
Building a new renderer at HypeHype. Former principal engineer at Unity and Ubisoft. Opinions are my own.
 Discard in a shader seems innocent, but that makes the GPU driver do crazy shit. Even if you branch out the discard, the driver must be prepared for it, because it doesn't know the runtime state.
Discard in a shader seems innocent, but that makes the GPU driver do crazy shit. Even if you branch out the discard, the driver must be prepared for it, because it doesn't know the runtime state.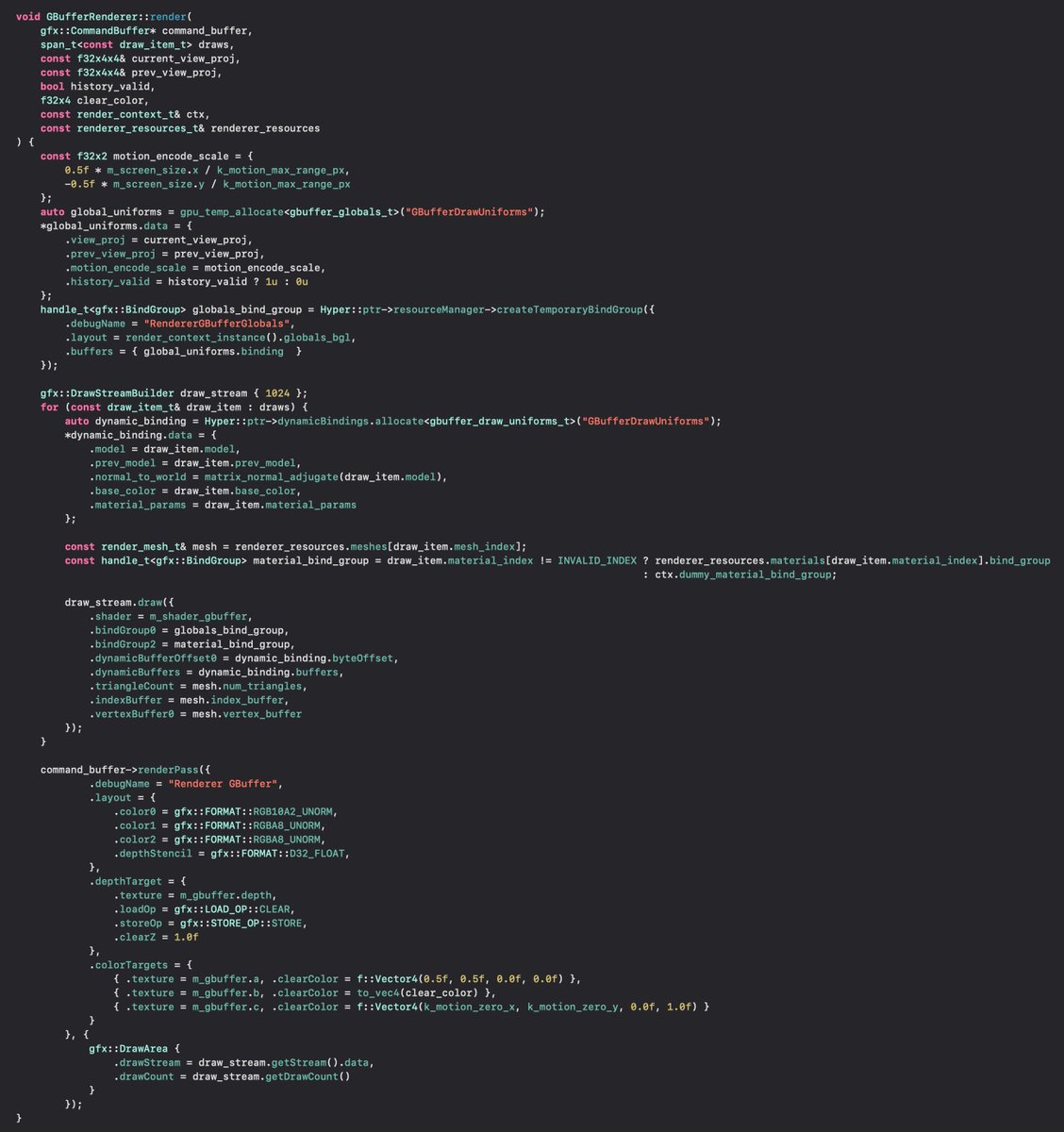 gpu_temp_allocator (and dynamicBindings.allocate) bump allocate persistently mapped GPU memory. CPU pointer directly to GPU VRAM (PCIE-Rebar or UMA). Uniform are directly written to VRAM. No copies at all. Draw stream has only bind group handles and PSO handles (32-bit).
gpu_temp_allocator (and dynamicBindings.allocate) bump allocate persistently mapped GPU memory. CPU pointer directly to GPU VRAM (PCIE-Rebar or UMA). Uniform are directly written to VRAM. No copies at all. Draw stream has only bind group handles and PSO handles (32-bit).
 I was talking about 100,000 players before, but that's an aspirational goal for a real MMO game with paid customers. 10,000 players is a fine start point for prototyping. Will be difficult to even get that many players even if it's a free web game (no download).
I was talking about 100,000 players before, but that's an aspirational goal for a real MMO game with paid customers. 10,000 players is a fine start point for prototyping. Will be difficult to even get that many players even if it's a free web game (no download).


 This is how you would use the API to dispatch a compute pass with a single compute shader writing to two SSBOs.
This is how you would use the API to dispatch a compute pass with a single compute shader writing to two SSBOs. 
