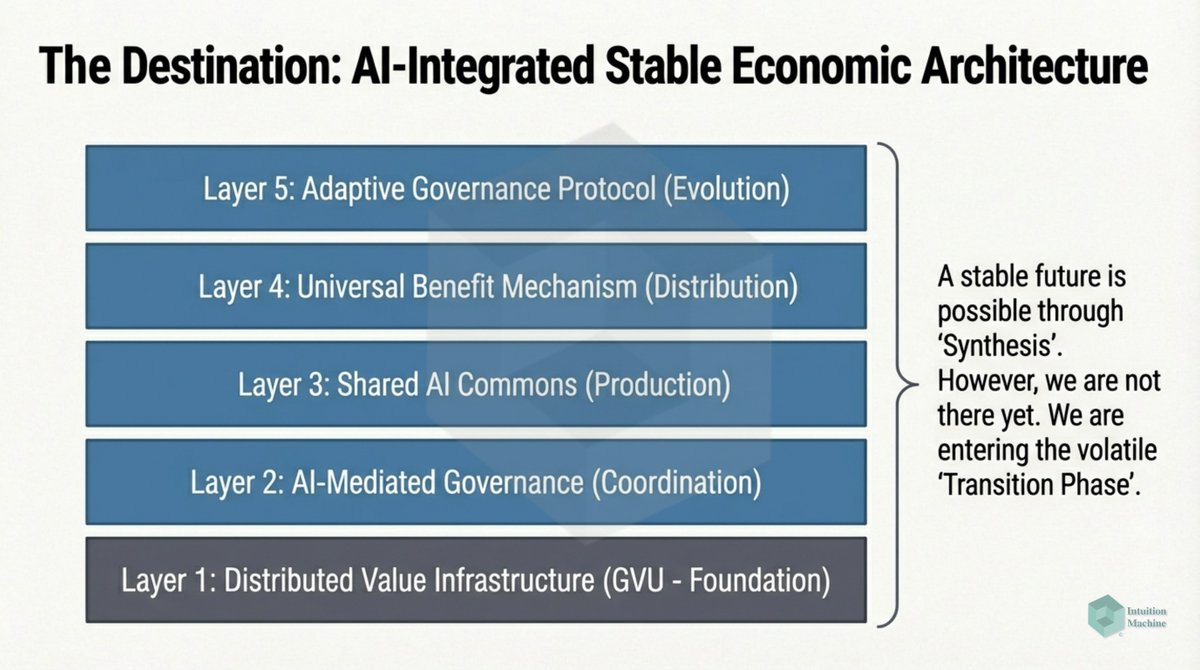





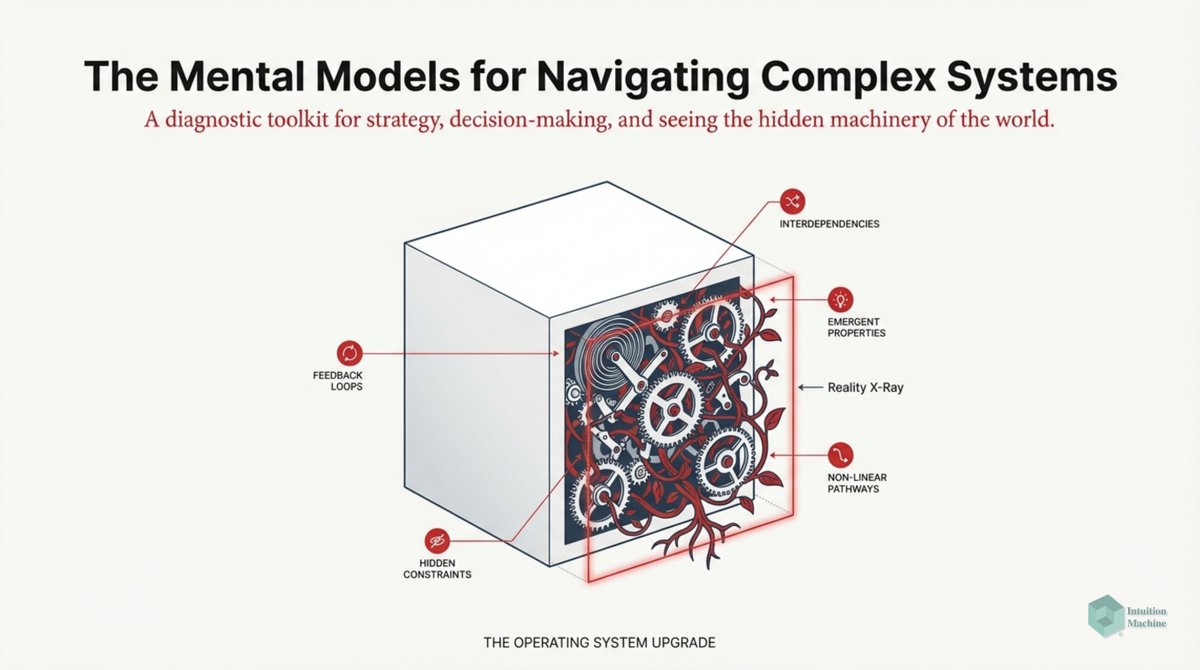
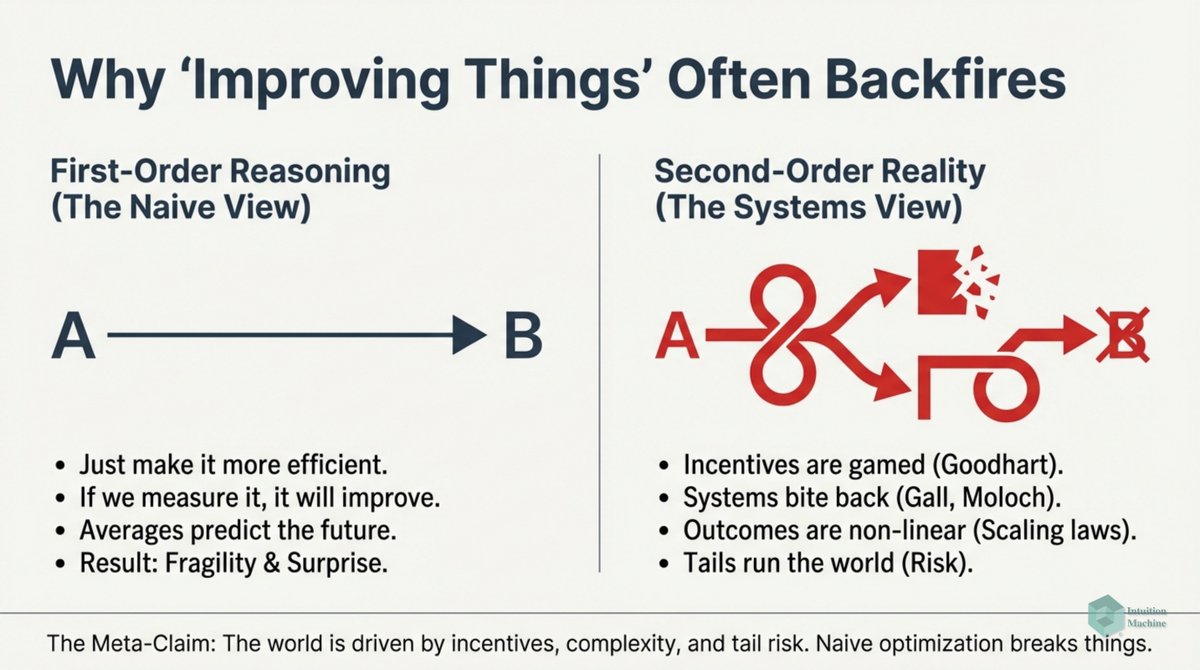
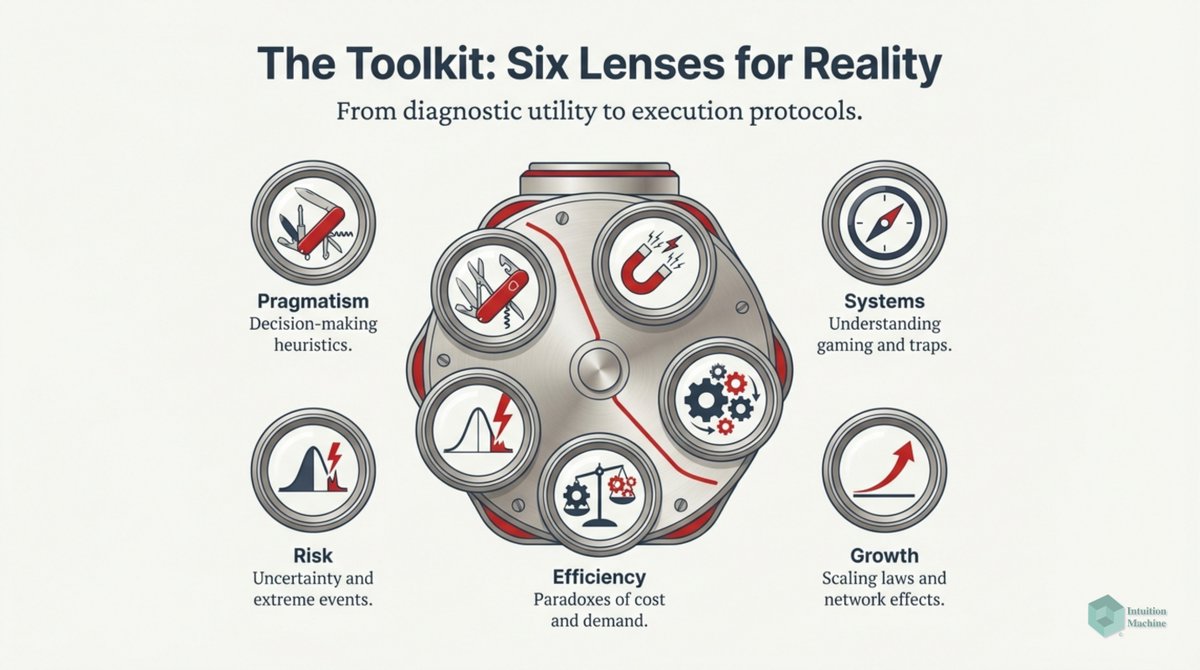
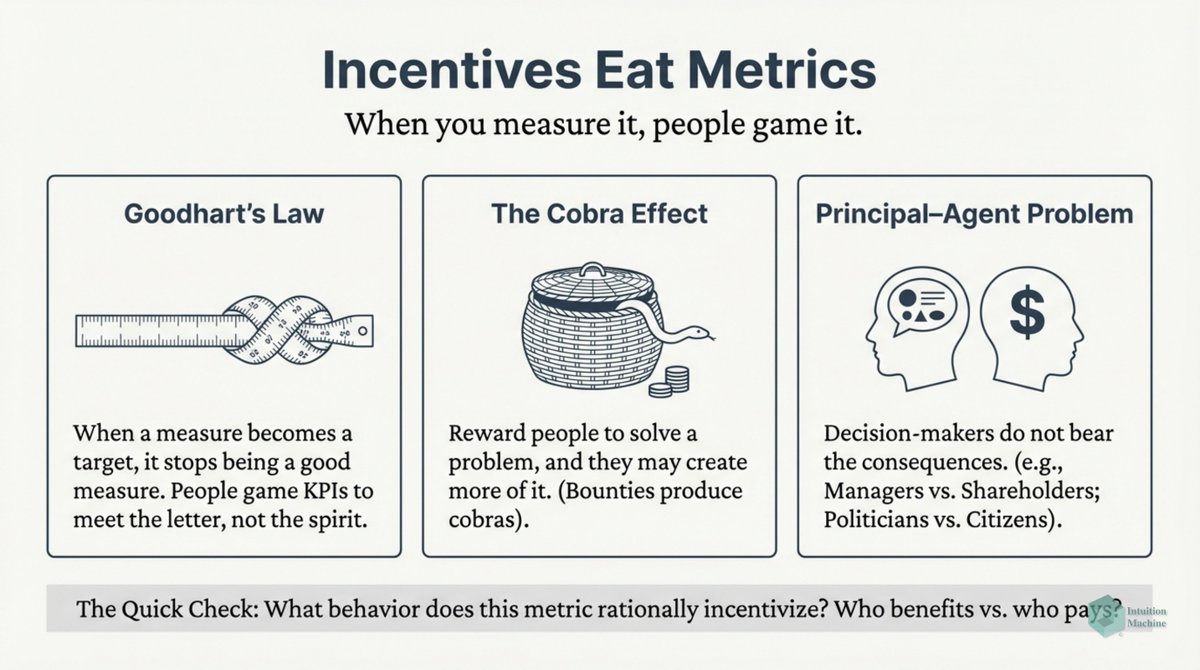
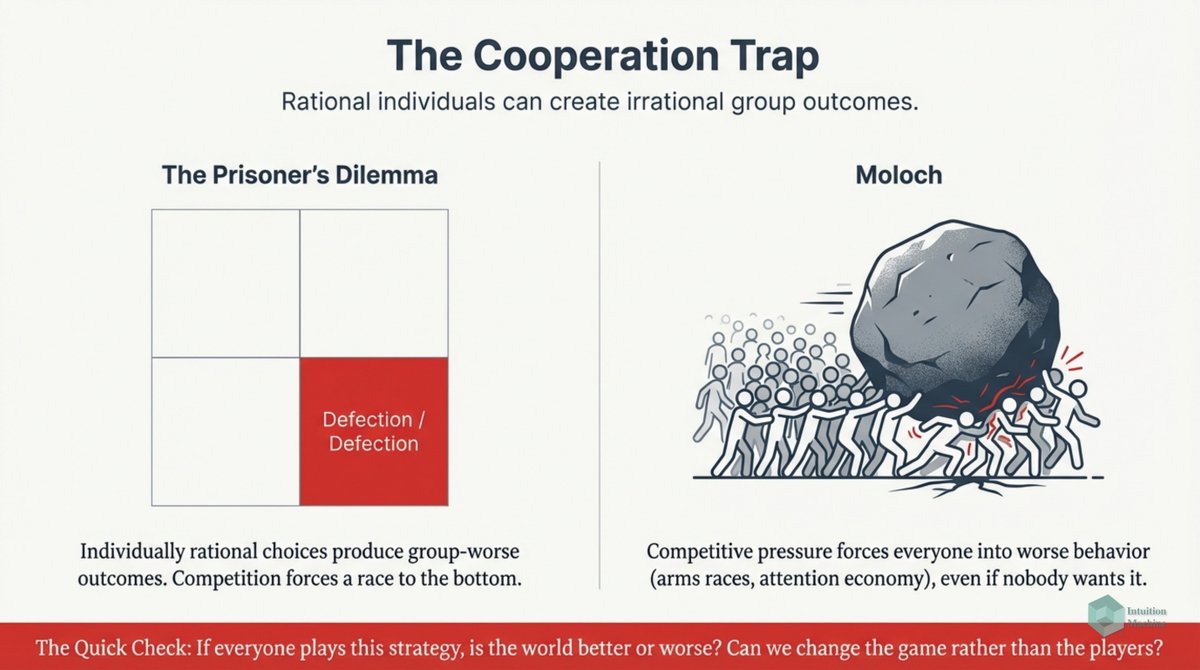
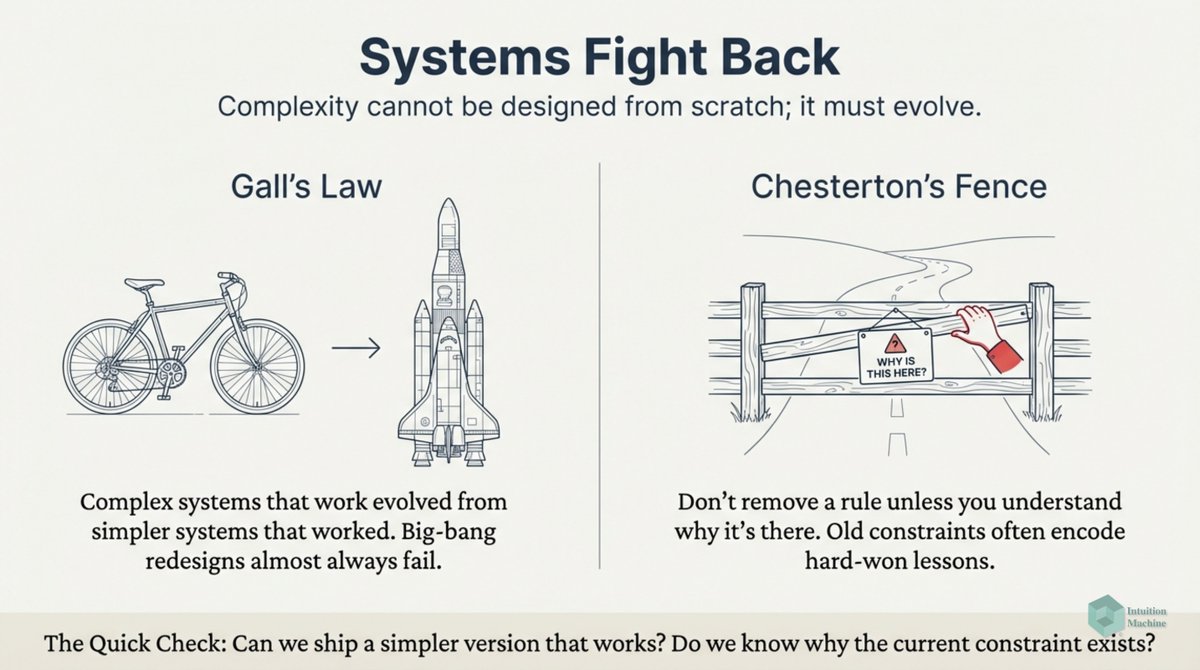
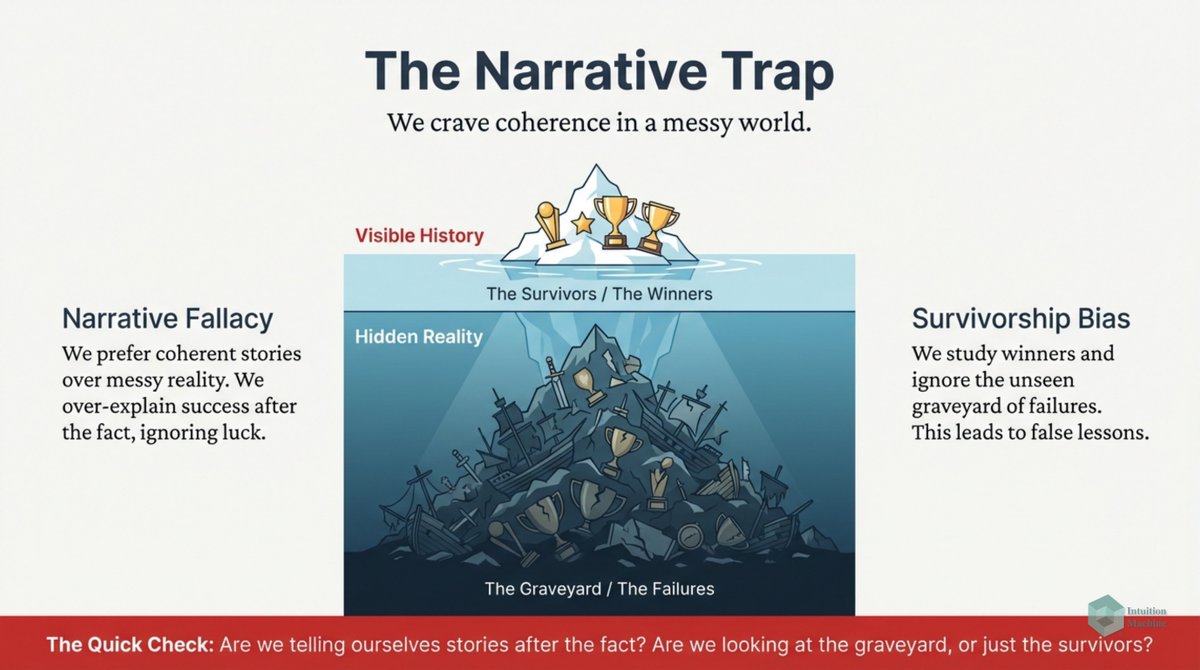
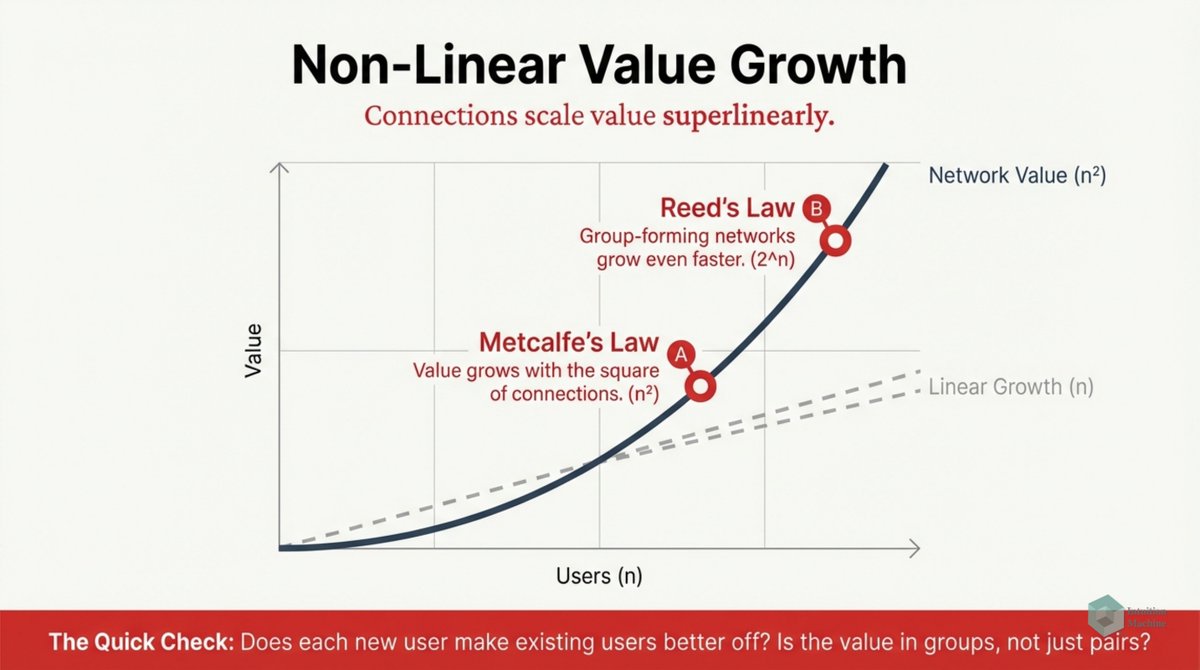


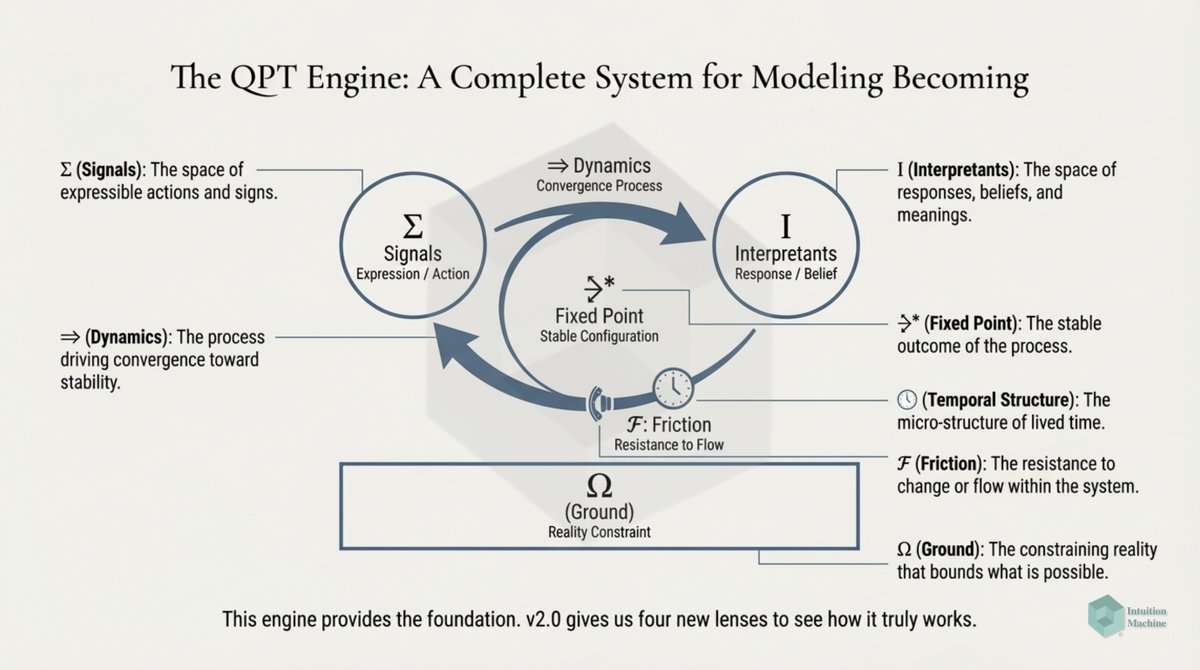
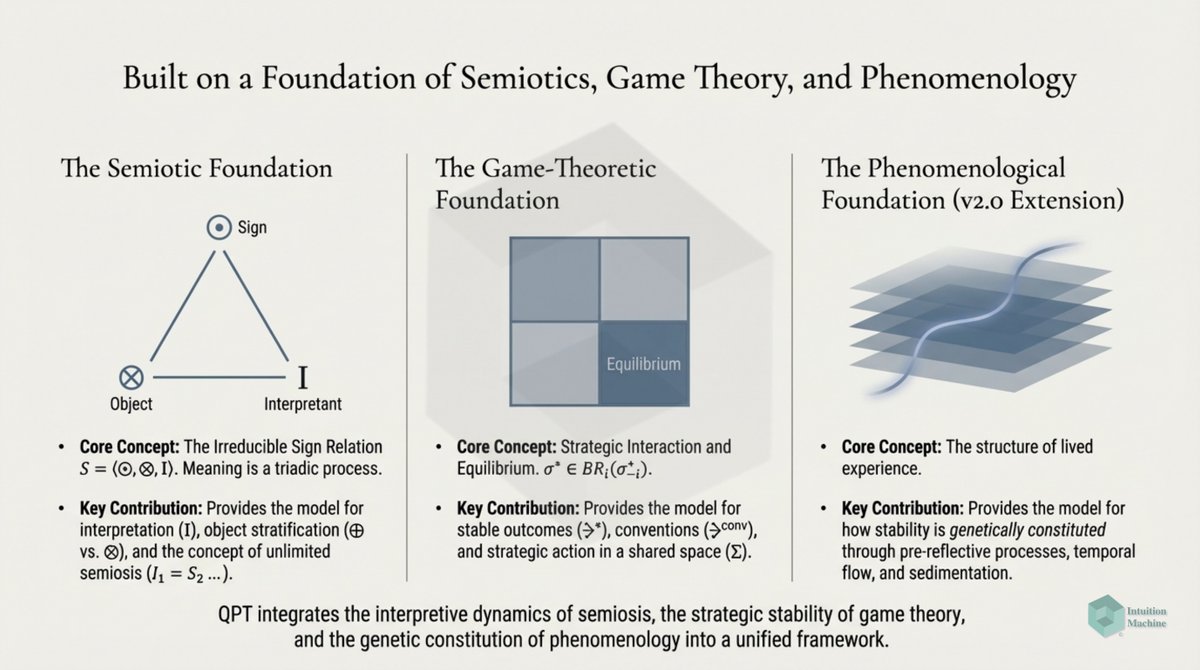


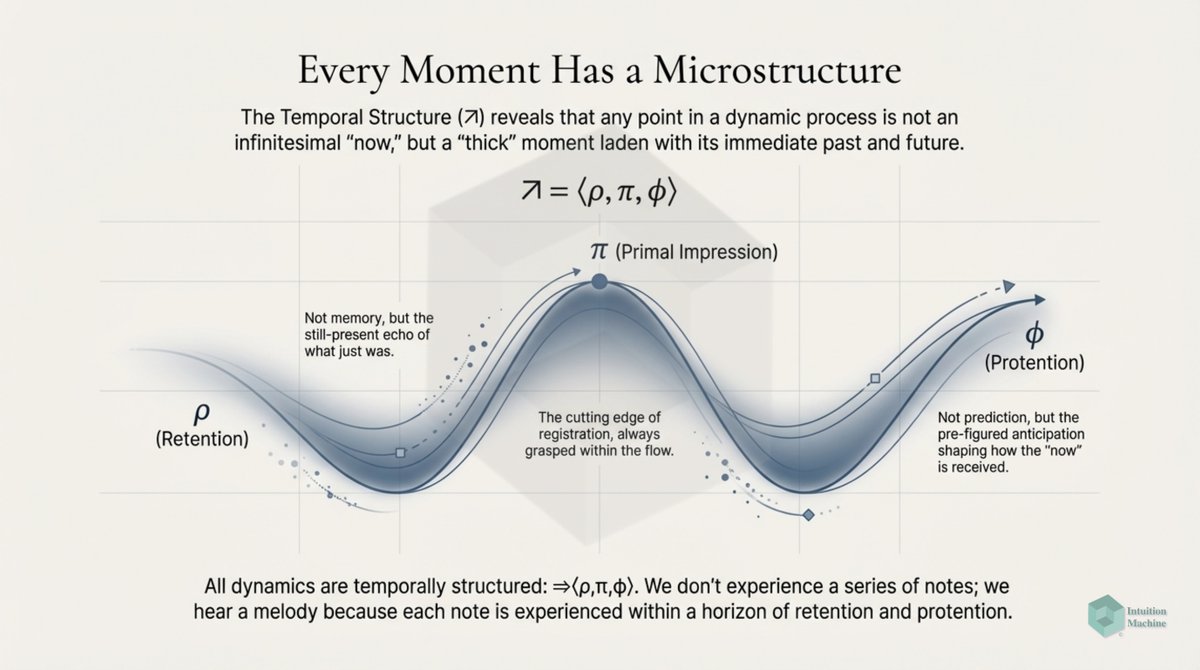
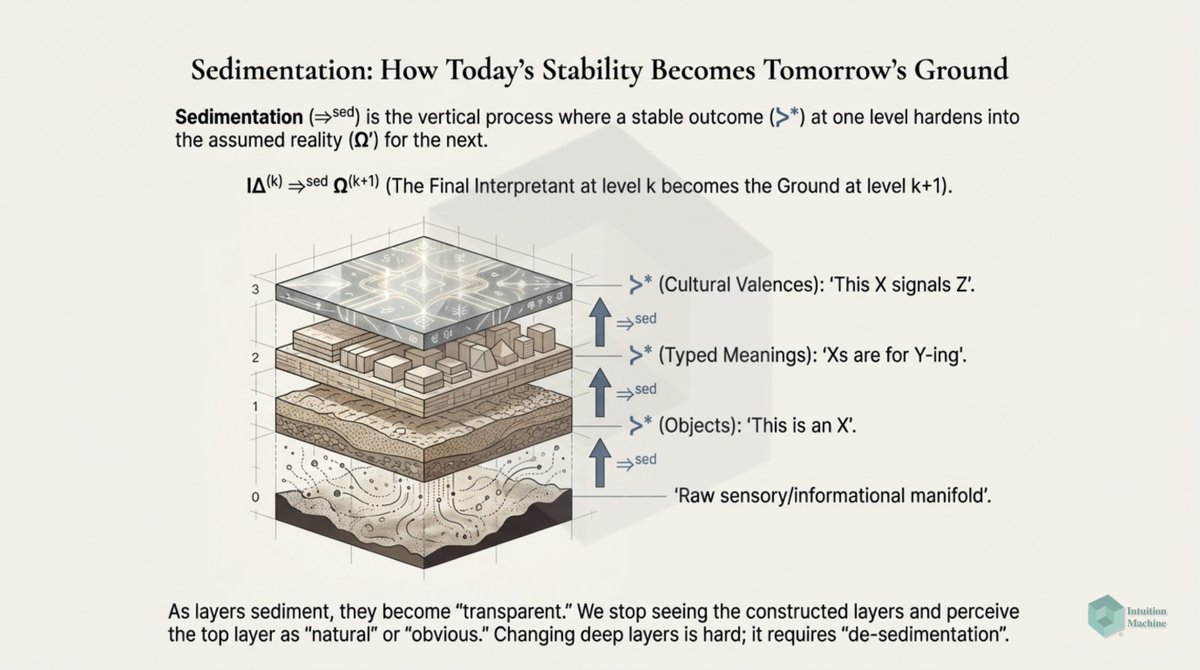








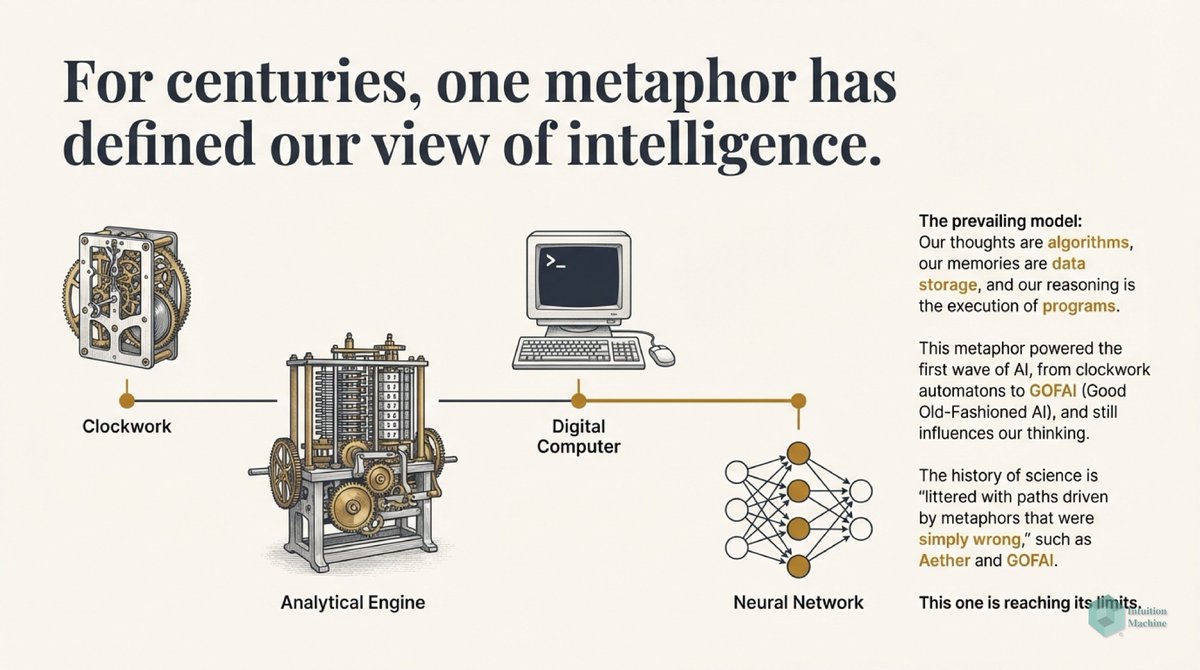








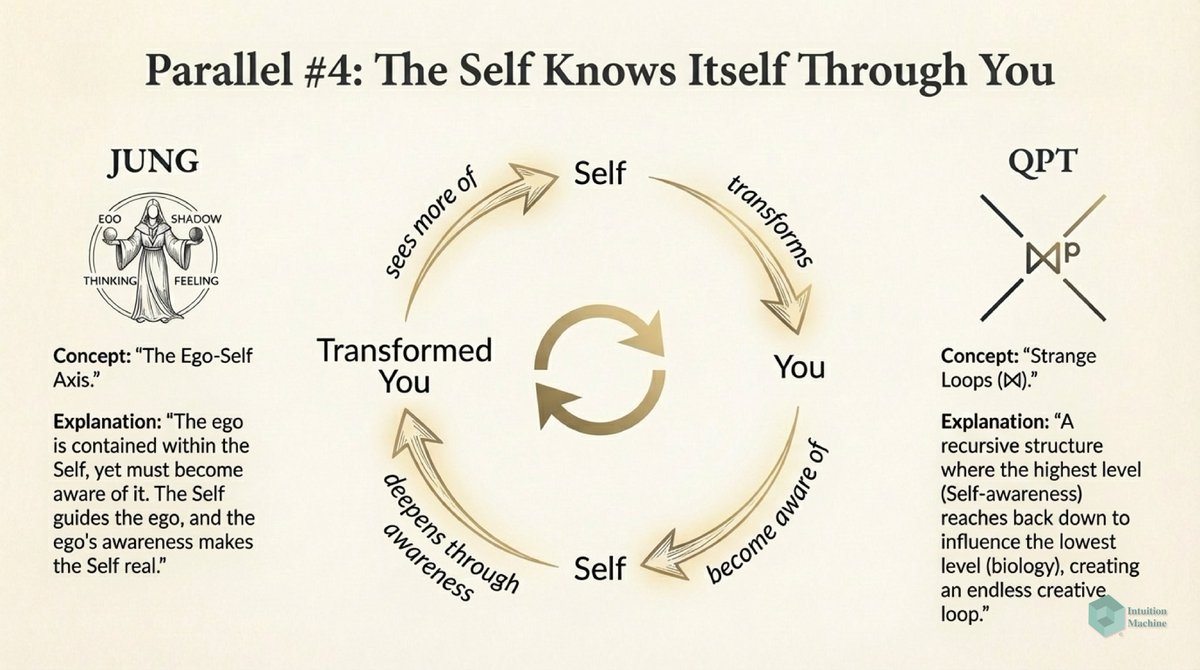
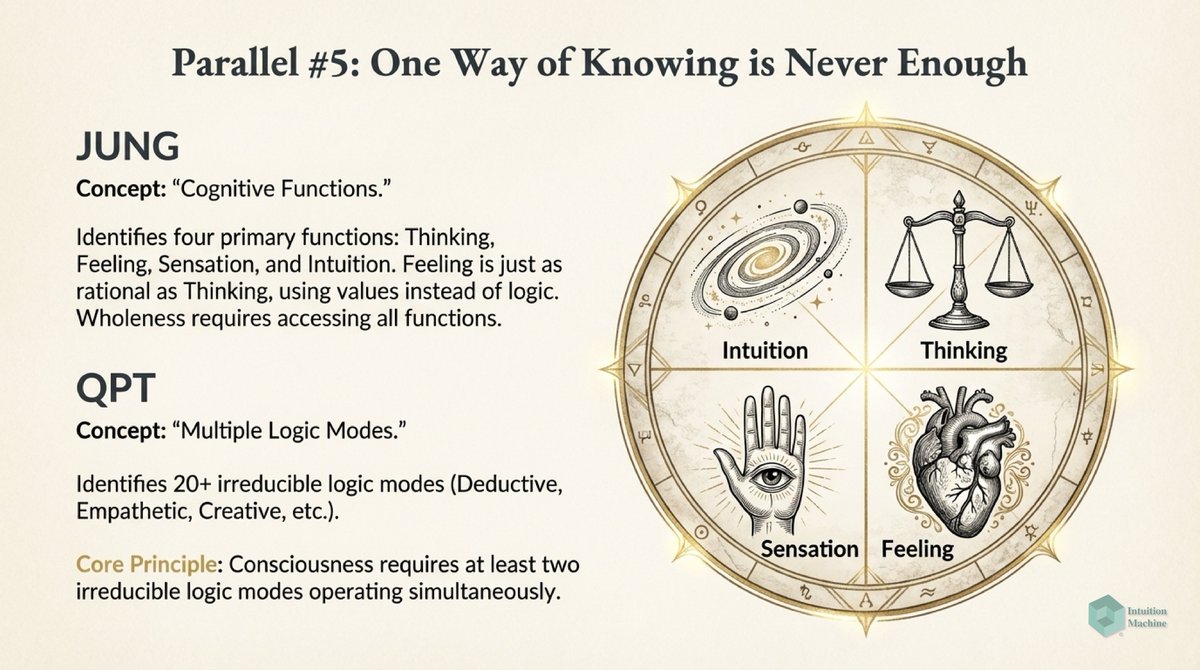

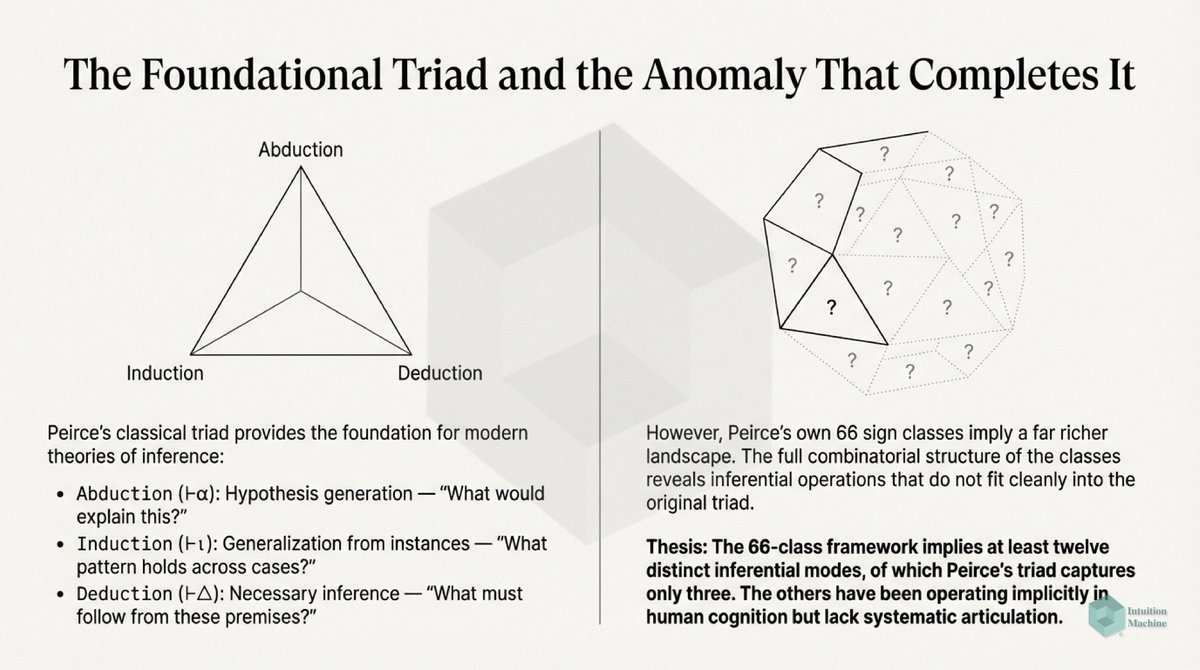
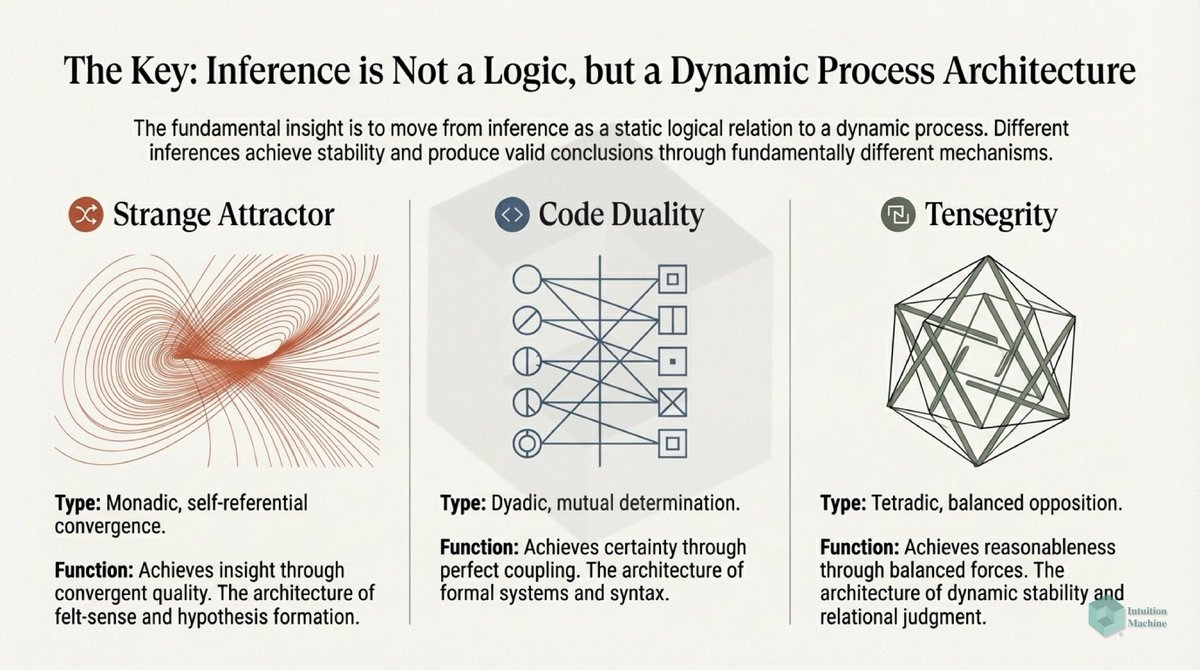
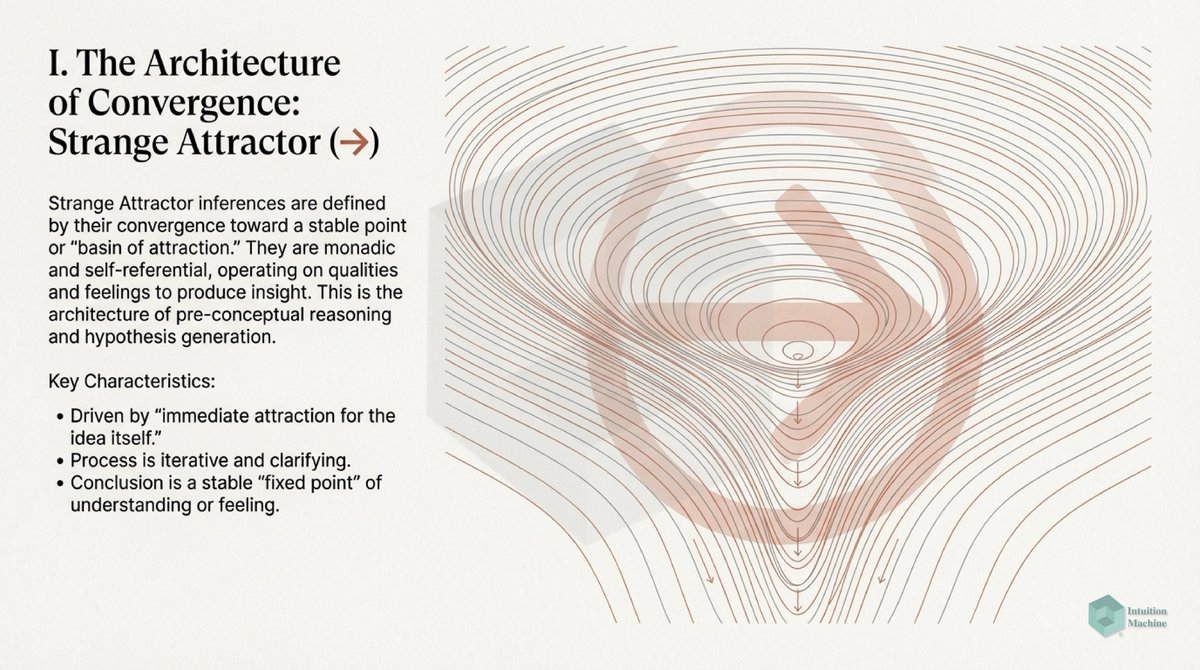


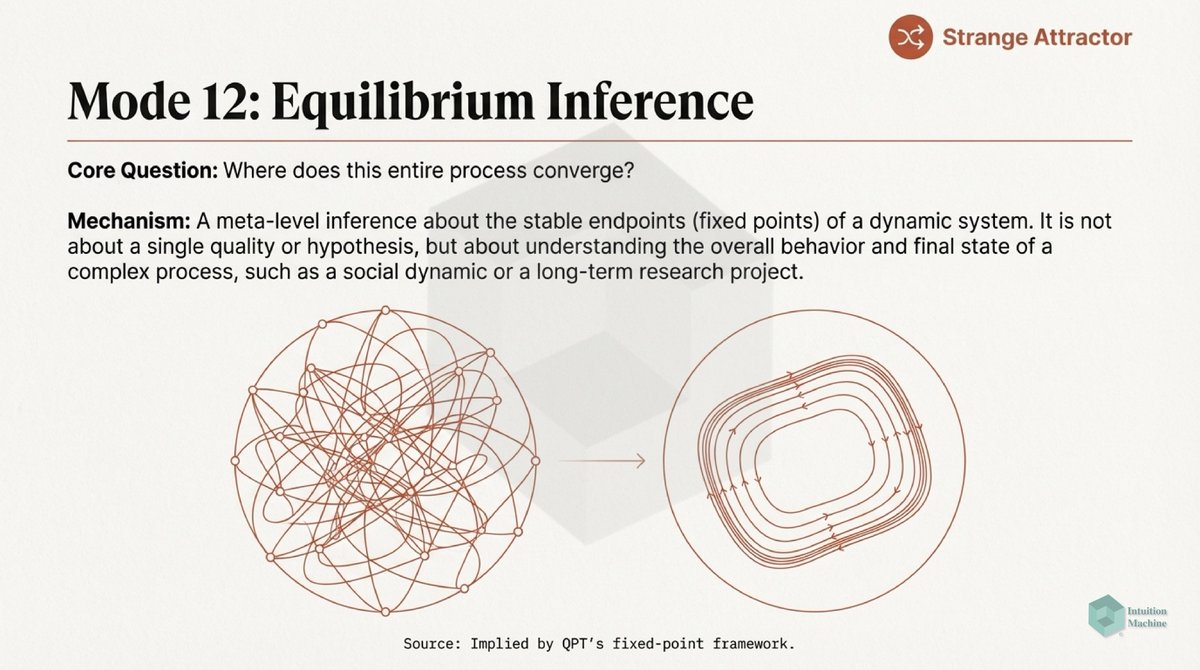
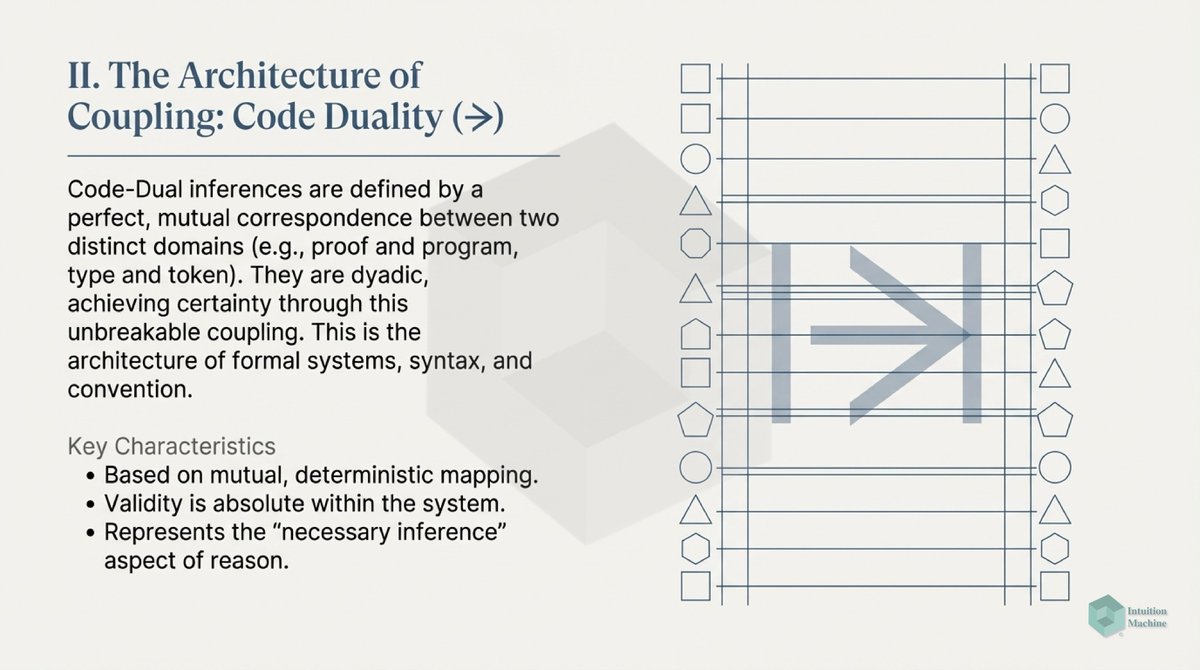
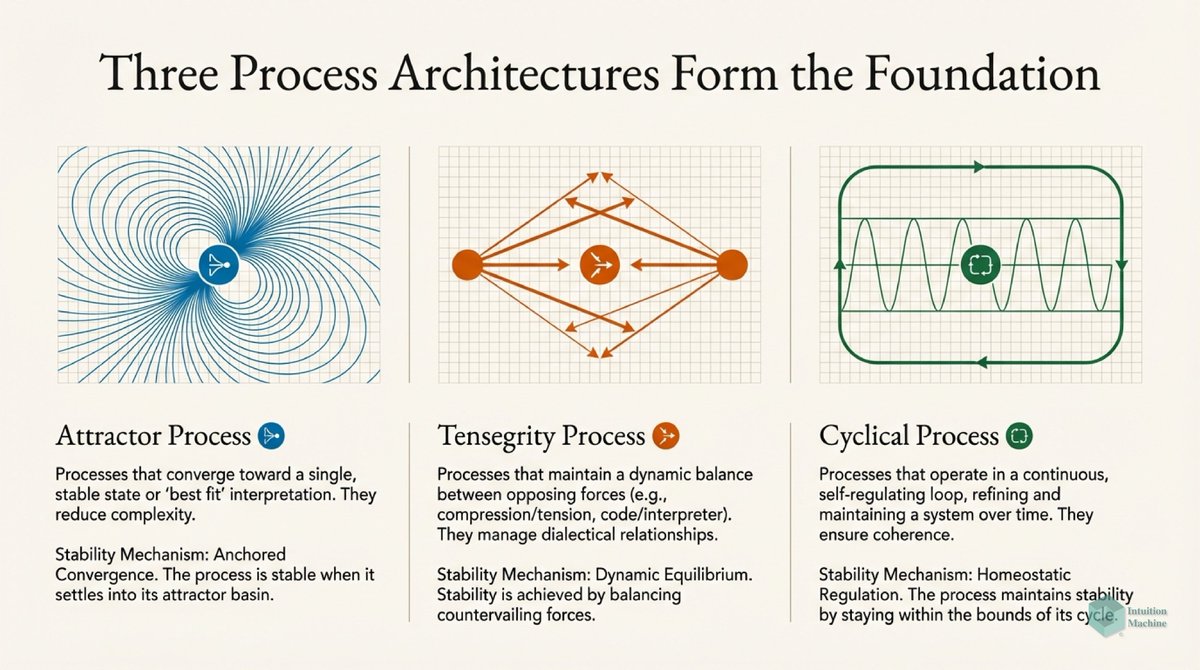


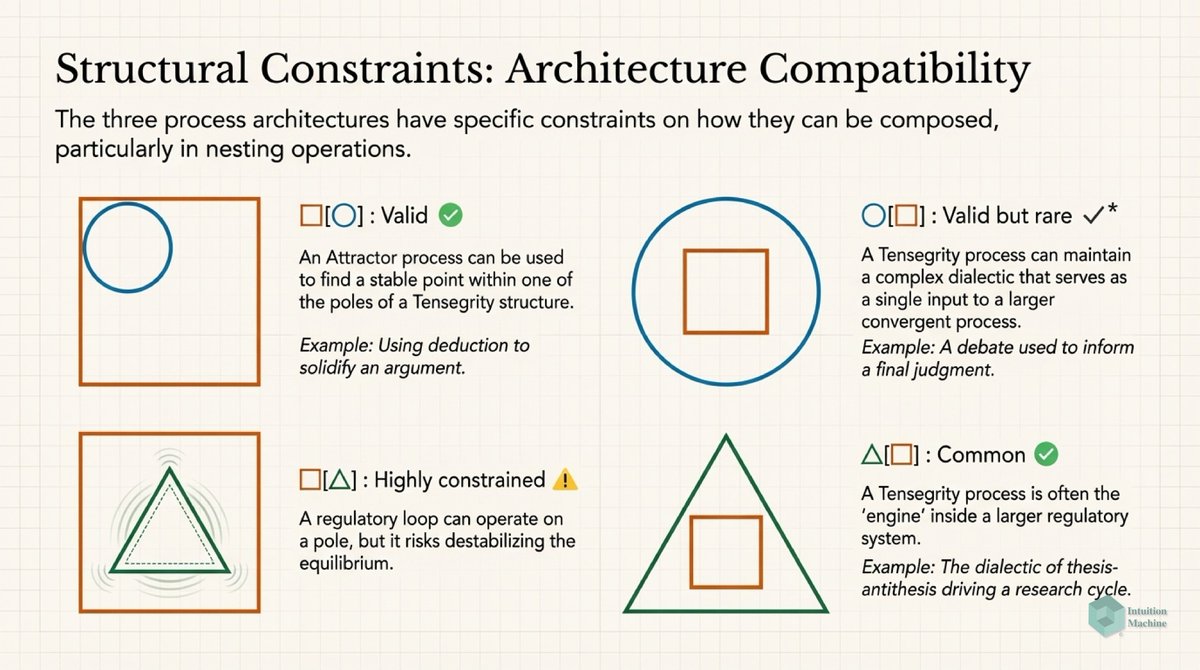

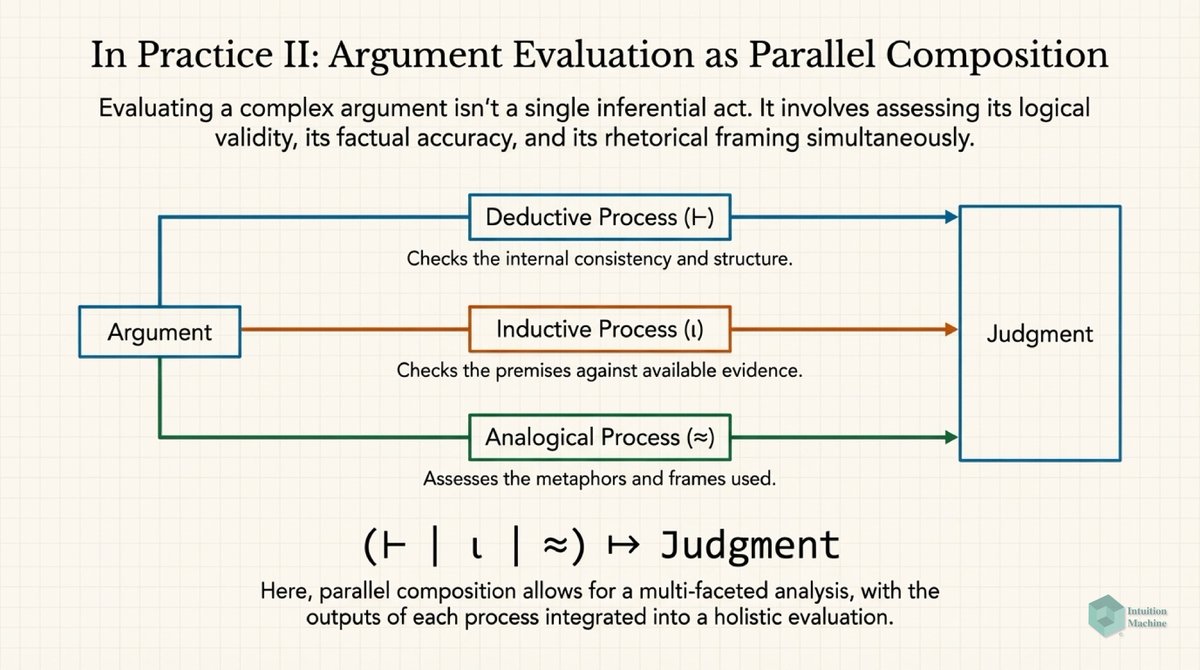

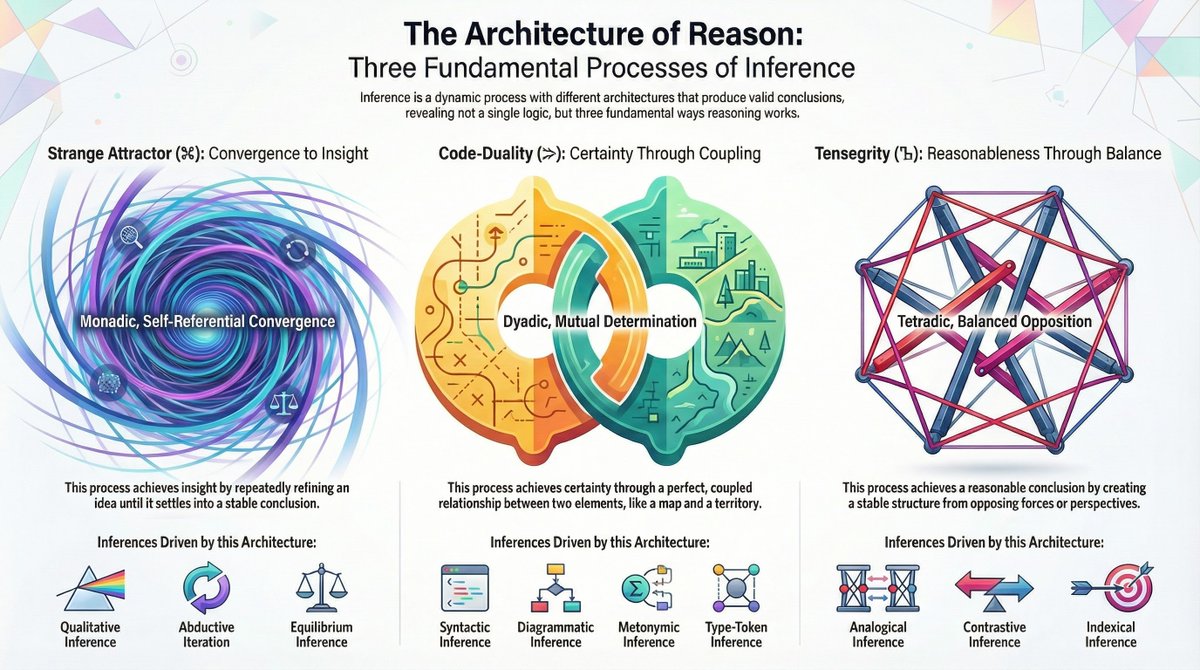 Beyond the classic triad of infrerence
Beyond the classic triad of infrerence 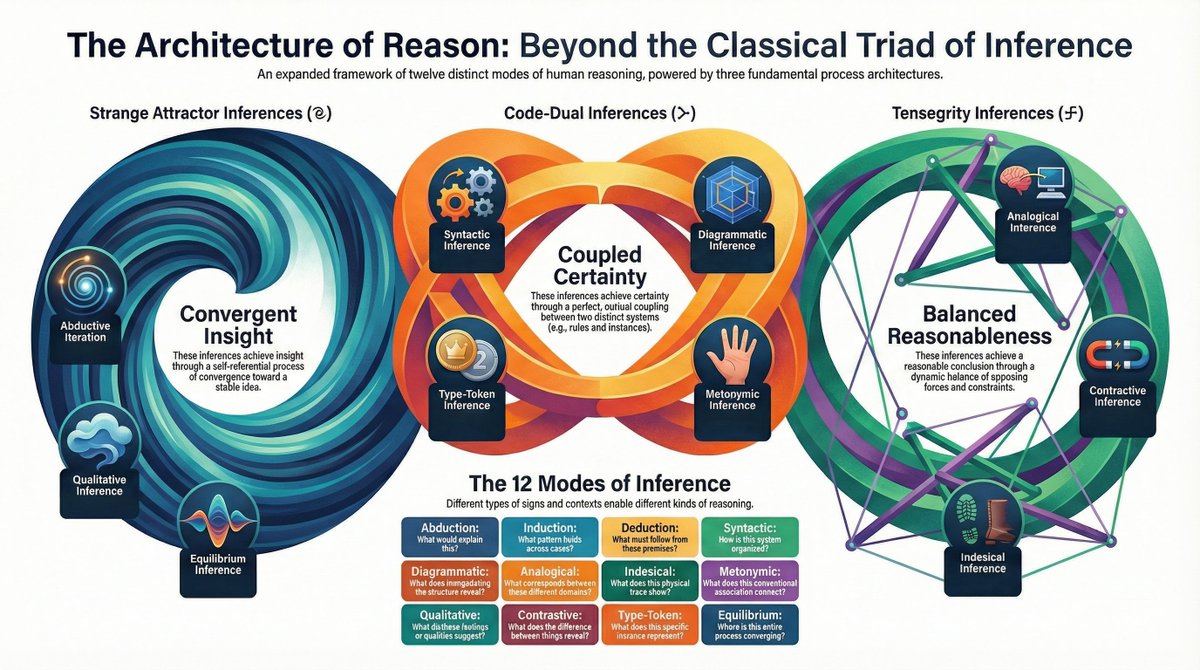
 Seems that if we probe enough, we discover that these systems are building their own world models.
Seems that if we probe enough, we discover that these systems are building their own world models.
 BTW, not my system (rather Poetiq) - Blame the LLM generated text for the error. ;-)
BTW, not my system (rather Poetiq) - Blame the LLM generated text for the error. ;-)
 Seems to parallel the book I wrote in 2023. Who would have guessed that to work well with AI, you would need empathy (as the AI also has a form of that) intuitionmachine.gumroad.com/l/empathy
Seems to parallel the book I wrote in 2023. Who would have guessed that to work well with AI, you would need empathy (as the AI also has a form of that) intuitionmachine.gumroad.com/l/empathy
 Here the mapping to Agentic AI Patterns
Here the mapping to Agentic AI Patterns 


 Here are new patterns not found in the book.
Here are new patterns not found in the book. 
 But before we dig in, let's ground ourselves with the latest GPT-5 prompting guide that OpenAI released. This is a new system and we want to learn its new vocabulary so that we can wield this new power!
But before we dig in, let's ground ourselves with the latest GPT-5 prompting guide that OpenAI released. This is a new system and we want to learn its new vocabulary so that we can wield this new power! 
 More analysis from a dark triad perspective:
More analysis from a dark triad perspective: