
This is a Twitter series on #FoundationsOfML. Today, I want to talk about another fundamental question:
❓ What makes a metric useful for Machine Learning?
Let's take a look at some common evaluation metrics and their most important caveats... 👇🧵
❓ What makes a metric useful for Machine Learning?
Let's take a look at some common evaluation metrics and their most important caveats... 👇🧵
Remember our purpose is to find some optimal program P for solving a task T, by maximizing a performance metric M using some experience E.
https://twitter.com/AlejandroPiad/status/1348840452670291969?s=20
We've already discussed different modeling paradigms and different types of experiences.
👉 But arguably, the most difficult design decision in any ML process is which evaluation metric(s) to use.
👉 But arguably, the most difficult design decision in any ML process is which evaluation metric(s) to use.
There are many reasons why choosing the right metric is crucial.
🔑 If you cannot measure progress, you cannot objectively decide between different strategies.
This is true when solving any problem, but in ML the consequences are even bigger: 👇
🔑 If you cannot measure progress, you cannot objectively decide between different strategies.
This is true when solving any problem, but in ML the consequences are even bigger: 👇
🔶 In Machine Learning, the metric you choose directly determines the type of solution you end up with.
Remember that "solving" a problem in ML is actually about *searching*, between different models, the one that maximizes a given metric.
Remember that "solving" a problem in ML is actually about *searching*, between different models, the one that maximizes a given metric.
📝 Hence, metrics in Machine Learning are not auxiliary tools to evaluate a solution. They are what *guides* the actual process of finding a solution.
Let's talk about some common metrics, focusing on classification for simplicity (for now): 👇
Let's talk about some common metrics, focusing on classification for simplicity (for now): 👇
1️⃣ Accuracy measures the percentage of the objects for which you guessed their category right.
It's probably the most commonly used metric in the most common type of ML problem.
It's probably the most commonly used metric in the most common type of ML problem.
👍 The main advantage of accuracy is that it is very easy to interpret in terms of the business domain, and it is often aligned with what you actually want to achieve in classification: be right as many times as possible.
👎 One caveat is that accuracy is not differentiable, and cannot be used directly as the target in gradient-based optimization processes, such as neural networks, but there are easy solutions for this problem.
👎 Arguably the biggest problem of accuracy is that it counts every error as equal.
This is not often the case. It can be far worse to tell a sick person to go home than to tell a healthy person to take the treatment (depending on the treatment, of course).
This is not often the case. It can be far worse to tell a sick person to go home than to tell a healthy person to take the treatment (depending on the treatment, of course).
👎 On the other hand, if the number of elements in each category is not similar, you can be making a very large mistake (in relative terms) on the less populated category.
You can get >99% accuracy if you just tell everyone you find on the street that they don't have COVID.
You can get >99% accuracy if you just tell everyone you find on the street that they don't have COVID.
The problem with Accuracy is that it smooths away different types of errors under the same number.
👉 If you care about one specific class more than the rest, measure 2️⃣Precision and 3️⃣Recall instead, as they tell you more about the nature of the mistakes you're making.
👉 If you care about one specific class more than the rest, measure 2️⃣Precision and 3️⃣Recall instead, as they tell you more about the nature of the mistakes you're making.
In general, there are two types of errors we can make when deciding the category C of an element:
🔹 We can say one element belongs to C when it doesn't (type I).
🔹 We can fail to say an element belongs to C when it does (type II).
How about we measure both separately: 👇
🔹 We can say one element belongs to C when it doesn't (type I).
🔹 We can fail to say an element belongs to C when it does (type II).
How about we measure both separately: 👇
2️⃣ Precision measures the percentage of times you say the category is C, and you're right (type I).
3️⃣ Recall measures the percentage of elements of category C that you correctly identified (type II).
3️⃣ Recall measures the percentage of elements of category C that you correctly identified (type II).
By looking at these metrics separately, you can better identify what kind of error you're making.
📝 If you still want a kind of average that weights both, you can use the F-Measure, which allows you to prioritize precision vs recall to any desired degree.
📝 If you still want a kind of average that weights both, you can use the F-Measure, which allows you to prioritize precision vs recall to any desired degree.
Precision and Recall are also very intuitive to interpret, but they still don't tell us the whole story.
👉 When we have more than two categories, we can fail at any one of them by confusing it with any other. Here, again, precision and recall are too general.
👉 When we have more than two categories, we can fail at any one of them by confusing it with any other. Here, again, precision and recall are too general.
✏️ A *confusion matrix* tells us how many times we confuse each category C1 with any other category Ci across a test set.
It looks something like this.
It looks something like this.
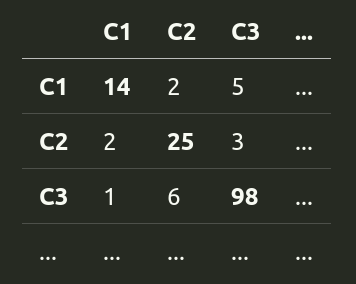
✏️ Every number in a diagonal is a prediction we got right, and every other number is a prediction we got wrong.
Accuracy, precision, and recall are easy to compute from the confusion matrix (I'll leave you that as an exercise 😜).
Accuracy, precision, and recall are easy to compute from the confusion matrix (I'll leave you that as an exercise 😜).
👍 The matrix itself shows a larger picture. It can tell us, for example, where we should focus on gathering more data.
👎 However, confusion matrices don't give us a single number we can optimize for and are thus harder to interpret.
👎 However, confusion matrices don't give us a single number we can optimize for and are thus harder to interpret.
The story we've seen here is common all over Machine Learning.
🔸 We can have simple, high-level, interpretable metrics, that hideaway the nuance.
🔸 Or we can have low-level metrics that tell a bigger picture, but require more effort to interpret.
🔸 We can have simple, high-level, interpretable metrics, that hideaway the nuance.
🔸 Or we can have low-level metrics that tell a bigger picture, but require more effort to interpret.
There is a lot more to tell about metrics and evaluation in general, and we've just focused on a very small part of the problem.
Some of the issues that need to be kept in mind: 👇
Some of the issues that need to be kept in mind: 👇
🔥 The metric we would like to optimize might not be optimizable at all, either because it's hard to evaluate (e.g., it's expensive or requires a human evaluator) or because it's not compatible with our optimization process (e.g., it's not differentiable).
🔥 We can have multiple contradictory objectives, and no trivial way to combine them into a single metric.
🔥 And sometimes we can judge a solution intuitively, but we have no idea know how to write a mathematical formulation for a metric that encodes that intuition.
🔥 And sometimes we can judge a solution intuitively, but we have no idea know how to write a mathematical formulation for a metric that encodes that intuition.
🤜 It's hard to overstate how important this topic is.
Almost every alignment problem in AI can be traced back to a poorly defined metric. For example, maximizing engagement is arguably a large part of the reason why social media is as broken as it is.
Almost every alignment problem in AI can be traced back to a poorly defined metric. For example, maximizing engagement is arguably a large part of the reason why social media is as broken as it is.
☝️ There is no objective way to decide what's the best metric for a problem by looking at the data alone. We have to decide what we want to aim for, and that in turn will define the problem we are actually solving.
⏳ Next time, we'll talk about some common problem types.
⏳ Next time, we'll talk about some common problem types.
• • •
Missing some Tweet in this thread? You can try to
force a refresh


