
How can we turn causal videos into 3D? Excited to share our work on Robust Consistent Video Depth Estimation.
Project: robust-cvd.github.io
Paper: arxiv.org/abs/2012.05901
w/ @JPKopf @jastarex
Check out the 🧵below!
Project: robust-cvd.github.io
Paper: arxiv.org/abs/2012.05901
w/ @JPKopf @jastarex
Check out the 🧵below!
We start by examining our Consistent Video Depth Estimation (CVD) in SIGGRAPH 2020 (work led by the amazing @XuanLuo14).
roxanneluo.github.io/Consistent-Vid…
The method achieves AWESOME results but requires precise camera poses as inputs.
roxanneluo.github.io/Consistent-Vid…
The method achieves AWESOME results but requires precise camera poses as inputs.
Isn't SLAM/SfM a SOLVED problem? You might ask.
Yes, it works pretty well for static and controlled environments. For causal videos, existing methods usually fail to register all frames or produce outlier poses with large errors.
As a result, CVD works only *when SFM works*.
Yes, it works pretty well for static and controlled environments. For causal videos, existing methods usually fail to register all frames or produce outlier poses with large errors.
As a result, CVD works only *when SFM works*.
How can we make video depth estimation ROBUST?
Our idea: *Joint optimization* of depth and camera poses.
However, optimizing only depth scale or finetuning depth network results in the poor estimation of camera pose trajectory (c-d) due to depth misalignments.
Our idea: *Joint optimization* of depth and camera poses.
However, optimizing only depth scale or finetuning depth network results in the poor estimation of camera pose trajectory (c-d) due to depth misalignments.
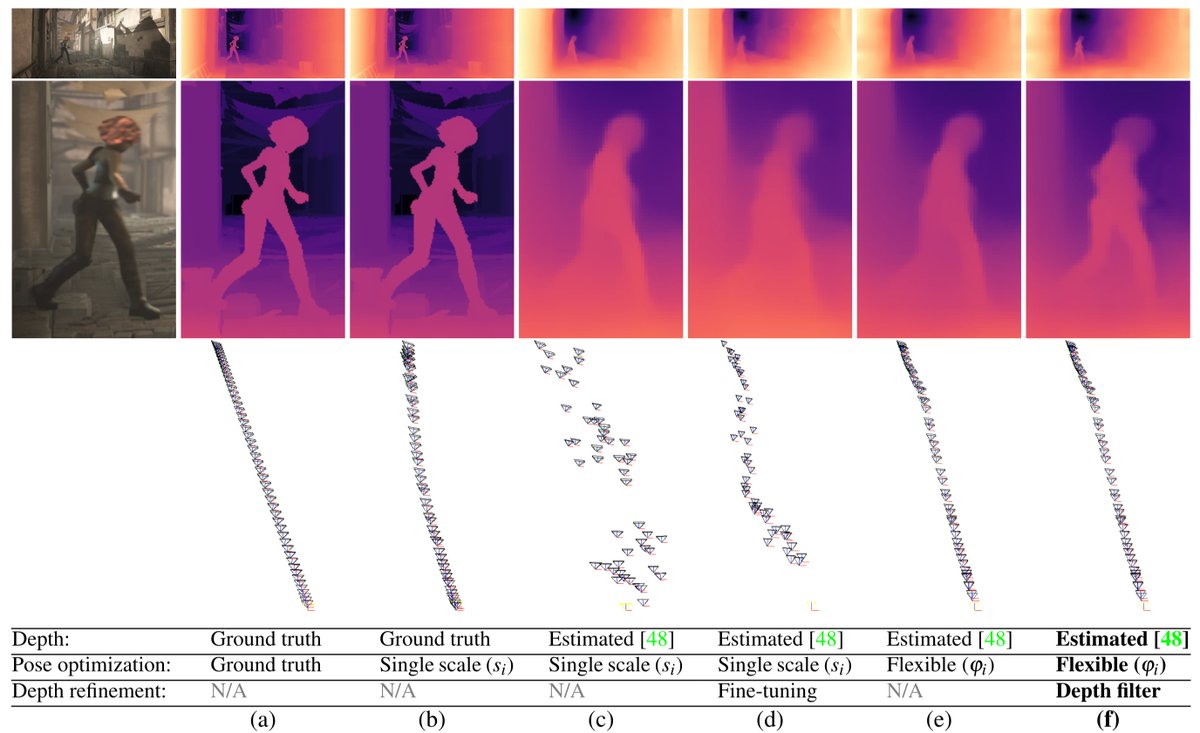
We resolve this problem by replacing the per-frame camera scale with a more flexible *spatially-varying transformation*. The improved alignment of the depth enables computing smoother and more accurate pose trajectories!
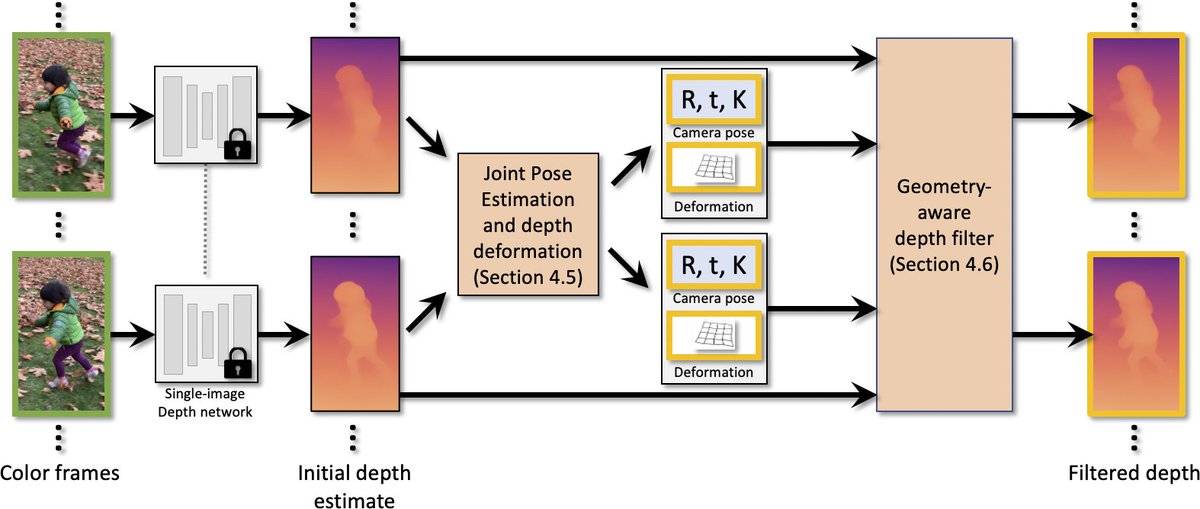
The flexible depth deformation is great, but can only achieve low-frequency alignment of depth maps. We further introduce a spatio-temporal geometry-aware depth filter (following flow trajectories) to improve fine depth details.

To validate the robustness, we show that we can estimate the consistent depth and smooth camera poses on all 90 videos on the DAVIS dataset.
No cherry-picking!
Can't wait to see how this will lead to *3D-aware* video recognition/synthesis and beyond!
No cherry-picking!
Can't wait to see how this will lead to *3D-aware* video recognition/synthesis and beyond!
Also, please check out results on extracting long smooth camera trajectories.
https://twitter.com/JPKopf/status/1337584554798813184?s=20
Hopefully, we will have something similar to the hologram in the movie Minority Report (2002) soon! 😍
• • •
Missing some Tweet in this thread? You can try to
force a refresh









