
🛠️Tooling Tuesday🛠️
Let's talk about setting up our Python/CUDA environment!
Our goals:
- Easily specify exact Python and CUDA versions
- Humans should not be responsible for finding mutually-compatible package versions
- Production and dev requirements should be separate
1/N
Let's talk about setting up our Python/CUDA environment!
Our goals:
- Easily specify exact Python and CUDA versions
- Humans should not be responsible for finding mutually-compatible package versions
- Production and dev requirements should be separate
1/N
Here's a good way to achieve these goals:
- Use `conda` to install Python/CUDA as specified in `environment.yml`
- Use `pip-tools` to lock in mutually compatbile versions from `requirements/prod.in` and `requirements/dev.in`
- Simply run `make` to update everything!
2/N
- Use `conda` to install Python/CUDA as specified in `environment.yml`
- Use `pip-tools` to lock in mutually compatbile versions from `requirements/prod.in` and `requirements/dev.in`
- Simply run `make` to update everything!
2/N
Here's our `environment.yml` file.
It specifies Python 3.8, CUDA 10.2, CUDNN 7.6.
To create an environment from this, install Miniconda (docs.conda.io/en/latest/mini…) and run `conda env create`.
Activate the environment with `conda activate conda-piptools-sample-project`
3/N
It specifies Python 3.8, CUDA 10.2, CUDNN 7.6.
To create an environment from this, install Miniconda (docs.conda.io/en/latest/mini…) and run `conda env create`.
Activate the environment with `conda activate conda-piptools-sample-project`
3/N

Here are the `requirements/prod.in` and `requirements/dev.in` files.
This is what pip-tools (github.com/jazzband/pip-t…) takes in.
Separating dev from prod dependencies is good practice. Another common stage could be `test`.
4/N
This is what pip-tools (github.com/jazzband/pip-t…) takes in.
Separating dev from prod dependencies is good practice. Another common stage could be `test`.
4/N

Running `pip-compile -v requirements/prod.in && pip-compile -v requirements/dev.in` will generate the lockfiles shown below.
These package versions are all mutually compatible (pip-tools will fail if it can't find achieve this).
Check the lockfiles into version control.
5/N
These package versions are all mutually compatible (pip-tools will fail if it can't find achieve this).
Check the lockfiles into version control.
5/N

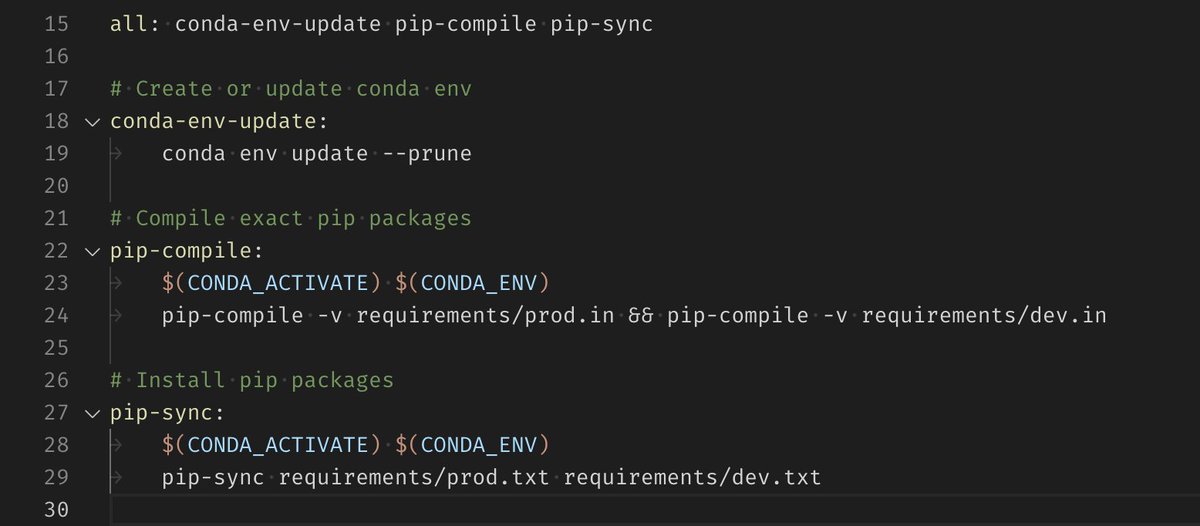
Install these exact versions with `pip-sync requirements/prod.txt requirements/dev.txt`. You're now off to the races!
If you make changes to `envrionment.yml` or `requirements/*.in`, we'll have to compile and sync again, so let's add a Makefile to make it easy.
6/N
If you make changes to `envrionment.yml` or `requirements/*.in`, we'll have to compile and sync again, so let's add a Makefile to make it easy.
6/N
Tiny demo repo: github.com/full-stack-dee…
Alternative approaches?
- Docker for Python / CUDA. Great if that's what you need, but `conda` is lighter-weight.
- `Pipenv` or `poetry` for package locking. We found their dep. resolution to be slow, but test for yourself.
7/N
Alternative approaches?
- Docker for Python / CUDA. Great if that's what you need, but `conda` is lighter-weight.
- `Pipenv` or `poetry` for package locking. We found their dep. resolution to be slow, but test for yourself.
7/N
• • •
Missing some Tweet in this thread? You can try to
force a refresh




