
Normalization vs Standardization: Apa, Kenapa, dan Gimana?
A Simple Guide to Feature Scaling
.
.
.
A thread
A Simple Guide to Feature Scaling
.
.
.
A thread
Kalau dipikir-pikir, sebenernya jadi DS sama jadi chef itu sama aja. Sama-sama preprocessing ‘ingredients’ nya. Sama-sama modeling dan tuning ‘resep’ nya. Sama-sama deploy ke customer nya. Dan kalau customer bilang “Mas, kok kurang enak?”, sama-sama update resepnya.
Atau ketika seorang chef membuat strawberry-banana smoothie misalnya, nggak semudah mencampur satu pisang utuh dan satu stroberi aja kan? Karena tentu nanti yang terasa cuma pisang nya aja. Atau dengan kata lain, smoothie nya akan ‘bias’ ke pisang. 

Sehingga supaya tercipta cita rasa yang seimbang, proporsi pisang nya perlu diperkecil, bisa dengan dipakai separuhnya aja atau dipotong kecil-kecil. Terserah, but the point is, perlu dilakukan scaling ulang terhadap ‘ingredients’ yang digunakan.

And believe it or not, the very same principle, ternyata ada implementasinya juga dalam dunia per-ML-an. Terkadang, kita perlu scaling ulang data yang dimiliki, simply agar model tidak ‘bias’ terhadap suatu feature tertentu pada data. Contoh klasiknya seperti ini.

Feature ‘Salary’ itu skalanya puluhan ribu, sedangkan feature ‘Age’ mentok-mentok 50. Layaknya kasus pisang tadi, proporsi yang imbalanced ini bisa jadi masalah karena somehow model akan belajar untuk bias, menganggap ‘Salary’ jauh lebih penting daripada ‘Age’.
Solusinya? Kita perlu membuat features pada data berada dalam suatu skala yang sama, a common scale. Nah, teknik ini yang disebut dengan ‘feature scaling’. Fungsinya untuk ‘suppressing’ efek bias model terhadap suatu feature hanya karena range magnitude nya.
Terus gimana min caranya? Nah sebelum ke sana, mungkin dari temen-temen ada yang bertanya-tanya, “Apakah setiap model machine learning memerlukan data nya untuk dilakukan feature scaling terlebih dahulu?”
Untuk model yang tree-based, seperti Decision Tree, Random Forest, atau untuk ensemble model yang sebenernya isinya decision trees juga, seperti Gradient Boost, XGBoost, atau AdaBoost, feature scaling nggak akan banyak berpengaruh terhadap performa model.
At the end of the day, dalam prosesnya mereka simply akan membuat decision tree yang didasarkan pada set aturan tertentu -- ‘jika ini maka itu’. Artinya, range magnitude dari feature tidak akan banyak berpengaruh terhadap proses pengambilan keputusan.

Tapi untuk model yang distance-based, seperti Linear Regression, Logistic Regression, KNN, atau K-Means Clustering, feature scaling akan sangat berpengaruh terhadap performa. Pada neural network, feature scaling juga mempercepat model konvergen pada gradient descent.

Karena yang dipakai adalah fungsi jarak -- umumnya euclidean distance -- untuk meminimalkan error, ‘besar’ dari feature menjadi penting. Semakin besar nilai nya, semakin jauh jaraknya dengan feature lain sehingga semakin sulit bagi model untuk konvergen ke parameter terbaik.
Now to the main part! Salah dua teknik yang umum digunakan dalam feature scaling adalah normalization dan standardization. Keduanya sama-sama membuat data ke dalam suatu skala tertentu, sama-sama membuat data menjadi ‘unitless’, but in a different way.

Normalization memetakan setiap nilai data menjadi suatu nilai baru yang berada dalam rentang 0 sampai 1. Nilai data terbesar akan jadi 1, dan nilai terkecil akan jadi 0. Di scikit-learn, normalization diimplementasikan simply dengan menggunakan MinMaxScaler().
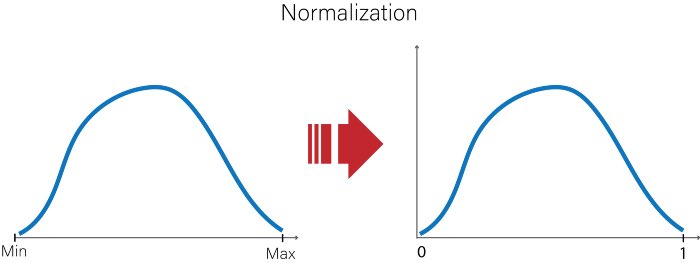
It is worth mentioning bahwa normalization itu pada dasarnya adalah ‘squeezing’ semua data ke dalam range [0,1], yang batas-batas nya adalah nilai maksimum dan minimum data training. Simpel banget min? Yess, tapi mungkin ada yang kebayang apa masalah nya di sini.

Ketika model yang di-training menggunakan data yang di-normalized itu kita beri input yang nilainya lebih besar dari nilai maksimum pada data training misalnya, maka nilainya akan berada di luar range [0,1]. Hal ini mengakibatkan normalization menjadi sensitif terhadap outlier.
Kalau standardization gimana min? Nah, sebelum ke situ, kita perlu diskusi dulu nih mengenai salah satu distribusi dalam statistika yang mimin yakin temen-temen di sini pasti kenal, Gaussian distribution!
Gaussian distribution, atau dikenal dengan ‘distribusi normal’, adalah distribusi proba yang mayoritas datanya ‘ngumpul’ di sekitar mean. Gimana mastiin suatu feature berdistribusi normal atau nggak? Nah, distribusi normal punya 3 ciri yang disebut dengan ‘empirical rule’.

Jika suatu feature berdistribusi normal, maka ≈68% datanya ada dalam jarak 1 standar deviasi σ dari nilai mean μ, ≈95% data ada dalam jarak 2σ dari μ, serta ≈99.7% data ada dalam 3σ dari μ. Empirical rule ini disebut juga dengan ‘three-sigma rule’ atau ‘68-95-99.7 rule’.
Nilai mean, median, dan modus dari distribusi normal juga kurang lebih berhimpit pada satu titik yang sama di pusat data. Nah, ciri inilah yang akhirnya membuat distribusi normal terkenal dengan bentuknya yang ikonik menyerupai lonceng atau yang disebut dengan ‘bell curve’.

Konsep distribusi normal ini penting banget temen-temen. Banyak ‘natural phenomena’ yang berdistribusi normal sehingga distribusi ini sering ditemui dalam analisis statistik. And yess, konsep ini juga yang menjadi dasar dari teknik feature scaling berikutnya, standardization!

Dalam standardization, setiap data pada feature ditransformasi sedemikian rupa sehingga diperoleh feature baru yang berdistribusi normal ‘standar’ (Standard Normal Distribution), yaitu distribusi normal yang nilai mean nya (μ) = 0 dan standar deviasi nya (σ) = 1.

Artinya, selain range data pada feature di scale ulang, standardization sekaligus akan berusaha menghasilkan feature baru yang punya properti distribusi normal standar! Di scikit-learn, standardization bisa diimplementasikan dengan StandardScaler().

Kebayang dong kapan pakai standardization? Standardization berasumsi bahwa data pada feature SUDAH berdistribusi normal in the first place. Feature yang berdistribusi normal ini lalu kita ‘standardize’ menjadi distribusi normal ‘standar’.
Tapi, kalau kita nggak tahu distribusi nya apa, atau kalau kita tahu bahwa distribusi nya BUKAN distribusi normal, maka normalization bisa jadi pilihan yang tepat karena nggak ada ‘underlying assumption’ bahwa data nya memiliki distribusi tertentu.

As a side note, sebenarnya nggak ada aturan baku nya yang strict. Mungkin bisa aja data nya ‘is not really normally-distributed’, tapi performa dengan standardization nya ‘is still okay’. Nah, ini jadi ladang kita buat explore and know much better data yang kita miliki!
But the point is, buat use case di mana data dalam feature jelas sudah ‘normally distributed’, maka feature scaling dengan standardization akan jadi pilihan yang sangat fit dan recommended buat diimplementasiin dalam kasus tersebut.
Data yang ‘normally-distributed’ itu emang jadi primadona buat banyak model ML. Dan ada banyak juga teknik yang bisa membuat data jadi lebih ‘Gaussian-like’, misalnya Box-Cox transformation, Johnson transformation, dsb. Mungkin nanti yaa mimin kapan-kapan bahas
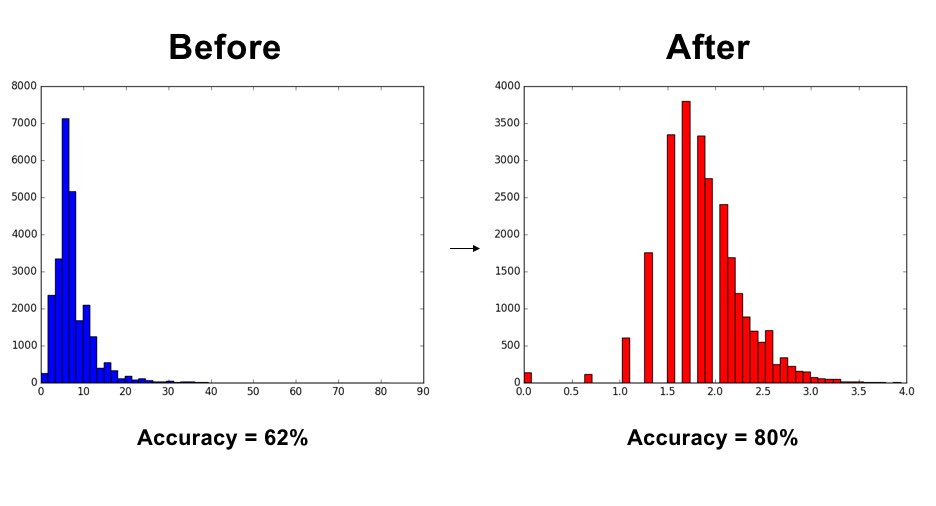
Nah, insight apa nih yang bisa kita ambil?
Jadi DS itu bukan cuma soal modeling dan fitting-fitting aja, tapi juga harus bisa mengenali dengan baik datanya, preprocessing seperti apa yang sesuai buat mengolahnya, apa ‘underlying assumption’ nya, serta model apa yang cocok buat datanya.
‘Garbage in, garbage out!’ katanya ya, kan? Mau performa modelnya bagus? Data nya juga harus bagus. Mau datanya bagus? Preprocessing nya harus bagus. Dan mau preprocessing nya bagus? Know your data ‘intimately’!
Kalau megang data masih suka bingung ‘Ini harus diapain dulu ya?’ dan pengen belajar cara menganalisis data dengan baik dan benar, langsung aja gabung di non-degree program Data Scientist / Business Intelligence Pacmann.AI
Oh ya, 💸Promo Early Bird💸 untuk BATCH 3 masih berlaku loh! Yuk, daftarin diri kalian sekarang juga ke Program Non Degree Pacmann! klik infonya dibawah ini yaaa 😊👇🏼
untuk info lebih lanjut, bisa juga hubunginWA kami di bit.ly/WASalesPacmann
See you! 😊👋🏼
untuk info lebih lanjut, bisa juga hubunginWA kami di bit.ly/WASalesPacmann
See you! 😊👋🏼
https://twitter.com/pacmannai/status/1377840524829204482
• • •
Missing some Tweet in this thread? You can try to
force a refresh












