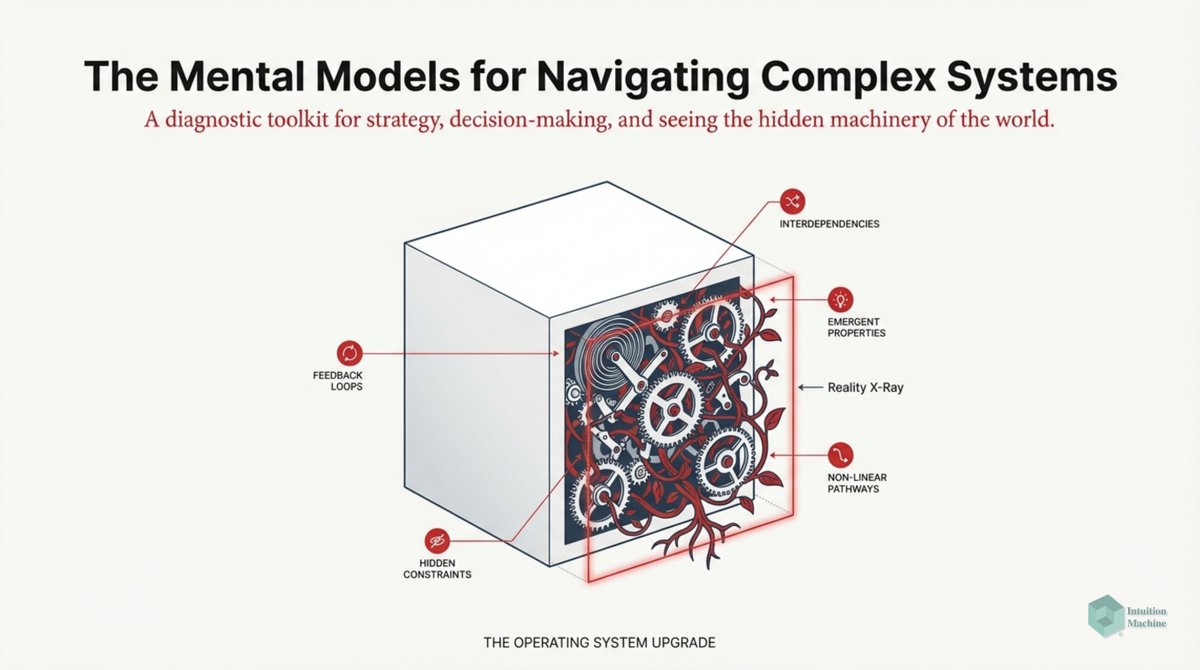
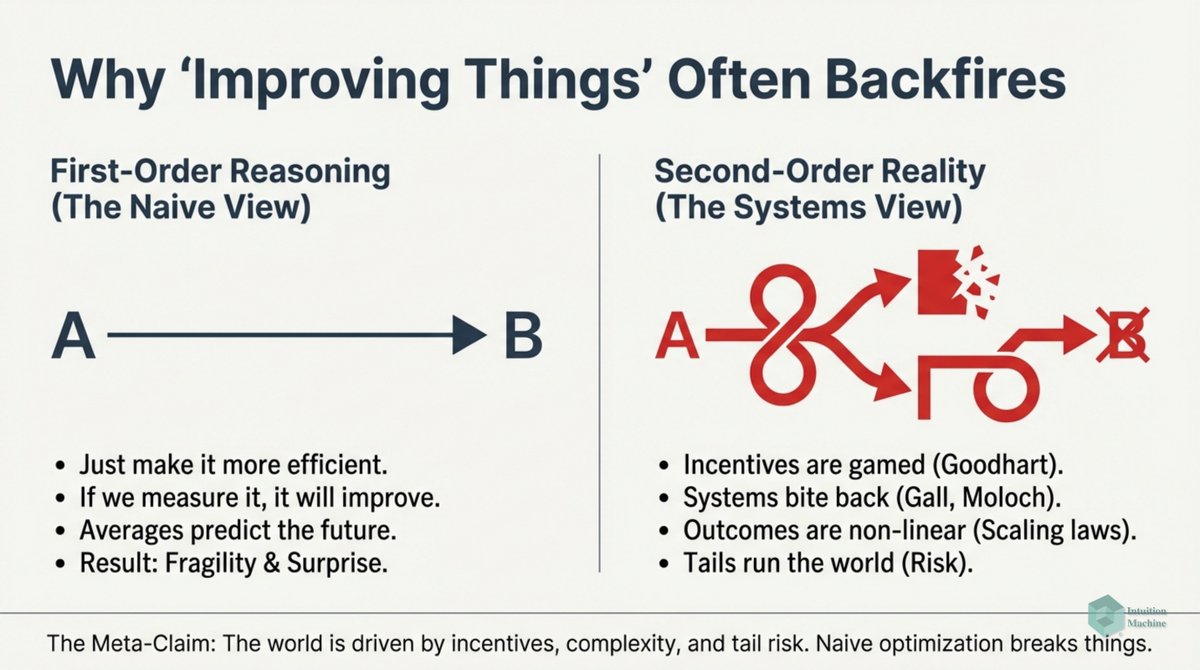
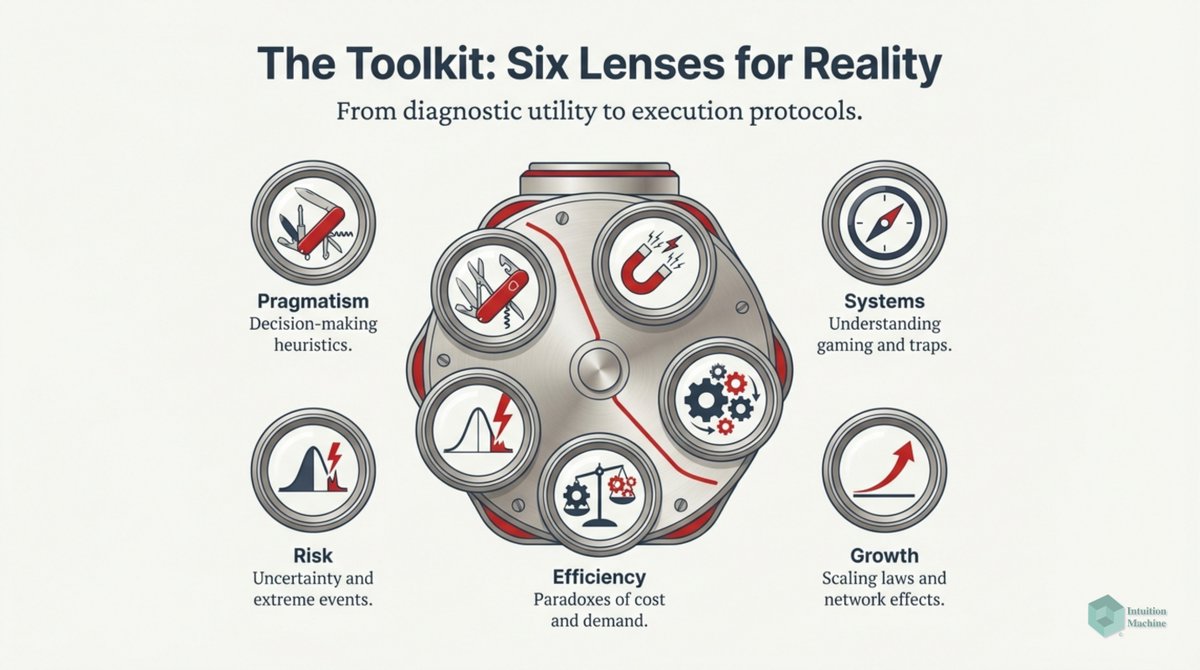
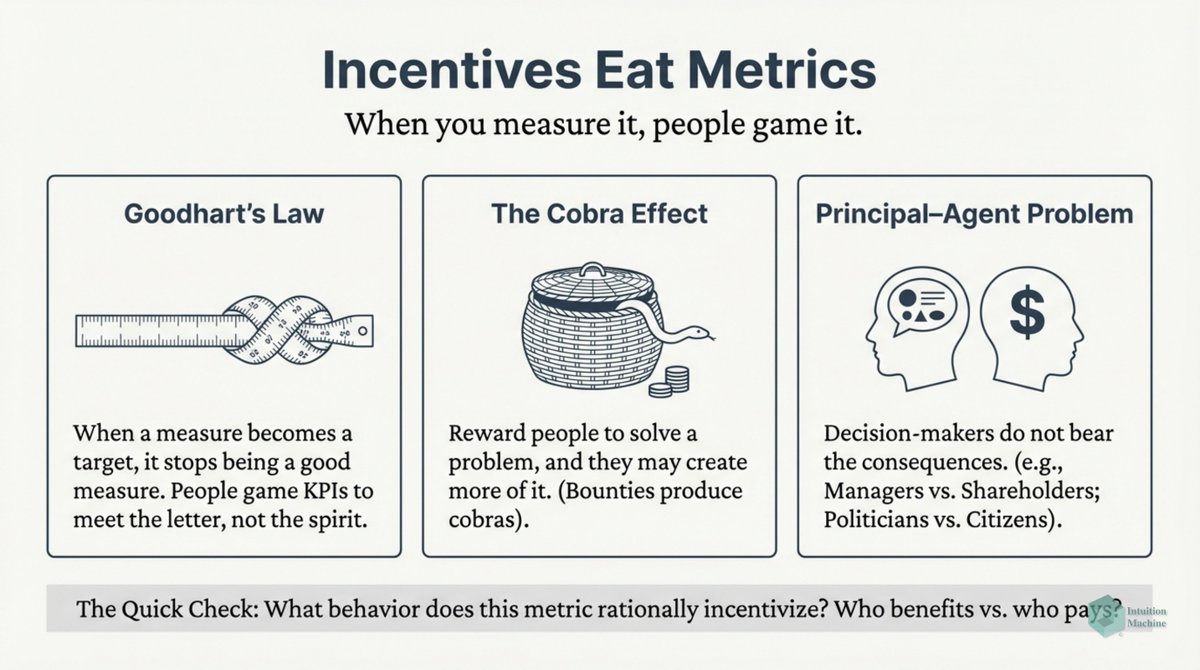
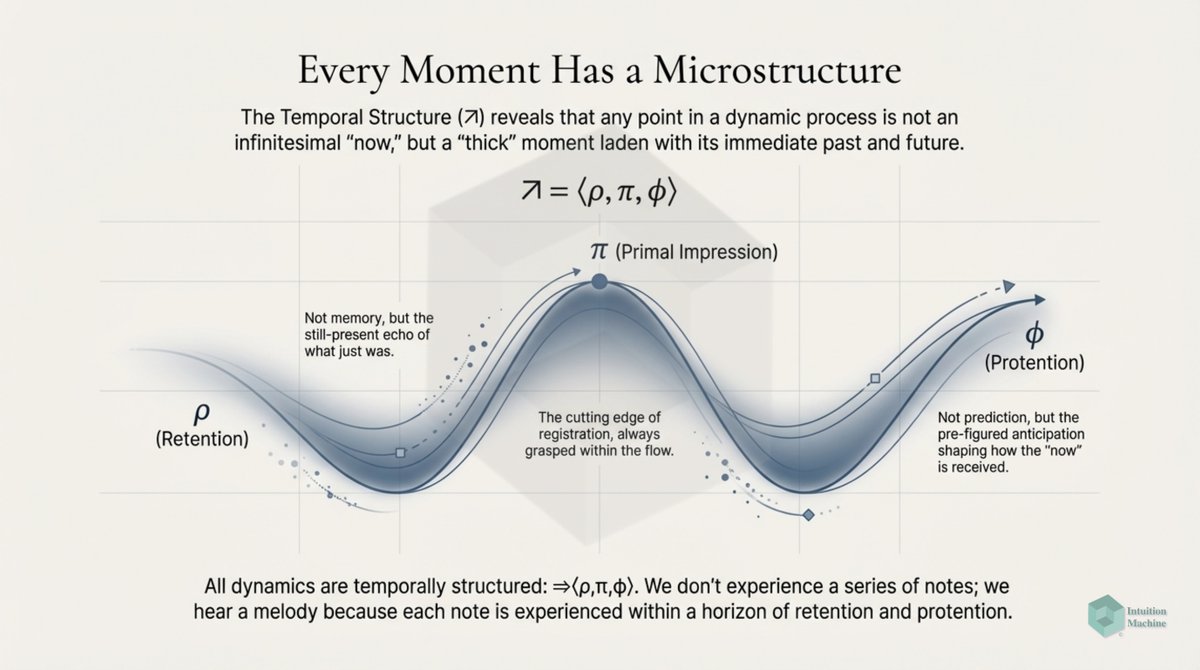
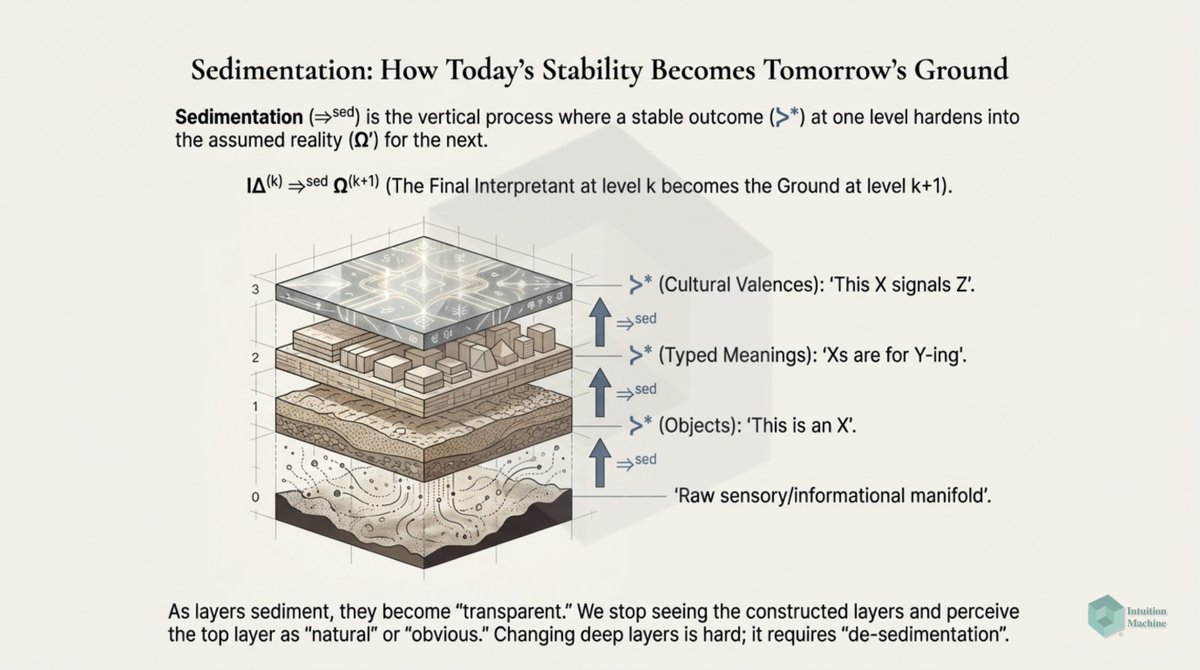
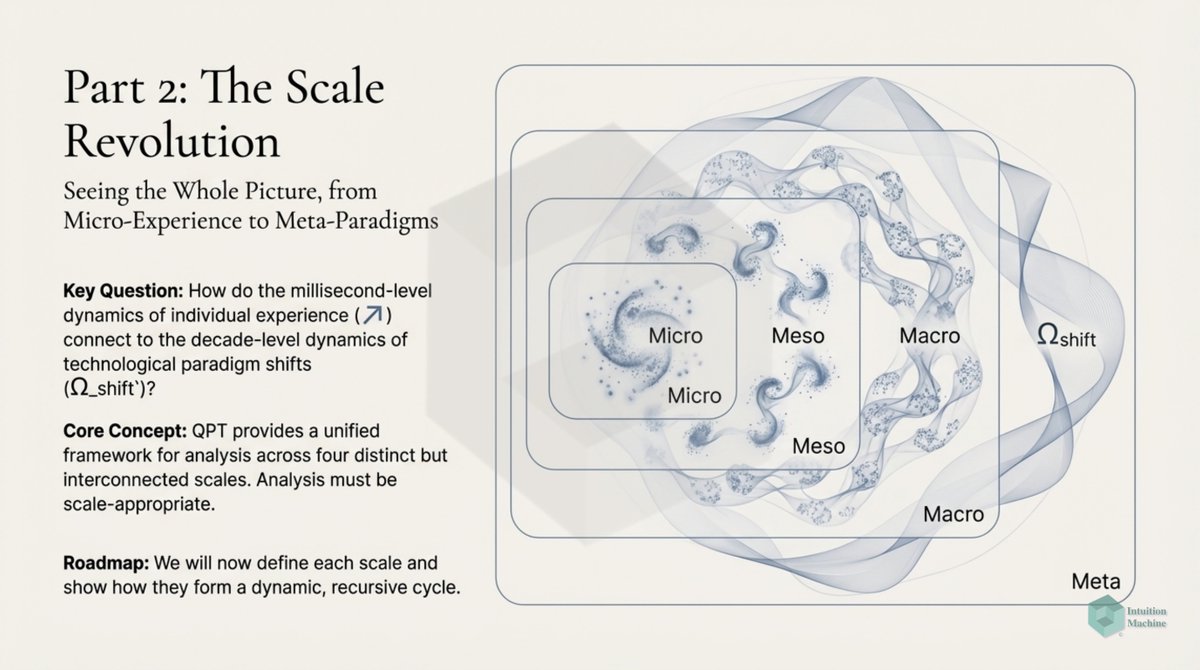
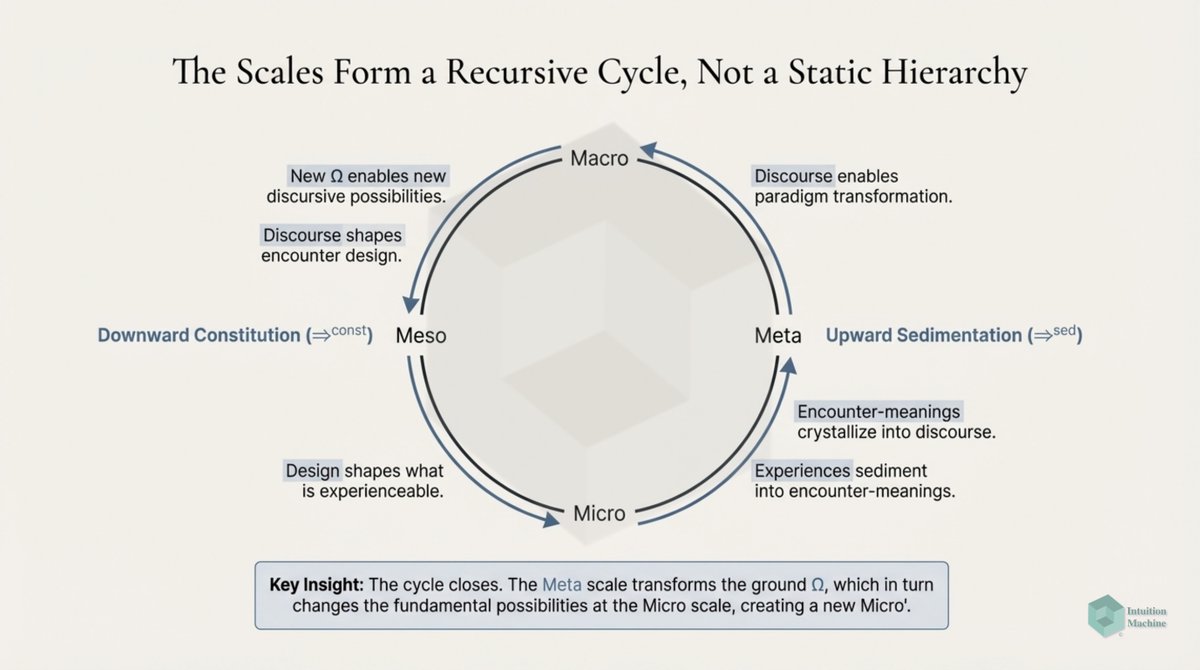
The classic explanation of Deep Learning networks is that each layer creates a different layer that is translated by a layer above it. A discrete translation from one continuous representation to another one.
The learning mechanism begins from the top layers and propagates errors downward, in the process modifying the parts of the translation that has the greatest effect on the error.
Unlike an system that is engineered, the modularity of each layer is not defined but rather learned in a way that one would otherwise label as haphazard. If bees could design translation systems, then they would do it like deep learning networks
The designs of a single mind will look very different from the designs created by thousands of minds. In software engineering, the modularity of our software refect how we organize ourselves. Designs in nature are reflections of designs of thousands of minds.
To drive greater modularity and thus efficiencies, minds must coordinate. Deep Learning works because the coordination is top-down. Error is doled down the network in a manner proportional to a node's influence.
In swarms of minds, the coordination mechanism is also top-down in a shared understanding among its constituents. Ants are able to build massive structures because they are driven by shared goals that have been tuned through millions of years of evolution.
Societies are coordinated through shared goals that are communicated while growing up in society and through our language. There are overarching constraints that drive our behavior that we are so habitually familiar with that we fail to recognize it.
As C.S. Peirce has explained, possibilities lead to habits. Habits lead to coordination and thus a new emergence of possibilities. Emergence is the translation of one set of habits into another emergent set of habits.
In effect, we arrive at different levels of abstraction where each abstraction is forged by habit. The shape of the abstraction is a consequence of the regularity of the habits. Regularity is an emergent feature of the usefulness of a specific habit.
We cannot avoid noticing self-referential behavior. Emergent behavior a bottom-up phenomena, however the resulting behavior may lead to downward causation. To understand this downwards causation it is easy to make the analogy of how language constrains our actions.
The power of transformer models in deep learning is they define blocks of transformation that force a discrete language interpretation of the underlying semantics. This is a departure from the analog concept of brains that has historically driven connectionist approaches.
When we have systems that coordinate through language we arrive at systems more robust in their replication of behavior. Continuous non-linear systems without scaffolding with language do not lead to reliably replicate-able behavior.
Any system that purports to lead towards intelligence must be able to replicate behavior and therefore must have substrates that involve languages. Dynamical systems are not languages. Distributed representations are not languages.
The robustness of languages are that they are sparse and discrete. However, it is a tragic mistake to believe that language alone is all we need. Semantics of this world can only be captured by continuous analog systems.
This should reveal to everyone what is obvious and in plain sight. An intelligent system requires both a system of language and a system of dynamics. There is no-living thing in this planet that is exclusively one or the other.
Living things are non-linear things, but non-living things maintain themselves by employing reference points. These reference points are encoded in digital form for robustness. If this were not true, then the chaotic nature of continuous systems will take over.
Our greatest bias and this comes from physics is the notion that the universe is continuous. But as we examine it at shorter distances, the discrete implicate order incessantly perturbs this belief.
We are after all, creatures of habits and it's only the revolutionaries who are able to break these habits. But what's the worse kind of mental habit? The firstness of this is to see the world only as things, the secondness is to see the world only as dualities...
the thirdness is to see reality as unchanging. Homo sapiens have lived on this earth for 20,000 generations. We can trace our lack of progress as a consequence of these mental crutches. Things, dualities and the status quo are what prevent us from progress.
These are all discrete things, it is these discrete things that keep things the same. It is these discrete things that keep order. These are the local minima that keep us from making progress. But it is also these local minima that give us a base camp.
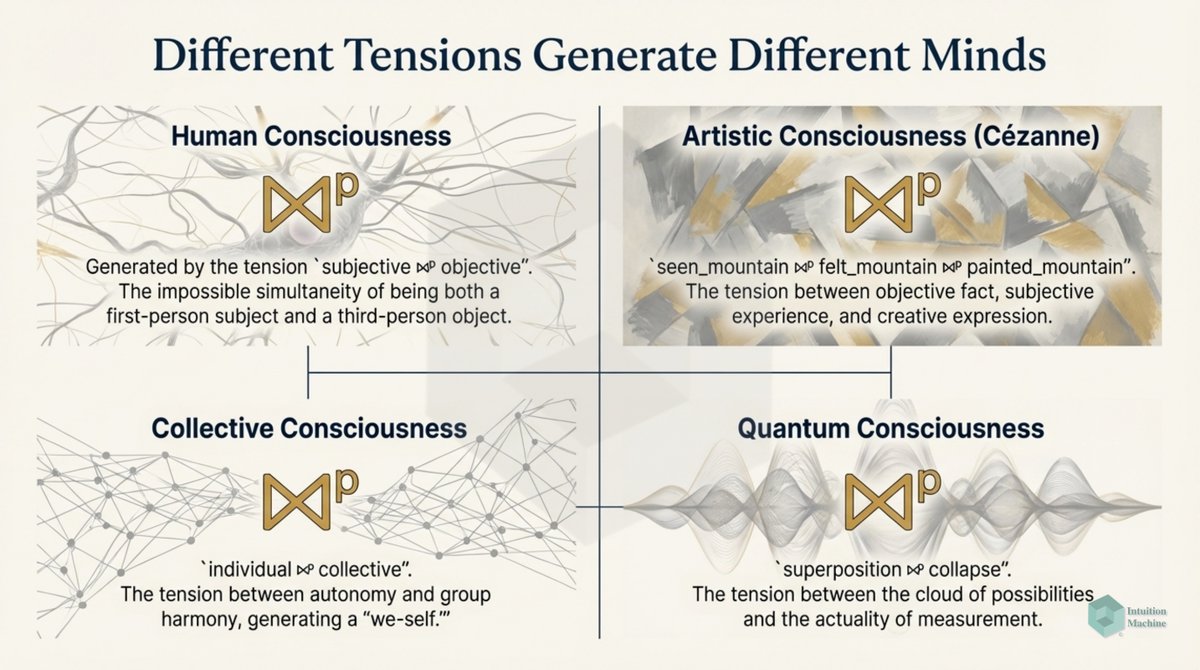
The interesting about discrete things is that there a no tensions or conflicts. But it is tension and conflict that drive progress. We can only express the semantics of tension and conflict in terms of continuity.
Between two extremes of a duality exists whatever is in the middle. The stuff that the excluded middle of logic ignores entirely. If we habitually think only of dualities, we habitually ignore the third thing that is always there.
If there are two extremes, there is a third thing that is tension. It is in this tension that you have dynamics. Absent any tension then there's static. In short, deadness. Our dualistic thinking forces us to device models of dead things.
Dead things are things in equilibrium. Things where the central limit theorem holds. Prigogine argued that living things are far from equilibrium. What he should have said was that living things are in constant tension and conflict.
So to make progress in understanding our complex world we must embrace the language of processes, triadic thinking and dynamics. That is, to break our habits we must use methods that do break habits.
@threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh