
Emoji are the biggest innovation in human communication since the invention of the letter 🅰️.
Curious how they work under the hood? 🧵👇
Curious how they work under the hood? 🧵👇
As you might know, all text inside computers is encoded with numbers. One letter—one number. The most popular encoding we use is called Unicode, with the two most popular variations called UTF-8 and UTF-16.
Unicode allocates 2²¹ (\~2 mil) characters called codepoints. Sorry, programmers, but it’s not a multiply of 8 🤷. Out of those 2 million, actually defined are \~150k characters.
150k defined characters cover all the scripts used on 🌍, many dead languages, weird stuff like 𝔣𝔲𝔫𝔫𝔶 𝕝𝕖𝕥𝕥𝕖𝕣𝕤, sɹǝʇʇǝl uʍop-ǝpᴉsdn, GHz as one glyph: ㎓, “rightwards two-headed arrow with tail with double vertical stroke”: ⤘, seven-eyed monster: ꙮ, and a duck: 

As a side note, definitely check out the Egyptian Hieroglyphs block (U+13000–U+1342F). They have some really weird stuff.
unicode.org/charts/PDF/U13…
unicode.org/charts/PDF/U13…

So, emoji. At their simplest, they are just that: another symbol in a Unicode table. Most of them are grouped in U+1F300–1F6FF and U+1F900–1FAFF.
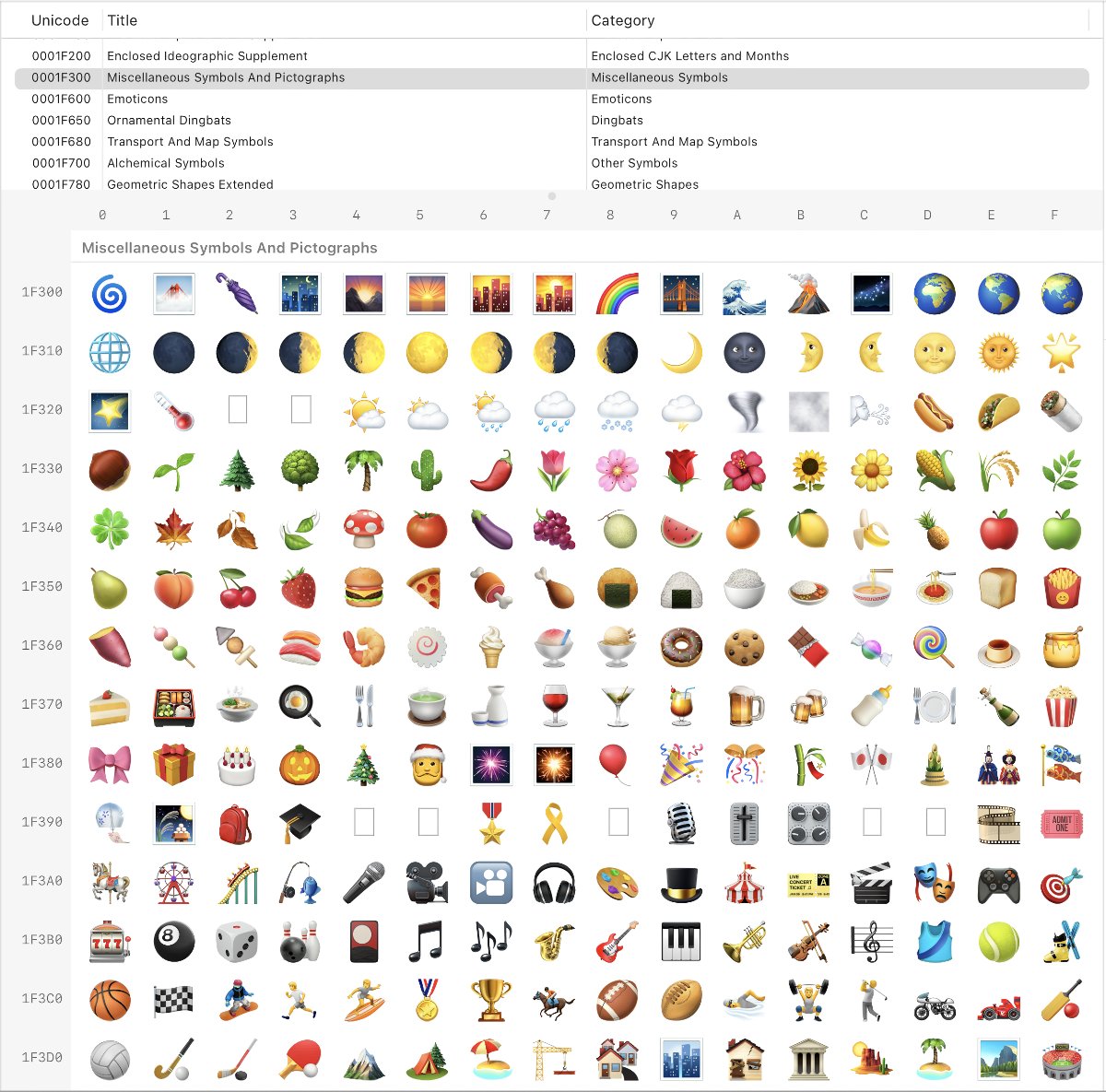
That’s why emoji behave like any other letter: they can be typed in a text field, copied, pasted, rendered in a plain text document, embedded in a tweet, etc. When you type “A”, the computer sees U+0041. When you type “🌵”, the computer sees U+1F335. Not much difference.
Why are emoji rendered as images then? Well, bitmap fonts. Apparently, you can create a font that has pngs for glyphs instead of boring black-and-white vector shapes.

Every OS comes with a single pre-installed font for emoji. On macOS/iOS, that’s Apple Color Emoji. Windows has Segoe UI Emoji, Android has Noto Color Emoji.
As far as I can tell, Apple is a bitmap font with 160×160 raster glyphs, Noto uses 128×128 bitmaps, and Segoe is a vector color font 🆒
That’s why emoji look different on different devices—just like fonts look different! On top of that, many apps bundle their own emoji fonts, too: WhatsApp, Twitter, Facebook.
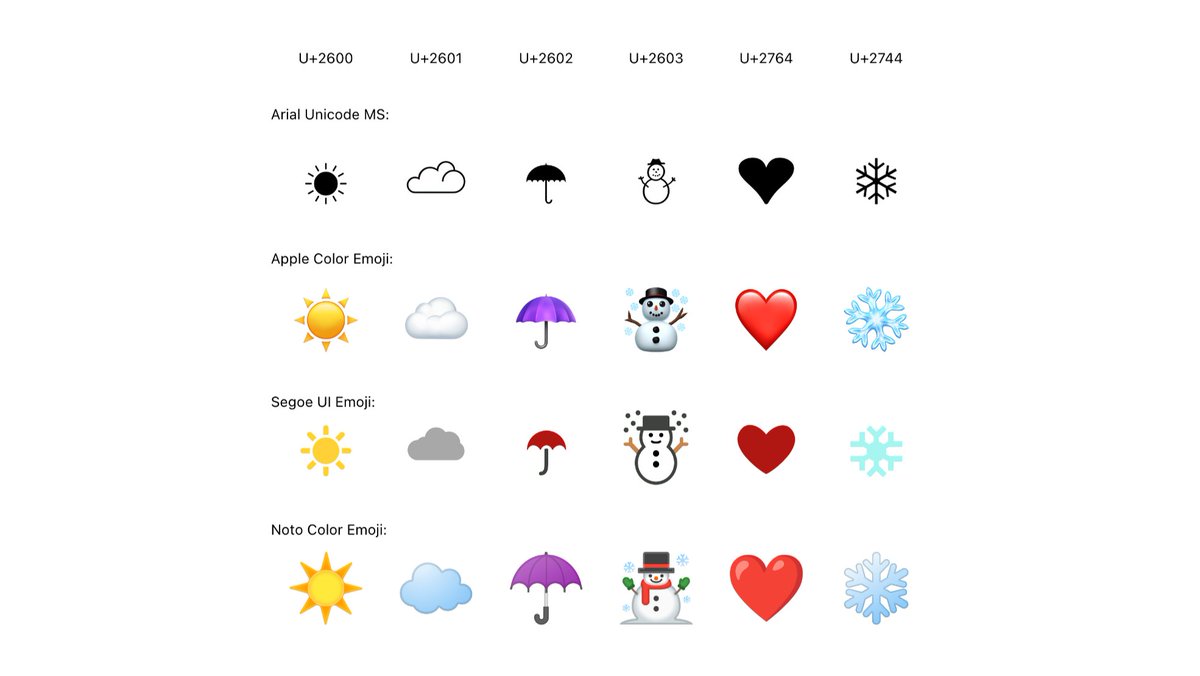
Now about the rendering. You don’t write your text in Apple Color Emoji or Segoe UI Emoji fonts (unless you are really young and pure at heart ❤️). So how can a text set in e.g. Helvetica include emoji?
Well, with the same machinery that makes Cyrillic text look ugly in Clubhouse or on Medium: font fallbacks.

When you type, say, U+1F419, it is first looked up in your current font. Let’s say it’s San Francisco. San Francisco doesn’t have a glyph for U+1F419, so OS starts to look for _any_ other installed font that might have it.
U+1F419 can only be found in Apple Color Emoji, thus OS uses it to render U+1F419 (rest of the text stays in your current font). In the end, you see 🐙. That’s why, no matter which font you use, Emoji always look the same:

Not all Emoji started their life straight in Emoji code block. In fact, pictograms existed in fonts and Unicode at least since 1993. Look in Miscellaneous Symbols U+2600-26FF and Dingbats U+2700-27FF:
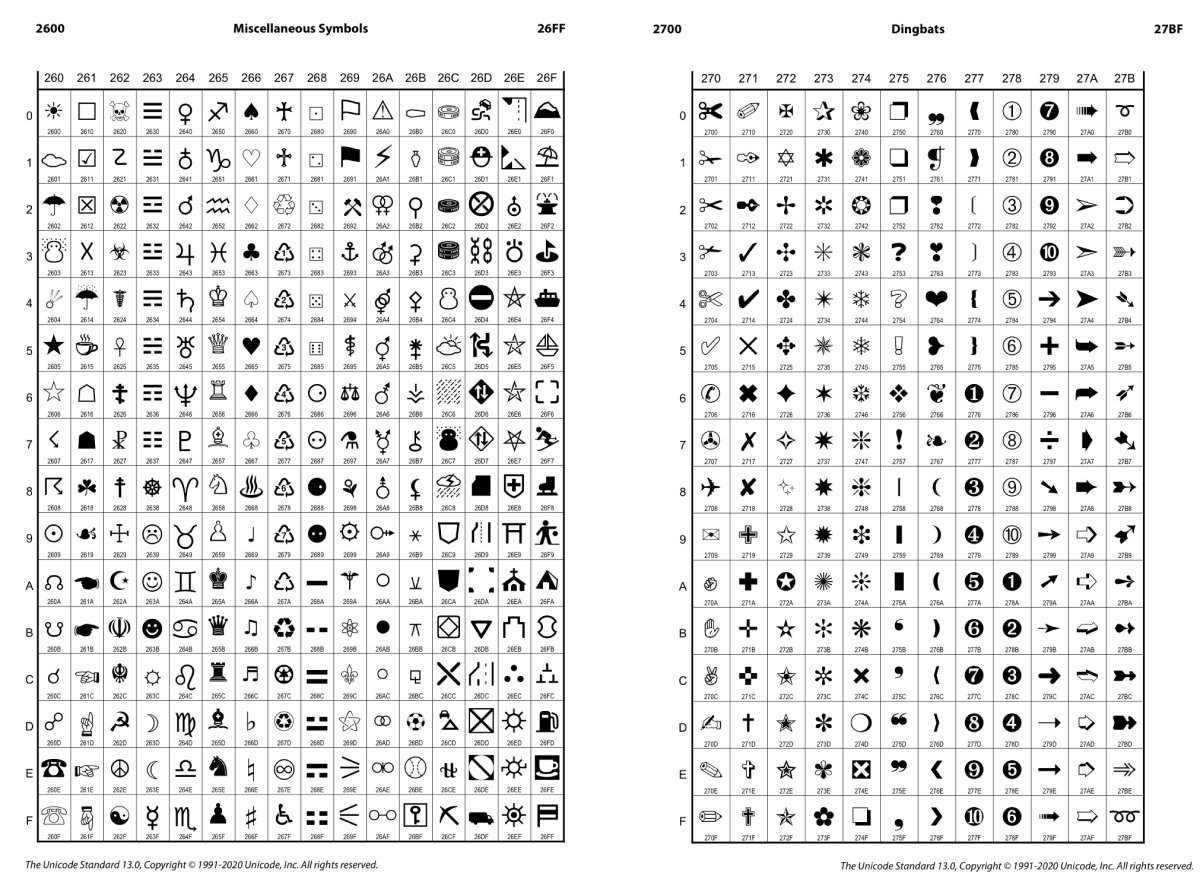
These glyphs are as normal as any other letters we use: they are single-codepoint, black-and-white, and many fonts have them included. For example, here are all the differnt fonts on my machine that have their own version of ✂︎ (U+2702 BLACK SCISSORS):

Guess what? When Apple Color Emoji was created, it had its own version of the same U+2702 codepoint that looked like this:

Now for the tricky part. How does OS knows when to render ✂︎ and when ✂️, if both of them have the same codepoint and not only Apple Color Emoji has it, but also many other higher-priority traditional fonts?
Meet U+FE0F, also known as VARIATION SELECTOR-16. It’s a hint to the text renderer to switch to an emoji font.
U+2702 — ✂︎
U+2702 U+FE0F — ✂️
U+2697 – ⚗︎
U+2697 U+FE0F – ⚗️
U+26A0 – ⚛︎
U+26A0 U+FE0F – ⚛️
U+2618 – ☘︎
U+2618 U+FE0F – ☘️
U+2702 — ✂︎
U+2702 U+FE0F — ✂️
U+2697 – ⚗︎
U+2697 U+FE0F – ⚗️
U+26A0 – ⚛︎
U+26A0 U+FE0F – ⚛️
U+2618 – ☘︎
U+2618 U+FE0F – ☘️
Simple, elegant, and no need to allocate new codepoints while the old ones are already there. After all, things like ☠︎ and ☠️ have the same _meaning_, only the presentation is different.
Here we encounter another problem — our emoji are now not a single codepoint, but two. This means we need a way to define character boundaries.
Meet Grapheme Clusters. Grapheme cluster is a sequence of codepoints that is considered a single human-perceived glyph.
Grapheme Clusters were not invented just for emoji, they apply to normal alphabets too. “Ü” is a single grapheme cluster, even though it’s composed of two codepoints: U+0055 UPPER-CASE U followed by U+0308 COMBINING DIAERESIS.
Grapheme clusters create many complications for programmers. You can’t just do `substring(0, 10)` to take the first 10 characters—you might split an emoji in half (or an acute, so don’t do it anyway)!
Reversing a string is tricky, too—while U+263A U+FE0F makes sense, U+FE0F U+263A does not.

Finally, you can’t just call .length on a string. Well, you can, but the result will surprise you. If you a developer, try this:
"🤦🏼♂️".length
in your browser’s console.
"🤦🏼♂️".length
in your browser’s console.
A tip for programmers: if you are working with text, get a library that is grapheme clusters-aware. For C, C++m and JVM that would be ICU site.icu-project.org, Swift does the right thing out-of-the-box, for others, see for yourself.
Grapheme clusters awareness month, anyone? Graphemes don’t want to be split!
Oh, who am I kidding?
for (int i = 0; i < str.length; ++i)
str[i]
go brrr!
Oh, who am I kidding?
for (int i = 0; i < str.length; ++i)
str[i]
go brrr!
Oh, by the way, did I mentioned that this: Ų̷̡̡̨̫͍̟̯̣͎͓̘̱̖̱̣͈͍̫͖̮̫̹̟̣͉̦̬̬͈͈͔͙͕̩̬̐̏̌̉́̾͑̒͌͊͗́̾̈̈́̆̅̉͌̋̇͆̚̚̚͠ͅ is a single grapheme cluster, too? Its length is 65, and it shouldn’t ever be split in half. Sleep tight 🛌 :)
Most human Emoji depict an abstract yellow person.
When skin tone was added in 2015, instead of adding a new codepoint for each emoji and skin tone combination, only five new codepoints were added: 🏻🏼🏽🏾🏿 U+1F3FB..U+1F3FF.
When skin tone was added in 2015, instead of adding a new codepoint for each emoji and skin tone combination, only five new codepoints were added: 🏻🏼🏽🏾🏿 U+1F3FB..U+1F3FF.
These are not supposed to be used on their own but to be appended to the existing emoji.
Together they form a ligature: 👋 (U+1F44B WAVING HAND SIGN) directly followed by 🏽 (U+1F3FD MEDIUM SKIN TONE MODIFIER) becomes 👋🏽.
Together they form a ligature: 👋 (U+1F44B WAVING HAND SIGN) directly followed by 🏽 (U+1F3FD MEDIUM SKIN TONE MODIFIER) becomes 👋🏽.
👋🏽 does not have its own codepoint (it’s a sequence of two: U+1F44B U+1F3FD), but it has its own unique look.
With just five modifiers, \~280 human emojis got turned into 1680 variations.
Here’re some dancers:
🕺🕺🏻🕺🏼🕺🏽🕺🏾🕺🏿
With just five modifiers, \~280 human emojis got turned into 1680 variations.
Here’re some dancers:
🕺🕺🏻🕺🏼🕺🏽🕺🏾🕺🏿
Let’s say your friend just sent you a picture of an apple she is growing in her garden.
You need to reply—how? You might send a 👩 WOMAN EMOJI (U+1F469), followed by a 🌾 SHEAF OF RICE (U+1F33E).
If you put the two together: 👩🌾, nothing happens. It’s just two separate emoji.
You need to reply—how? You might send a 👩 WOMAN EMOJI (U+1F469), followed by a 🌾 SHEAF OF RICE (U+1F33E).
If you put the two together: 👩🌾, nothing happens. It’s just two separate emoji.
But! If you add U+200D in between, magic happens: they turn into the one 👩🌾 woman farmer.
U+200D is called ZERO-WIDTH JOINER, or ZWJ for short.
It works similarly to what we saw with skin tone, but this time you can join two self-sufficient emoji into one.
Not all combinations work, but many do, sometimes in surprising ways!
It works similarly to what we saw with skin tone, but this time you can join two self-sufficient emoji into one.
Not all combinations work, but many do, sometimes in surprising ways!
Some examples:
👩 + ✈️ → 👩✈️
👨 + 💻 → 👨💻
👰 + ♂️ → 👰♂️
🐻 + ❄️ → 🐻❄️
🏴 + ☠️ → 🏴☠️
🏳️ + 🌈 → 🏳️🌈
👩 + ✈️ → 👩✈️
👨 + 💻 → 👨💻
👰 + ♂️ → 👰♂️
🐻 + ❄️ → 🐻❄️
🏴 + ☠️ → 🏴☠️
🏳️ + 🌈 → 🏳️🌈
One weird inconsistency I’ve noticed is that hair color is done via ZWJ, while skin tone is just modifier emoji with no joiner. Why? Seriously, I am asking you: why? I have no clue.
👨 + 🏿 U+1F3FF → 👨🏿
👨 + ZWJ + 🦰 → 👨🦰
👨 + 🏿 U+1F3FF → 👨🏿
👨 + ZWJ + 🦰 → 👨🦰
Unfortunately, some emoji are NOT implemented as combinations with ZWJ.
Missing opportunities:
👨 + 🦷 ≠ 🧛
👨 + 💀 ≠ 🧟
👩 + 🔍 ≠ 🕵️♀️
👁 + 👁 ≠ 👀
💄 + 👄 ≠ 💋
🌂 + 🌧 ≠ ☔️
🐴 + 🌈 ≠ 🦄
🍚 + 🐟 ≠ 🍣
🐈 + 🦓 ≠ 🐅
🦵 + 🦵 + 💪 + 💪 + 👂 + 👂 + 👃 + 👅 + 👀 + 🧠 ≠ 🧍
Missing opportunities:
👨 + 🦷 ≠ 🧛
👨 + 💀 ≠ 🧟
👩 + 🔍 ≠ 🕵️♀️
👁 + 👁 ≠ 👀
💄 + 👄 ≠ 💋
🌂 + 🌧 ≠ ☔️
🐴 + 🌈 ≠ 🦄
🍚 + 🐟 ≠ 🍣
🐈 + 🦓 ≠ 🐅
🦵 + 🦵 + 💪 + 💪 + 👂 + 👂 + 👃 + 👅 + 👀 + 🧠 ≠ 🧍
Another big area where ZWJ shines is families and relationships configuration.
A short story to illustrate:
👨🏻 + 🤝 + 👨🏼 → 👨🏻🤝👨🏼
👨 + ❤️ + 👨 → 👨❤️👨
👨 + ❤️ + 💋 + 👨 → 👨❤️💋👨
👨 + 👨 + 👧 → 👨👨👧
👨 + 👨 + 👧 + 👧 → 👨👨👧👧
A short story to illustrate:
👨🏻 + 🤝 + 👨🏼 → 👨🏻🤝👨🏼
👨 + ❤️ + 👨 → 👨❤️👨
👨 + ❤️ + 💋 + 👨 → 👨❤️💋👨
👨 + 👨 + 👧 → 👨👨👧
👨 + 👨 + 👧 + 👧 → 👨👨👧👧
Country flags!
Flags don’t have dedicated codepoints. Instead, they are two-letter ligatures.
🇺 + 🇳 = 🇺🇳
🇷 + 🇺 = 🇷🇺
🇮 + 🇸 = 🇮🇸
🇿 + 🇦 = 🇿🇦
🇯 + 🇵 = 🇯🇵
Flags don’t have dedicated codepoints. Instead, they are two-letter ligatures.
🇺 + 🇳 = 🇺🇳
🇷 + 🇺 = 🇷🇺
🇮 + 🇸 = 🇮🇸
🇿 + 🇦 = 🇿🇦
🇯 + 🇵 = 🇯🇵
For letters, special “regional indicator symbol letter” alphabet is used (U+1F1E6..1F1FF).
🇦 🇧 🇨 🇩 🇪 🇫 🇬 🇭 🇮 🇯 🇰 🇱 🇲 🇳 🇴 🇵 🇶 🇷 🇸 🇹 🇺 🇻 🇼 🇽 🇾 🇿
There are 258 valid two-letter combinations. Can you guess them all?
🇦 🇧 🇨 🇩 🇪 🇫 🇬 🇭 🇮 🇯 🇰 🇱 🇲 🇳 🇴 🇵 🇶 🇷 🇸 🇹 🇺 🇻 🇼 🇽 🇾 🇿
There are 258 valid two-letter combinations. Can you guess them all?
A funny side-effect of being two-letter ligature:
''.join(reversed('🇺🇦')) => '🇦🇺'
''.join(reversed('🇺🇦')) => '🇦🇺'
Two-letter ligatures are cool, but don’t you want to be cooler? How about 32-letter ligatures? Meet tag sequences.
Tag sequence is a sequence of normal emoji, followed by another flavor of Latin letters (U+E0020..E007E), terminated with U+E007F CANCEL TAG.
Currently they are used for these three flags only: England, Scotland and Wales:
🏴 + gbeng + E007F = 🏴
🏴 + gbsct + E007F = 🏴
🏴 + gbwls + E007F = 🏴
🏴 + gbeng + E007F = 🏴
🏴 + gbsct + E007F = 🏴
🏴 + gbwls + E007F = 🏴
Not super-exciting, but needed for completeness: keycap sequences use yet another convention.
It goes like this: take a digit, * or #, turn it into emoji with U+FE0F, wrap into a square with U+20E3 COMBINING ENCLOSING KEYCAP:
* + FE0F + 20E3 = *️⃣
* + FE0F + 20E3 = *️⃣
In total there are only twelve of them:
#️⃣ *️⃣ 0️⃣ 1️⃣ 2️⃣ 3️⃣ 4️⃣ 5️⃣ 6️⃣ 7️⃣ 8️⃣ 9️⃣
#️⃣ *️⃣ 0️⃣ 1️⃣ 2️⃣ 3️⃣ 4️⃣ 5️⃣ 6️⃣ 7️⃣ 8️⃣ 9️⃣
Unicode is updated every year, and emoji are a major part of each release. E.g. in Unicode 13 (March 2020), 55 new Emoji were added.
At the moment of writing neither the latest macOS (11.2.3) nor iOS (14.4.1) support emoji from Unicode 13 like
😮💨, ❤️🔥, 🧔♀ or 👨🏻❤️💋👨🏼
😮💨, ❤️🔥, 🧔♀ or 👨🏻❤️💋👨🏼
For future generations, this is what I see in March 2021 on latest macOS and on Twitter 👇
But, thanks to the magic of ZWJ, I can still figure out what’s going on, just not in the most optimal way.
But, thanks to the magic of ZWJ, I can still figure out what’s going on, just not in the most optimal way.

To sum up, these are seven ways emoji can be encoded:
1. A single codepoint 🧛 U+1F9DB
2. Single codepoint + variation selector-16 ☹︎ U+2639 + U+FE0F = ☹️
3. Skin tone modifier 🤵 U+1F935 + U+1F3FD = 🤵🏽
4. Zero-width joiner sequence 👨 + ZWJ + 🏭 = 👨🏭
5. 👇
1. A single codepoint 🧛 U+1F9DB
2. Single codepoint + variation selector-16 ☹︎ U+2639 + U+FE0F = ☹️
3. Skin tone modifier 🤵 U+1F935 + U+1F3FD = 🤵🏽
4. Zero-width joiner sequence 👨 + ZWJ + 🏭 = 👨🏭
5. 👇
5. Flags 🇦 + 🇱 = 🇦🇱
6. Tag sequences 🏴 + gbsct + U+E007F = 🏴
7. Keycap sequences * + U+FE0F + U+20E3 = *️⃣
6. Tag sequences 🏴 + gbsct + U+E007F = 🏴
7. Keycap sequences * + U+FE0F + U+20E3 = *️⃣
Techniques from 1-4 can be combined to construct a pretty complex message:
U+1F6B5 🚵 Person Mountain Biking
+ U+1F3FB Light Skin Tone
+ U+200D ZWJ
+ U+2640 ♀️Female Sign
+ U+FE0F Variation selector-16
= 🚵🏻♀️ Woman Mountain Biking: Light Skin Tone
U+1F6B5 🚵 Person Mountain Biking
+ U+1F3FB Light Skin Tone
+ U+200D ZWJ
+ U+2640 ♀️Female Sign
+ U+FE0F Variation selector-16
= 🚵🏻♀️ Woman Mountain Biking: Light Skin Tone
If you are a programmer, remember to use the ICU library to:
- extract a substring,
- measure string length,
- reverse a string.
The keyword to google is “Grapheme Cluster”. It applies to emoji, to diacritics in Western languages, to Indic and Korean scripts. Please be aware.
- extract a substring,
- measure string length,
- reverse a string.
The keyword to google is “Grapheme Cluster”. It applies to emoji, to diacritics in Western languages, to Indic and Korean scripts. Please be aware.
That’s all I have. I hope the deeper understanding of how emoji work under the hood will help you in your work...
Nah, just kidding. Hope you enjoyed it, though ✌️
Nah, just kidding. Hope you enjoyed it, though ✌️
• • •
Missing some Tweet in this thread? You can try to
force a refresh



