
1/ Last week we did a deep dive of @github's authorization model and the problems they solve
In this thread we'll focus on another well known product: @googledrive a great example of a collaboration platform.
📊How is gdrive "authorization at scale"?
https://twitter.com/Auth0Lab/status/1324438240338825223?s=20
In this thread we'll focus on another well known product: @googledrive a great example of a collaboration platform.
📊How is gdrive "authorization at scale"?
2/ Well, in 2018 they:
- hit 1B users
- 2 trillion files
techcrunch.com/2018/07/25/goo…
We'll:
🔐 Review their permission model
🔍Go over their "search" story and how authz fits in it
🎯Analyze examples of why "correctness" (
- hit 1B users
- 2 trillion files
techcrunch.com/2018/07/25/goo…
We'll:
🔐 Review their permission model
🔍Go over their "search" story and how authz fits in it
🎯Analyze examples of why "correctness" (
https://twitter.com/Auth0Lab/status/1324438281300434945?s=20) is important
3/ Like github, @googledrive has B2C and B2B models. However, @googledrive's sharing model is the same for B2C and B2B. The difference is who you can share files with.
4/ For both models you can have:
- Restricted sharing, i.e.: with a google account that you allow
- Anyone with the link sharing
🏢The B2B model includes
- the ability of link sharing within your organization
- the option to restrict sharing publicly
support.google.com/drive/answer/2…
- Restricted sharing, i.e.: with a google account that you allow
- Anyone with the link sharing
🏢The B2B model includes
- the ability of link sharing within your organization
- the option to restrict sharing publicly
support.google.com/drive/answer/2…

5/ There are five concentric roles a user might have on an object (file or folder):
- Owner/Organizer
- File organizer (shared drive only)
- Editor
- Commenter (for files)
- Viewer
- Owner/Organizer
- File organizer (shared drive only)
- Editor
- Commenter (for files)
- Viewer

6/ Permission propagation happens between folders and files (developers.google.com/drive/api/v3/m…): if you are a viewer in a folder, you can view its documents. This applies even when you are not explicitly a viewer in a document.
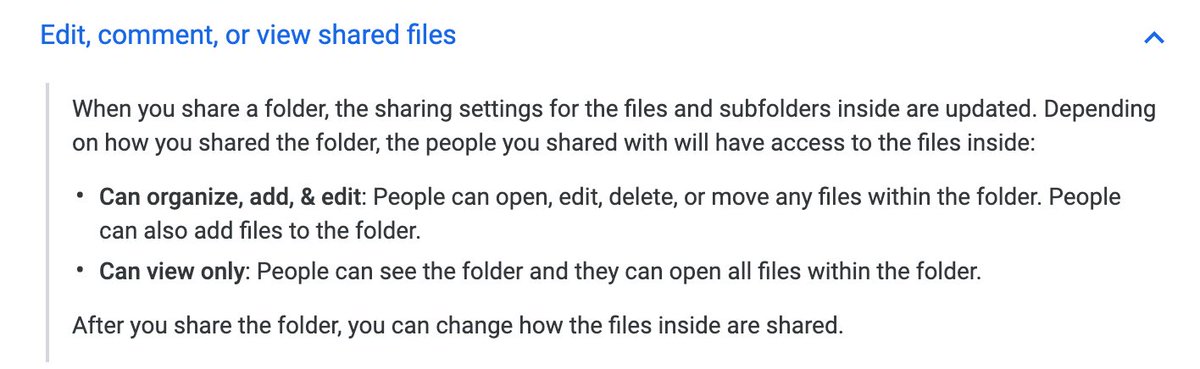
7/ As we mentioned last time, flexibility is 🔑:
You can remove some abilities on a specific doc for ALL users: support.google.com/drive/answer/2…
And grant permissions on file "views"
https://twitter.com/Auth0Lab/status/1324438266439995395?s=20. Document level granularity + ancestor propagation is a powerful combination.
You can remove some abilities on a specific doc for ALL users: support.google.com/drive/answer/2…
And grant permissions on file "views"


8/ 🔍A big part of @googledrive's value prop is "search". Drive's search UX is great. Have you ever thought about what search's needs are from Authz?
You shouldn't get any results back if you don't have permissions for them.
You shouldn't get any results back if you don't have permissions for them.

9/ If a file's name is "Plan to fire Sue" and you're Sue, not only should you not be able to access it, but it should not show up in search results 😅
In a workspace with 100k+ documents, each search request has perms checked for all potential matches. That is scale! 🚀
In a workspace with 100k+ documents, each search request has perms checked for all potential matches. That is scale! 🚀
10/ Checking one permission at a time for each user operation is simple compared to the massive burden of hundreds/thousands of requests per search.
🔑 Any system that solves "authorization at scale" needs to solve the search problem!
🔑 Any system that solves "authorization at scale" needs to solve the search problem!
11/ On a different note, @googledrive has done a great job at spoiling us with its sharing UX. You share a file with someone, send them a link half way across the world and they will be able to open it immediately!
This has important implications from a security perspective.
This has important implications from a security perspective.
11/ Imagine if this wasn't the case, and instead it took 5 minutes to propagate changes. Some interesting (and potentially uncomfortable/insecure) situations could arise.
12/ Let's analyze some potential edge case problems considering a distributed workforce (and a thus a VERY distributed system):
🇺🇸 Anne lives in LA
🇧🇷 Bela and Caio live in São Paulo. They report to Anne
🇺🇸 Anne lives in LA
🇧🇷 Bela and Caio live in São Paulo. They report to Anne
13/ Situation 1️⃣: Anne
1. Removes Caio from the document "Confidential" as a viewer.
2. Adds Bea as a document writer.
3. Bea makes an update to the document that Caio should not be able to see.
1. Removes Caio from the document "Confidential" as a viewer.
2. Adds Bea as a document writer.
3. Bea makes an update to the document that Caio should not be able to see.
14/ What happens if the update for 2 is replicated from the US to Brazil before permission update 1? Under a simple eventual consistency model, there are no guarantees for causal ordering in replication.
15/ Thus: *Caio might be able to read data he is not supposed to* because "from Brazil's datacenter perspective Bea can write in before Caio has been removed as a reader".
⚠️Problem 1: replication with no notion of causal ordering might lead to security issues.
⚠️Problem 1: replication with no notion of causal ordering might lead to security issues.
16/ But, if we solve causal ordering in replication but keep eventual consistency we are not safe:
Situation 2️⃣: Anne fires Bea. She lets her know at 5:00 PM and removes her permissions.
If propagation takes "at most" 5 mins, Bea could delete company data at 5:02 PM UTC.
Situation 2️⃣: Anne fires Bea. She lets her know at 5:00 PM and removes her permissions.
If propagation takes "at most" 5 mins, Bea could delete company data at 5:02 PM UTC.
17/ ‼️ Once Anne gets confirmation that Bea's permissions have been removed, Bea should no longer be able to access documents.
⚠️Problem 2: eventual consistency in permission replication can lead to security issues.
⚠️Problem 2: eventual consistency in permission replication can lead to security issues.
18/ 🔑To solve distributed authorization at scale, a system must support strong consistency when necessary, allowing for more lenient models when business cases allow it. We'll refer to this characteristic as "correctness".
19/ If you are interested in more details about how @google's permission system works (including @googledrive) the Zanzibar paper is a great resource: research.google/pubs/pub48190/.
20/ 👋We hope you found these analysis of different products from an AuthZ perspective interesting. We'd love to hear your thoughts here or @discord discord.gg/XbQpZSF2Ys
Later this week, we'll share a bit of what we are seeing in the authorization market. Stay tuned!
Later this week, we'll share a bit of what we are seeing in the authorization market. Stay tuned!
• • •
Missing some Tweet in this thread? You can try to
force a refresh


