Let's talk about rendering a massive set of cubes efficiently... 
Geometry shaders and instanced draw are unoptimal choices. Geometry shader outputs strips (unoptimal topology) and it needs GPU storage and load balancing. Instanced draw is suboptimal on many older GPUs for small 8 vertex / 12 triangle instances.
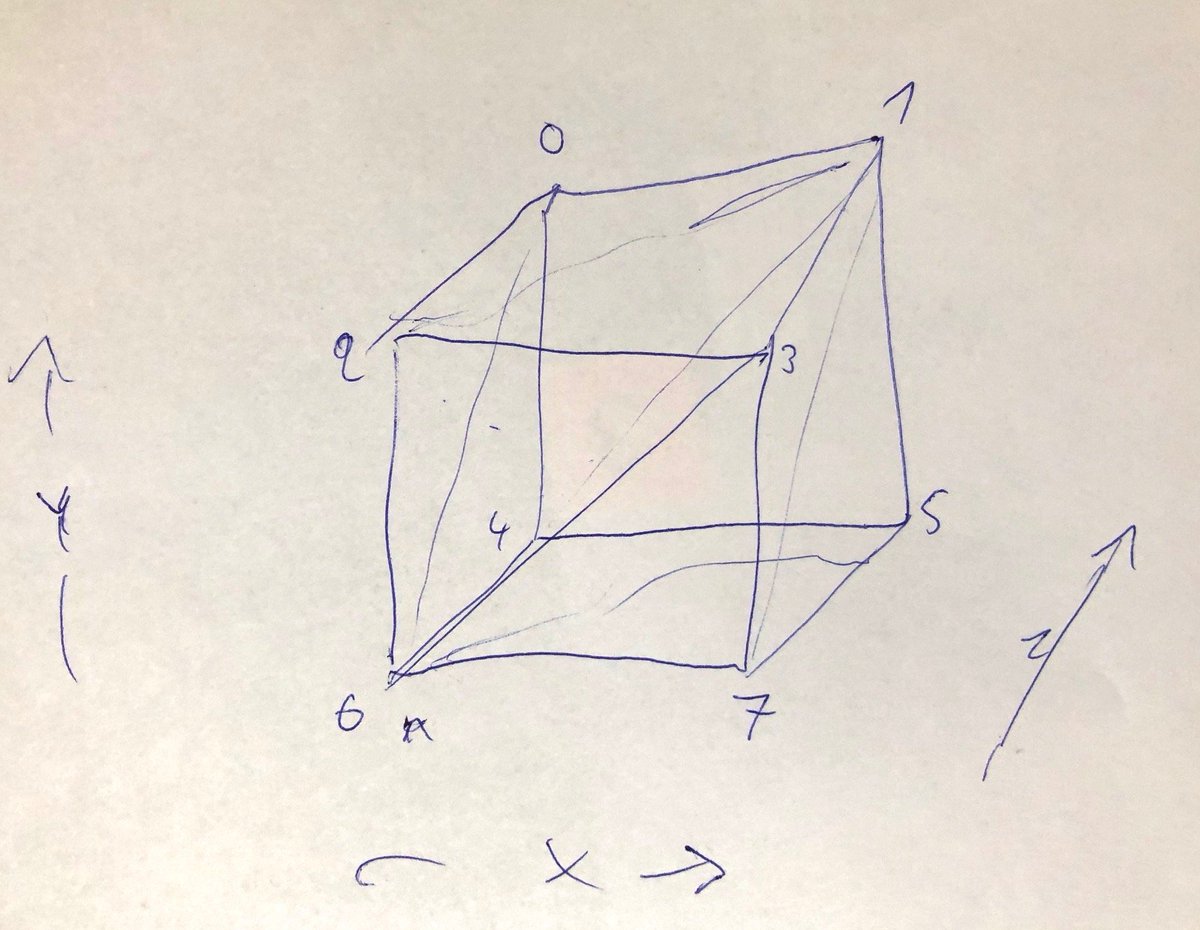
The most efficient way to render a big amount of procedural cubes on most GPUs is the following: At startup you fill an index buffer with max amount of cubes. 3*2*6 = 36 indices each (index data = 0..7 + i*8). Never modify this index buffer at runtime.
No vertex buffer. You use SV_VertexId in the shader. Divide it by 8 (bit shift) to get cube index (to fetch cube position from an array). The low 3 bits are XYZ bits (see OP image). LocalVertexPos = float3(X*2-1, Y*2-1, Z*2-1). This is just a few ALU in the vertex shader.
Use indirect draw call to control the drawn cube count from GPU side. Write the (visible) cube data (position or transform matrix, or whatever you need) to an array (UAV). This is indexed in the vertex shader (SRV).
There's an additional optimization: Only 3 faces of a cube can be visible at once. Instead generate only 3*2*3=18 indices per cube (positive corner). Calculate vec from cube center to camera. Extract XYZ signs. Flip XYZ of the output vertices accordingly...
If you flip odd number of vertex coordinates, the triangle winding will get flipped. Thus you need to fix it (read triangle lookup using "2-i") if you have 1 or 3 flips. This is just a few extra ALU too. Result = you are rendering 6 faces per cube, thus saving 50% triangle count.
The index buffer is still fully static even with this optimization. It's best to keep the index numbering 0..7 (8) per cube even with this optimization to be able to use bit shift instead of integer divide (which is slow). GPU's do index dedup. Extra "slot" doesn't cost anything,
Benchmark results and code here:
https://twitter.com/SebAaltonen/status/1322594445548802050?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh