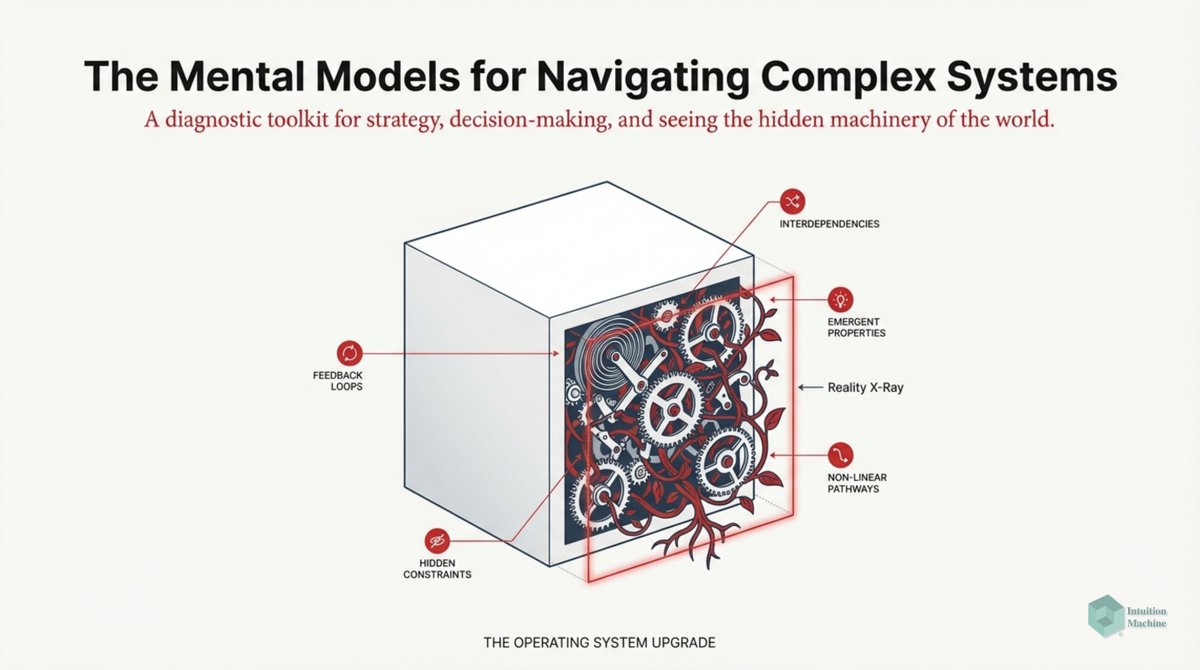
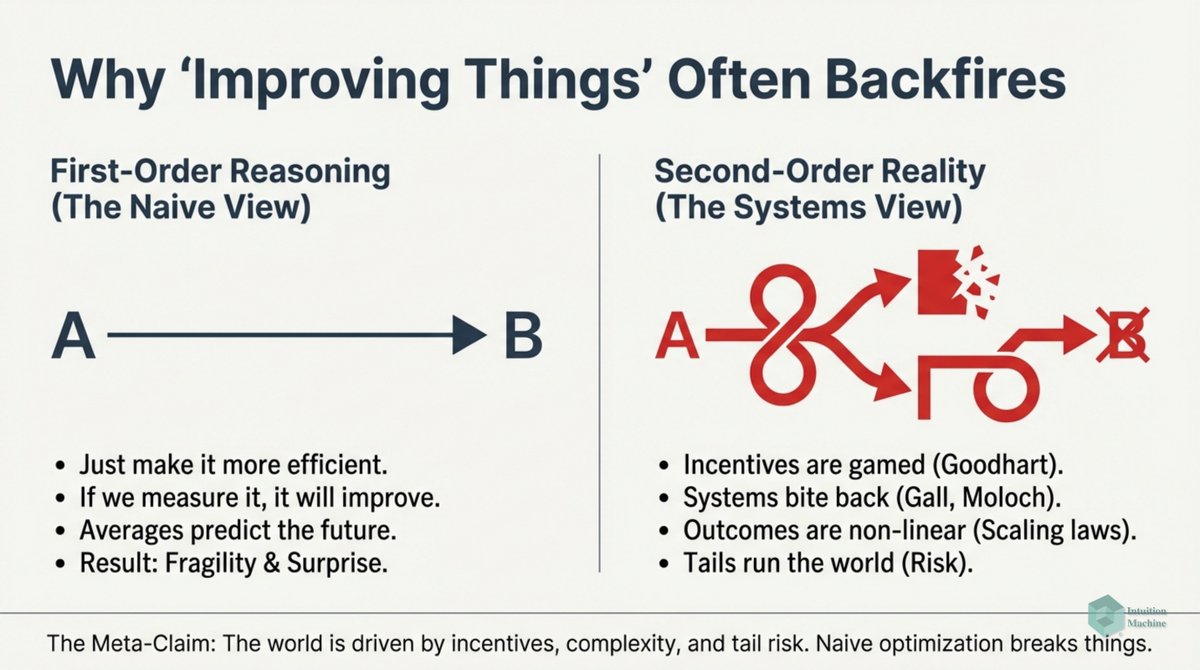
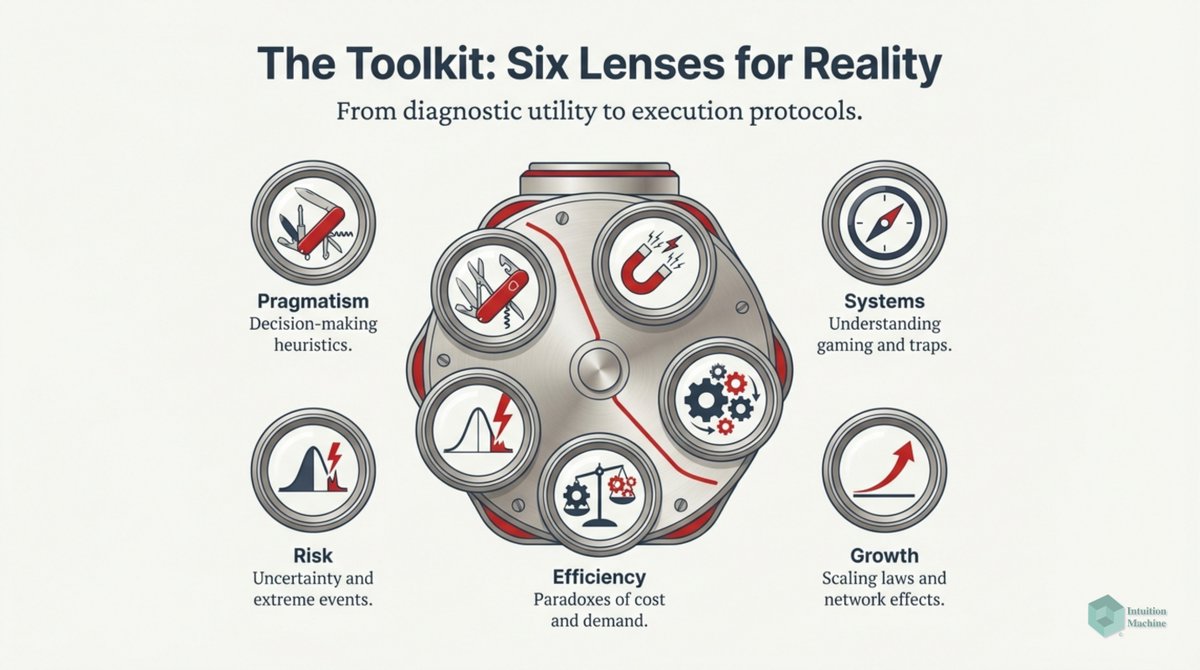
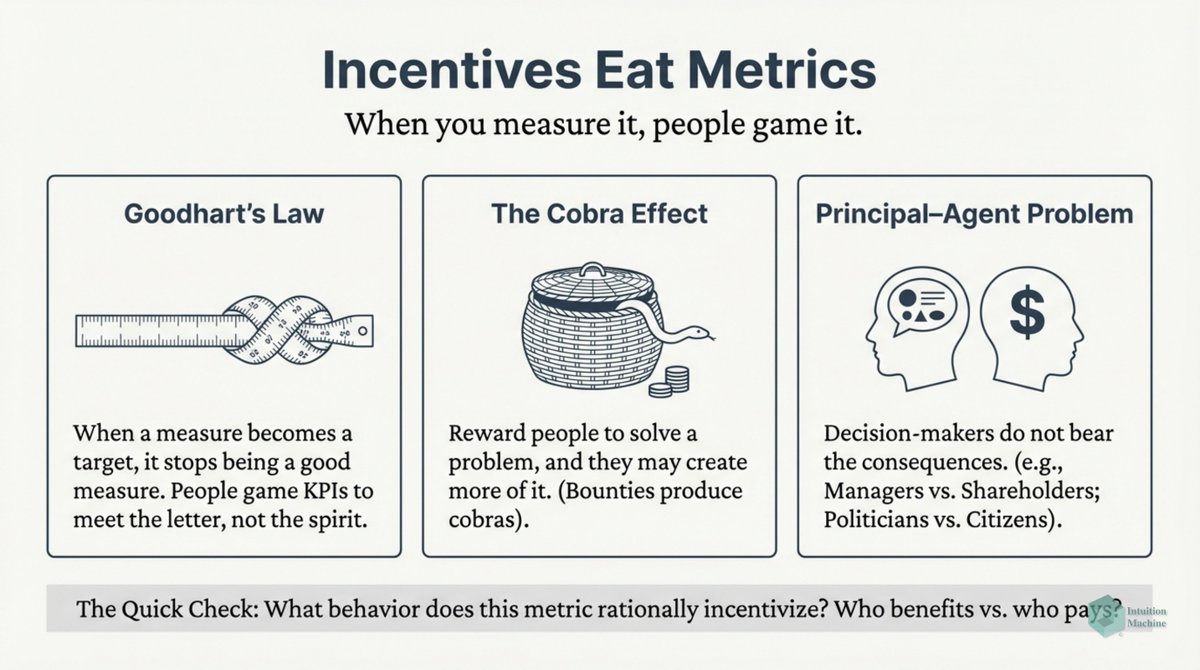
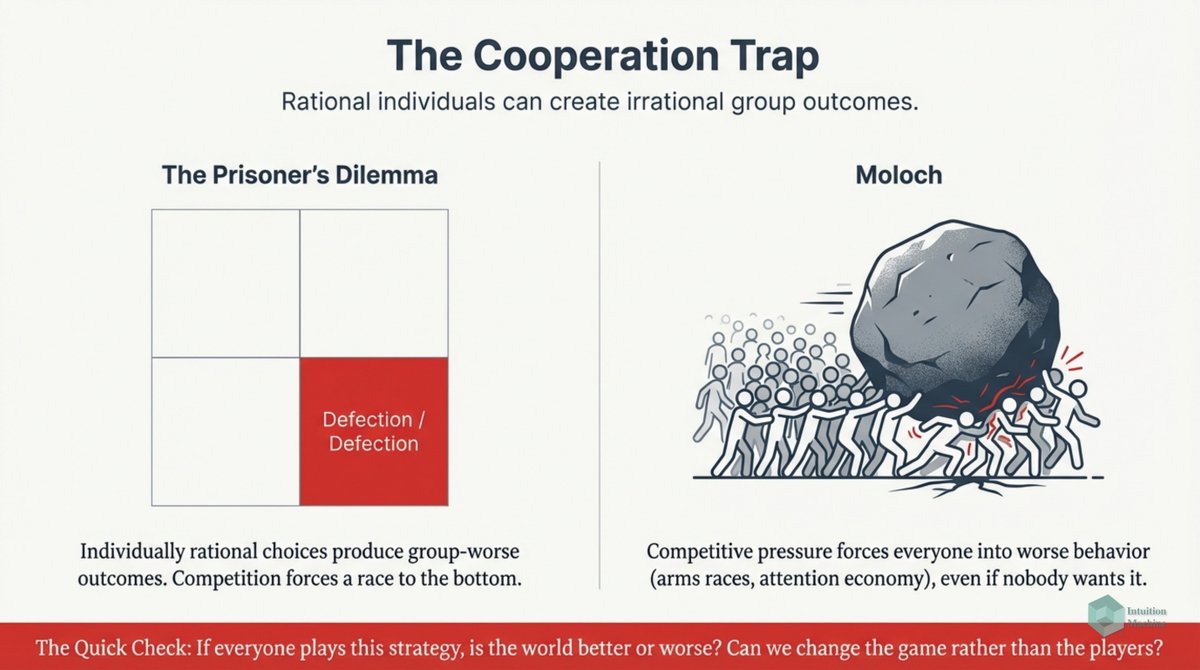
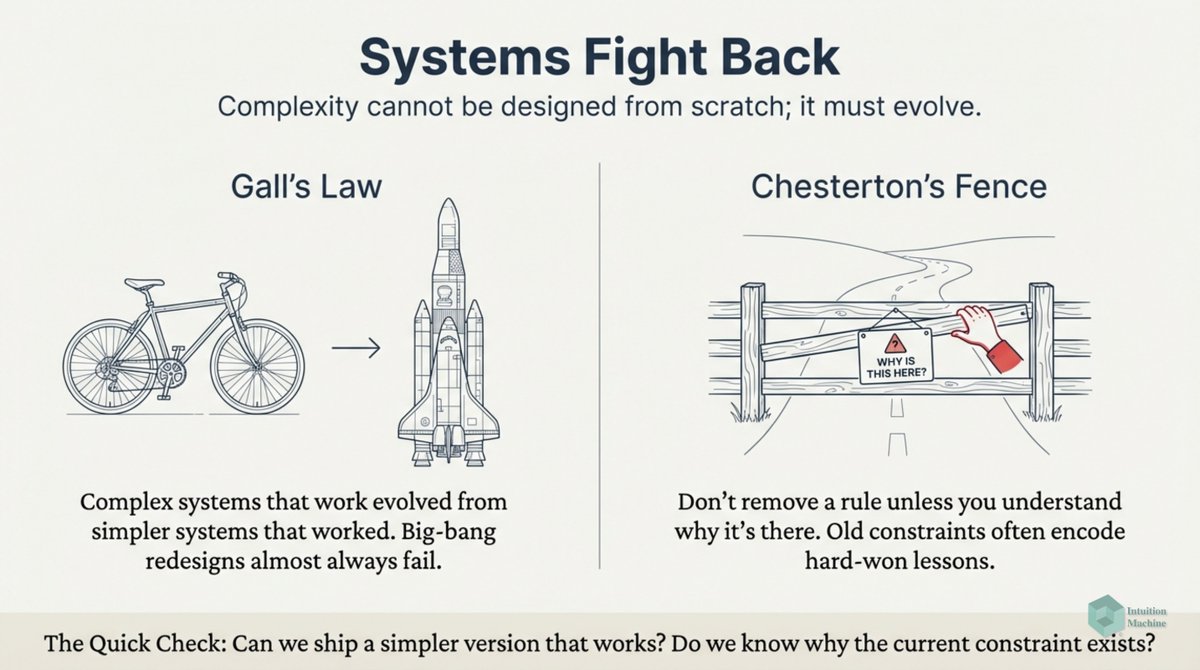
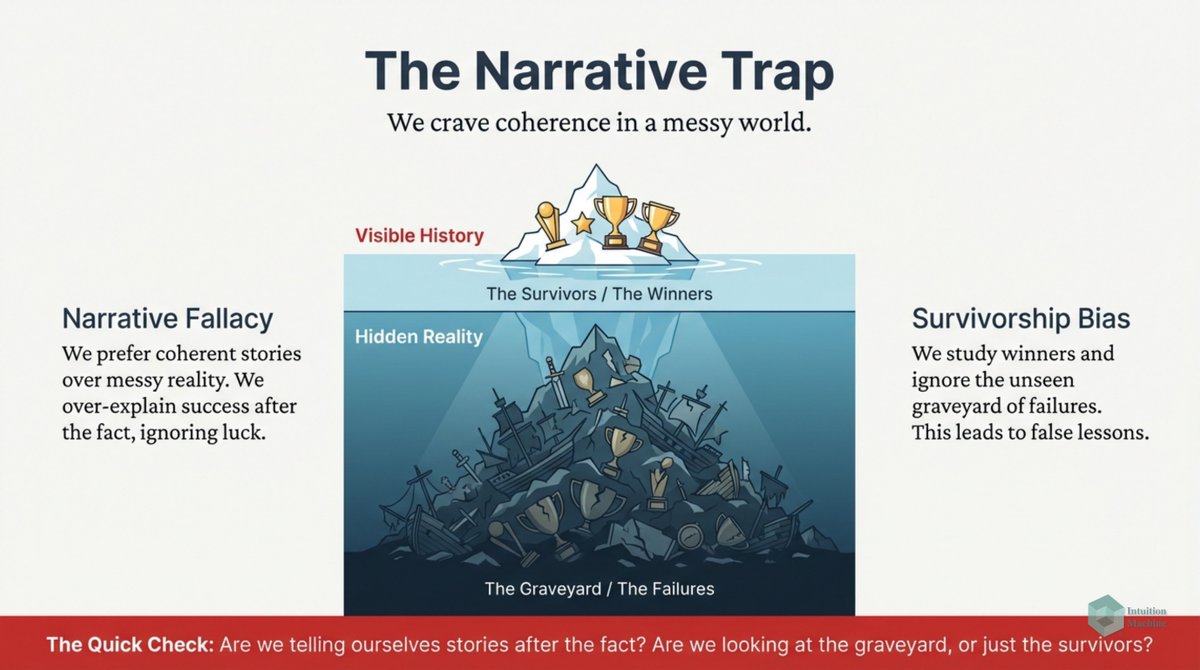
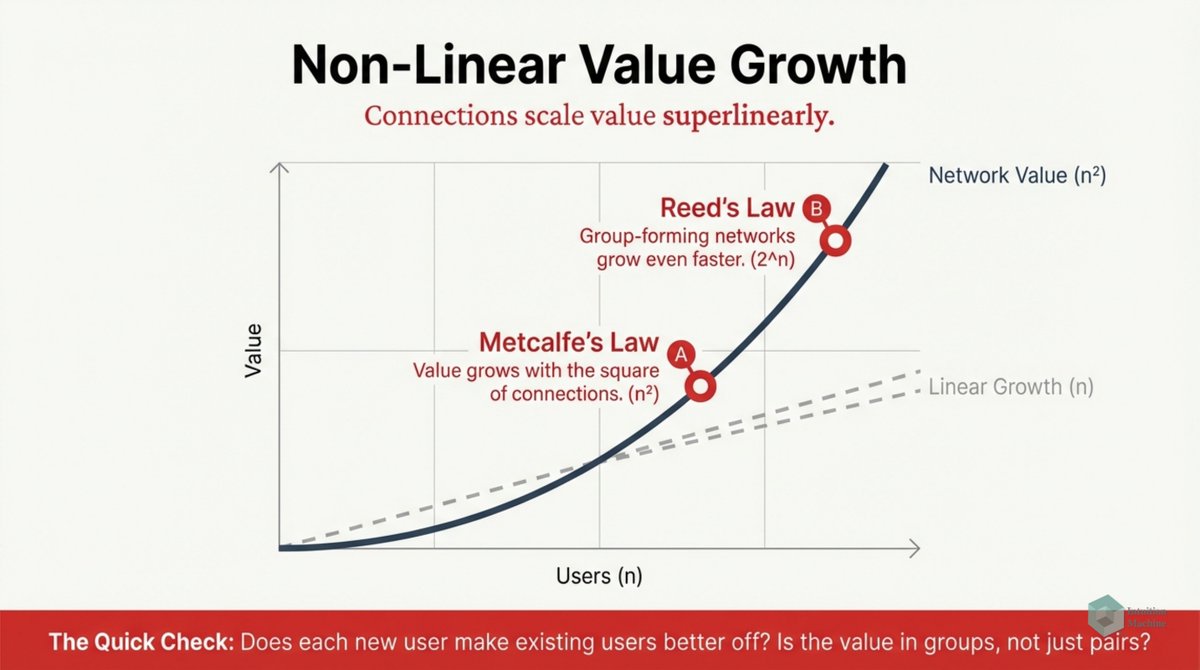
Do you think fractals (i.e. iterative and self-similarity) are weird? Well, it isn't as weird as biological iterative processes. medium.com/intuitionmachi…
What's even weirder is that humans have an intuition that something appears organic. What does it actually mean to have an organic design?
Christopher Alexander, an architect, who wrote 'A Pattern Language' that has immensely influenced software development, wrote four books exploring this idea (see: Nature of Order).
Organic design and its biological underpinnings are extremely complex. Allow me however to focus on a narrower scope, something that is less complex. General intelligence is something less complex and something that is also organic in nature.
Darwin's theory of evolution appending the existing orthodoxy that the species that inhabited the world was a fixed thing. What society has yet to come to grips with is that our brains are *not* fixed things.
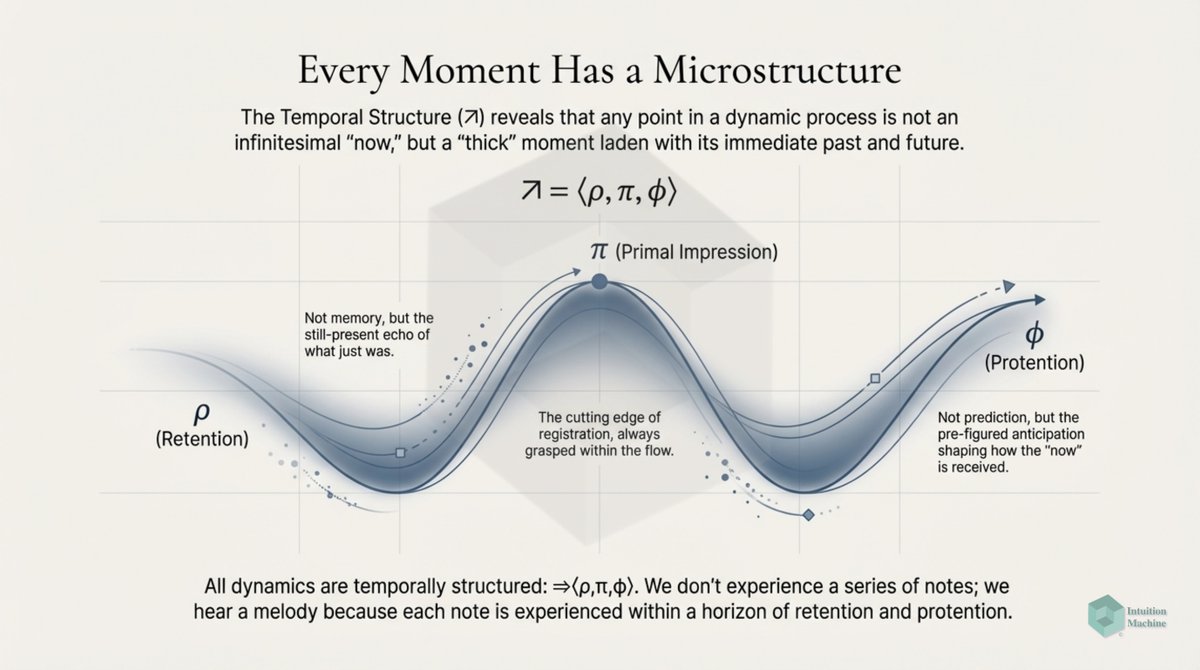
Brains are 'livewired' to their sensors and their bodies. They learn to interact with this world by being embedded in the constraints of this world. All learning is entangled in context and all meaning of language is also entangled in context.
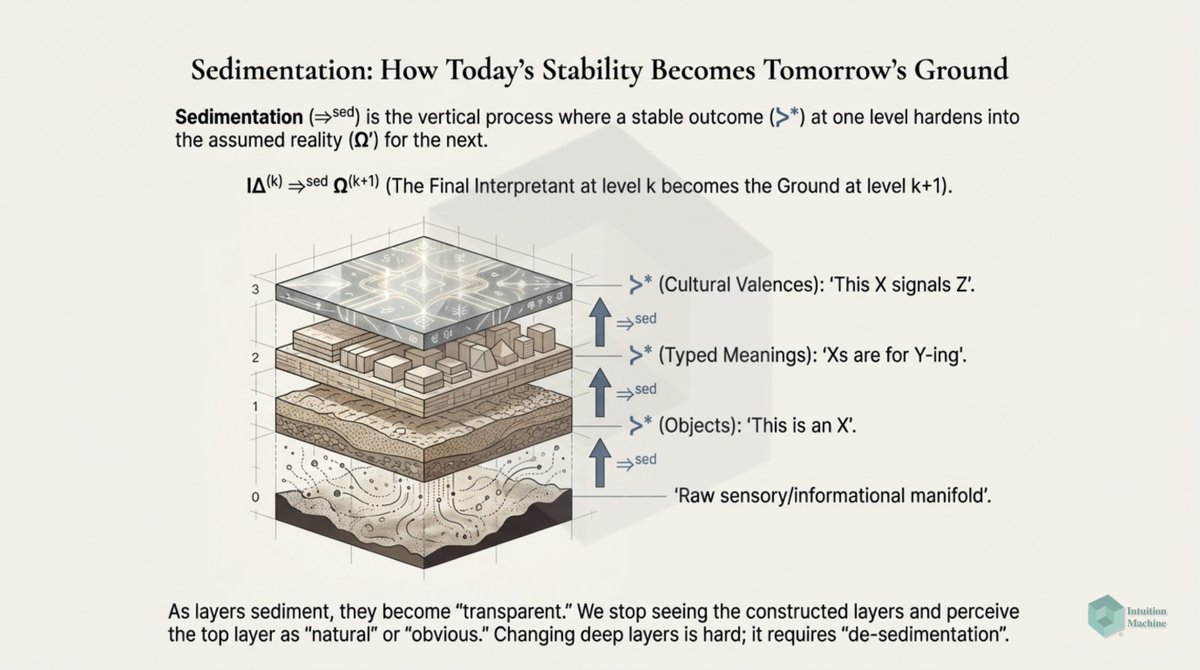
We however create explanations of this world through concepts that are disentangled from their context. From a Peircian perspective, our signs evolve from icons to indexes to symbols. This sign evolution leads to a loss of information.
Humans are still able to understand each other through language (i.e. a sequence of symbols) because our interpretations annotate words with meaning. But in all cases, it is our subjective meaning of the words.
Subjective implies that it interpretative relative to the interpreter's reference frame and hence imagined context. This is Wittgenstein's Picture theory of language interpretation. medium.com/intuitionmachi…
What then does it mean when we say that brains are constructed from the inside out in an organic manner? How does this inform our understanding of general intelligence? Why is it different from the brain as a computer metaphor?
I've already explained why the brain as a computer is a horrible metaphor: medium.com/intuitionmachi… So let me skip that question.
I've already explained why organic design is different from engineered design. So let me skip that question too! medium.com/intuitionmachi…
So let's focus on how general intelligence is informed by organic design. We've already established the error-correcting nature of both organic design and cognitive development: medium.com/intuitionmachi…
Christopher Alexander uses error-correction to explain why towns that emerge organically look very different from those that are architected. The activity of living modifies the world in a gradual manner. Adjusting the world to make convenient the pursuit of life.
Alexander proposes 15 recurring patterns that he's observed in organic design: 

However, these concern themselves with physical structures. But do the mental models that we grow and cultivate in our minds also follow the same organic principles?
When we attempt to solve a Bongard problem, we spontaneously create alternative ways of matching patterns. One sometimes hears the words 'inductive bias' to refer to this. Unfortunately, the vocabulary we employ to describe patterns is impoverished.
Here is @LakeBrenden in a recent video describing inductive biases:
I conjecture how our minds create the kind of thinking required for the left hemisphere is based on different prioritization of inductive biases as compared to the right hemisphere.
The starting point for a vocabulary of 'inductive biases' can be found in Alexander's 15 patterns.
@threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh