
Great thread. The dominance of Likert-type outcome measures means that most psychologists don't actually know what a non-arbitrary measure looks like. So here's a thread on how we can make our measures less arbitrary: 1/n
Blanton & Jaccard's (2006) paper revolutionised my thinking about effect sizes and meaningful metrics in psychology. I highly recommend it. psycnet.apa.org/record/2006-00… 2/n 

Their key argument is that a metric is arbitrary when it provides no information about where a person is located on the true underlying continuum, or what a 1-unit change means. 3/n
For example, we can generally conclude that a person who scores "9" on a 10-point life satisfaction scale is happier than someone who scores "8", but what are the concrete implications of a 1-unit difference for a person's functioning? 4/n
It is possible to make metrics less arbitrary by calibrating them to meaningful real-world outcomes. Doing so can help us better understand the behavioral implications of commonly-used self-report measures. 5/n
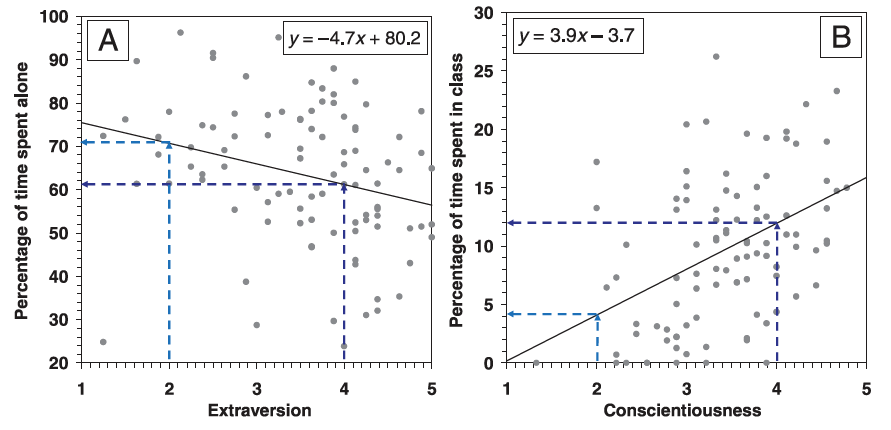
For e.g., Matthias Mehl has used audio recordings of real behavior to show that scoring "4" vs. "2" on measures of extraversion and conscientiousness translated into 10% less time spent alone & 3x more time spent in class, respectively doi.org/10.1111/j.1751… 6/n
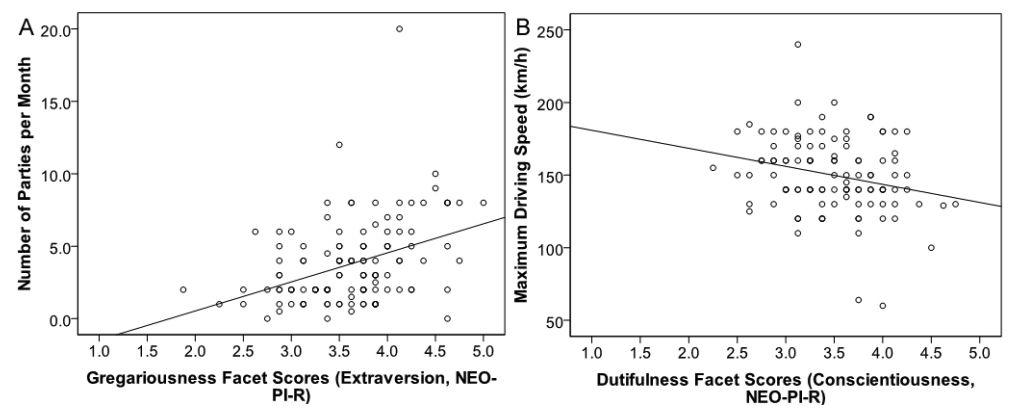
@eplebel's dissertation showed that a 1-unit increase in gregariousness and dutifulness translated into attending two more parties per month & 12 km/h slower maximum driving speed, respectively. ir.lib.uwo.ca/etd/174/ 7/n
My dissertation (see Chapter 6) showed, for e.g., that a 1-unit increase in life satisfaction & narcissism translated into 0.38% fewer conversations in which the participant complained & 0.10% more conversations in which they bragged. thesiscommons.org/aj94u 8/n
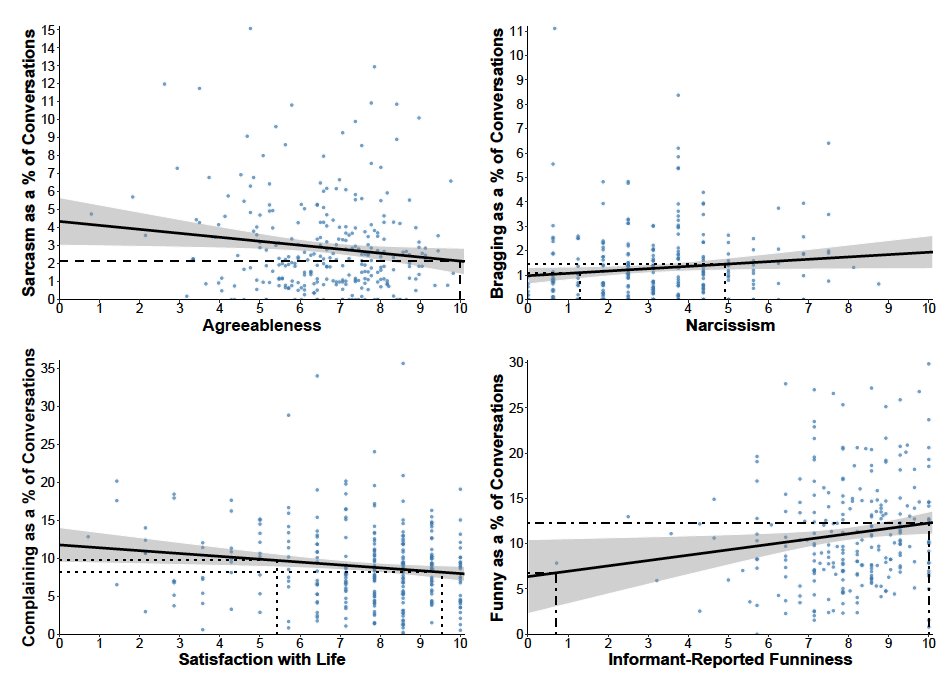
These results provide much-needed context on the meaning of a r = -.27 correlation b/t extraversion & time spent alone or a r = -.15 correlation b/t life satisfaction & conversations spent complaining. 9/n
These kinds of efforts at metric calibration are rare, but are crucial if we are to better understand the practical, real-world implications of higher and lower scores on widely-used self-report measures. Go forth and calibrate! 10/10
Just discovered my failed quote-tweet! This is the "great thread" I was referring to. Oops 😅 11/10
https://twitter.com/BrentWRoberts/status/1332769974201569281
• • •
Missing some Tweet in this thread? You can try to
force a refresh


