A follow up 🧵 on Tesla's FSD "rewrite" to explore the Bird's Eye View Networks.
"There are still a few of neural nets that need to be upgraded to video training & inference. And really, as we transition to each net to video, the performance become exceptional." - Elon Musk
"There are still a few of neural nets that need to be upgraded to video training & inference. And really, as we transition to each net to video, the performance become exceptional." - Elon Musk
We can gather from this statement, not all networks are running the BEV mode "rewrite" even for #FSDBeta users. But why is a BEV so much more "performant" compared to a single camera? Let's see what @karpathy has to say about this video:
Per camera: "We developed this occupancy tracker that stitches up these image level predictions. The stitching is highly error prone across cameras and time."
BEV: "We don't have the occupancy tracker in C++ land, its in a network."
BEV: "We don't have the occupancy tracker in C++ land, its in a network."
Per Camera: "semantic segmentation on pixels looks good on the image, but you have to project it out to make it 3D sense of it otherwise you can't drive through it."
BEV: "You can predict the lane lines out of the network directly... it works much better."
BEV: "You can predict the lane lines out of the network directly... it works much better."
So we can see the architecture is loosely--
Per Camera:
1) detect entities in image (NN)
2) stitch images together (C++)
3) extrapolate depth/3d world (C++)
4) extrapolate time (C++)
5) apply driving policy
Per Camera:
1) detect entities in image (NN)
2) stitch images together (C++)
3) extrapolate depth/3d world (C++)
4) extrapolate time (C++)
5) apply driving policy
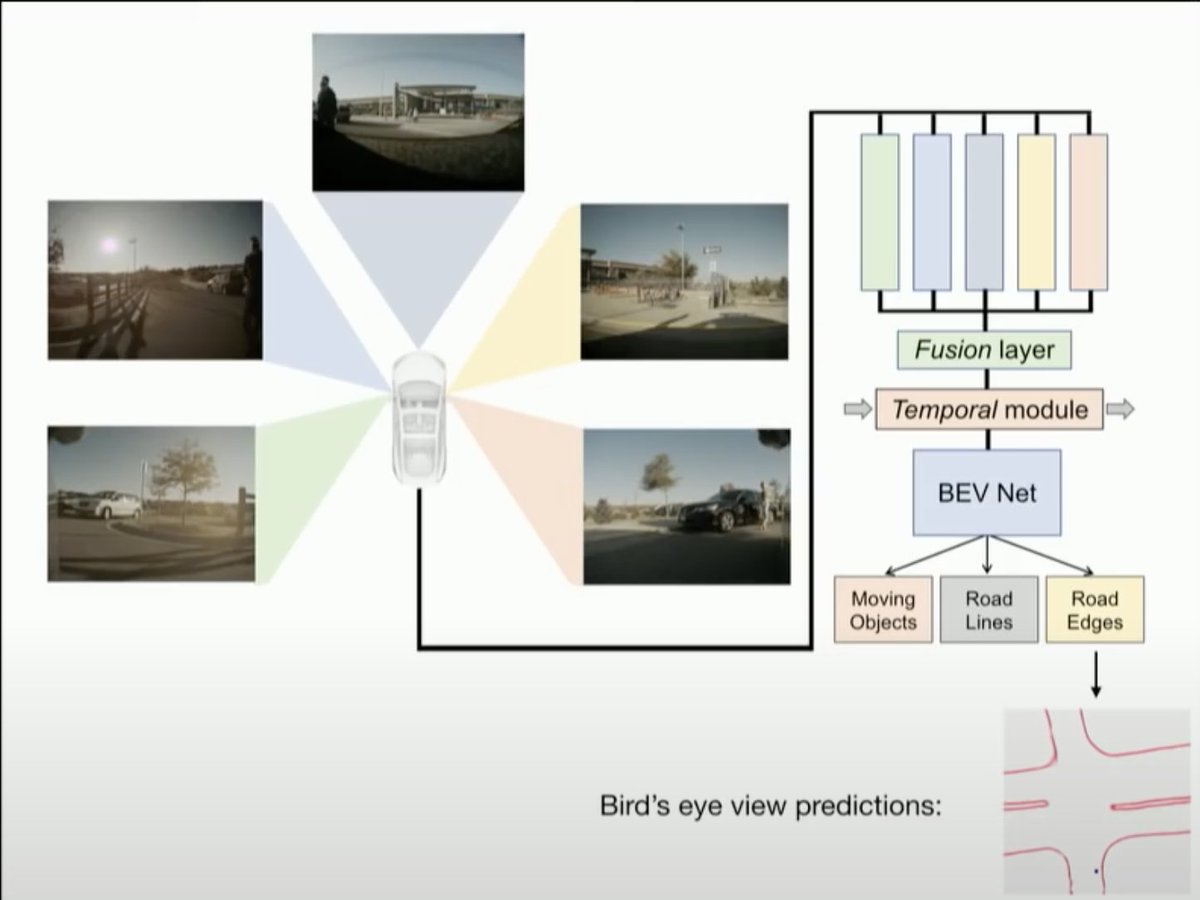
The BEV merges many of these steps into an end to end neural net.
BEV:
1) extract features in video (NN)
2) orthographic feature transform 2D to 3D (NN)
3) predict a Bird Eye's View of the environment (NN)
4) apply driving policy (C++)
BEV:
1) extract features in video (NN)
2) orthographic feature transform 2D to 3D (NN)
3) predict a Bird Eye's View of the environment (NN)
4) apply driving policy (C++)
This change requires significant rewrite of the training software (which is arguably more important) as annotators now need to label 1) the optical flow between frames 2) the 3D cuboids of transformed entities and 3) the vectors of the BEV entities.
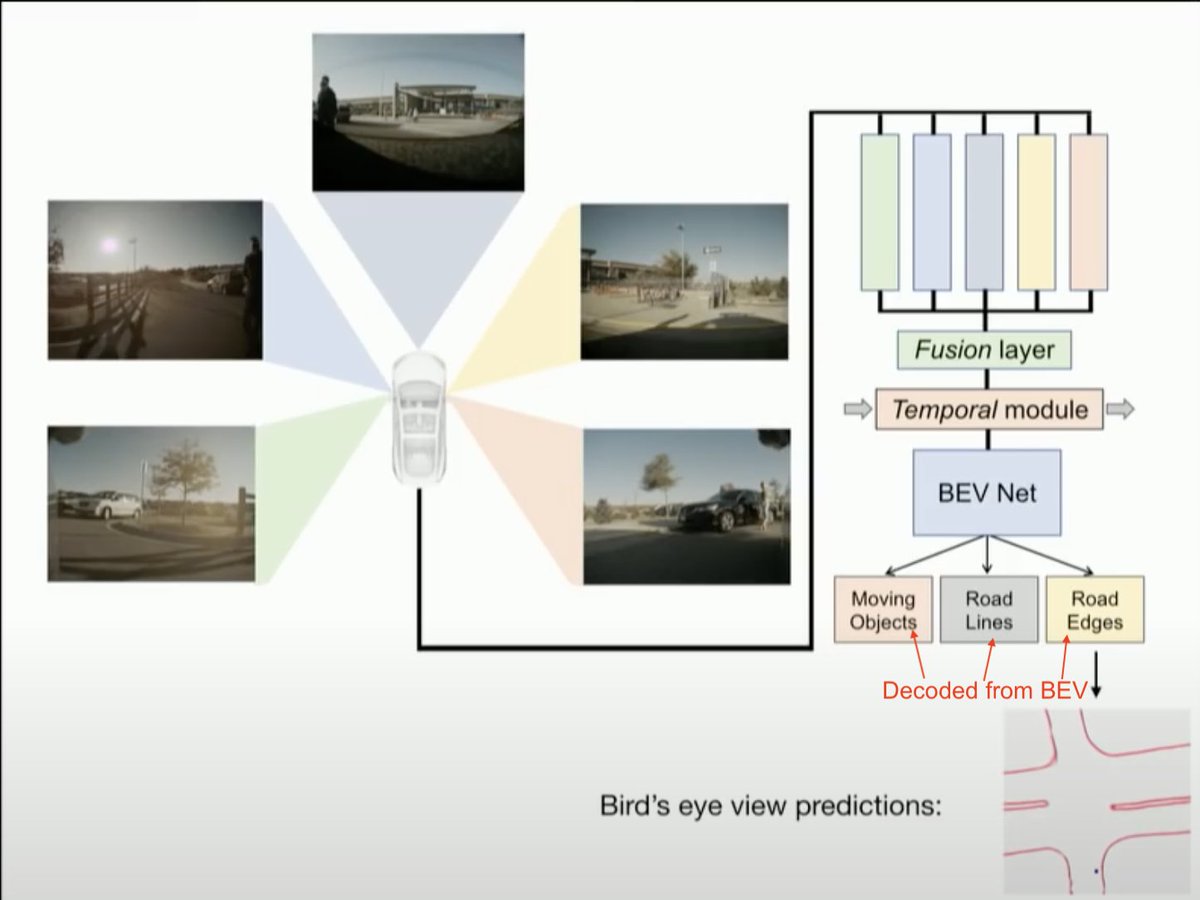
Another side effect is that the vehicle no longer has access to the raw predictions. It needs to decode things like lane lines, drive-able space etc from the BEV. This removes large swathes of software 1.0 code and replaces it with something like getRoadEdge(), getLaneLine() etc. 
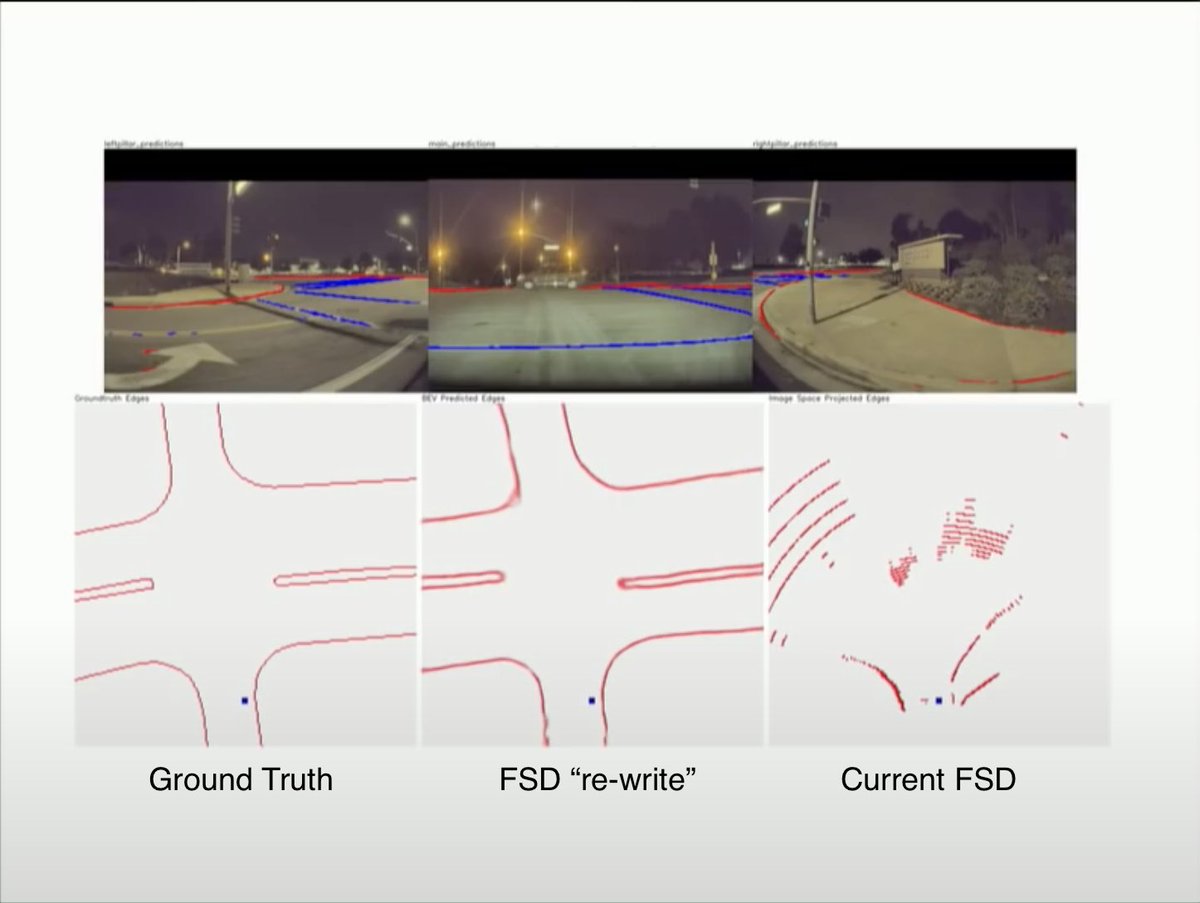
BEVs work with uncertainty as they have an understanding of what intersections could possibly look like. Fish eye lenses only have a few pixels of angular resolution at the horizon and fail at raw detection. BEV can build predictions of road layout and infrastructure accurately.
Instead of asking the NN to detect road layout at the horizon, the BEV takes in all of the sensor data and tries to predict the bird eye view of the entire 3D space around itself. The objects at the horizon are nothing more and an emergent property of this global prediction.

Finally another interesting tidbit on dynamic entities in the BEV:
@karpathy:
"We are trying to apply BEV networks to cars and objects; how they move around ... all these different things we need to know about so we can anticipate how people will move around"
@karpathy:
"We are trying to apply BEV networks to cars and objects; how they move around ... all these different things we need to know about so we can anticipate how people will move around"
Not sure if that means BEV is used for cars yet or not but one interesting side effect is that the per-camera outputs could train part of the BEV and then over time the apprentice would become the master.
Instead of predicting other dynamic object's type, distance, orientation, trajectory as seperate tasks; AutoPilot could predict the birds eye view of all objects in time and space and retrieve the lower level predictions as decoded attributes.
@greentheonly would be interested in your thoughts if you have seen any other hints of the BEV networks being expanded upon.
@WholeMarsBlog @kimpaquette @Kristennetten @chazman do any of you notice that moving entities object detection is different in regular AutoSteer vs FSD? I.e. is FSD more accurate on predictions that overlap?
• • •
Missing some Tweet in this thread? You can try to
force a refresh