
A lot in machine learning is pretty dry and boring, but understanding how autoencoders work feels different.
This is a thread about autoencoders, things they can do, and a pretty cool example.
↓ 1/10
This is a thread about autoencoders, things they can do, and a pretty cool example.
↓ 1/10
Autoencoders are lossy data compression algorithms built using neural networks.
A network encodes (compresses) the original input into an intermediate representation, and another network reverses the process to get the same input back.
↓ 2/10
A network encodes (compresses) the original input into an intermediate representation, and another network reverses the process to get the same input back.
↓ 2/10
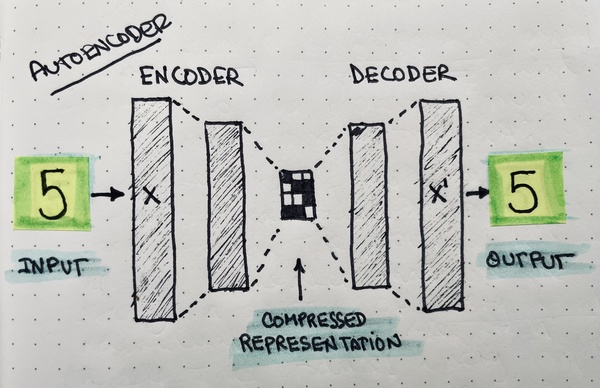
The encoding process "generalizes" the input data.
I like to think of it as the Summarizer in Chief of the network: its entire job is to represent the entire dataset as compactly as possible, so the decoder can do a decent job at reproducing the original data back.
↓ 3/10
I like to think of it as the Summarizer in Chief of the network: its entire job is to represent the entire dataset as compactly as possible, so the decoder can do a decent job at reproducing the original data back.
↓ 3/10
Autoencoders are very useful to detect anomalies in the data.
Any uncommon characteristics in the input data will never make it past the autoencoder’s bottleneck.
The autoencoder has to be very picky at which features it learns. It will throw away anything uncommon.
↓ 4/10
Any uncommon characteristics in the input data will never make it past the autoencoder’s bottleneck.
The autoencoder has to be very picky at which features it learns. It will throw away anything uncommon.
↓ 4/10
For example, let's train an autoencoder with pictures of bananas.
The autoencoder will get really good at reproducing the original picture back because it’s learned how to represent them.
What would happen if you show the autoencoder a rotten banana instead?
↓ 5/10
The autoencoder will get really good at reproducing the original picture back because it’s learned how to represent them.
What would happen if you show the autoencoder a rotten banana instead?
↓ 5/10

Well, the autoencoder didn’t learn to represent rotten bananas, so the decoder will never be able to reproduce it back correctly.
The result will look like a ripe banana because that’s all the information the decoder had 🤷♂️.
↓ 6/10
The result will look like a ripe banana because that’s all the information the decoder had 🤷♂️.
↓ 6/10
Now, you can take the original image and compute the difference with the output.
If the difference is small, there's no anomaly. If the difference is large, the autoencoder couldn't reproduce the original image, which means there's an anomaly.
↓ 7/10
If the difference is small, there's no anomaly. If the difference is large, the autoencoder couldn't reproduce the original image, which means there's an anomaly.
↓ 7/10
Autoencoders aren't only useful to detect anomalies.
What would happen if we teach an autoencoder to transform the input image into something else?
↓ 8/10
What would happen if we teach an autoencoder to transform the input image into something else?
↓ 8/10
For example, we could teach an autoencoder to remove noise from pictures by showing it images with noise and expecting back their corresponding clean version.
Here, the encoder will develop an intermediate representation that helps the decoder produce clean pictures.
↓ 9/10
Here, the encoder will develop an intermediate representation that helps the decoder produce clean pictures.
↓ 9/10

After we train this autoencoder, we can remove noise from any picture similar to the input dataset!
I built an example to remove noise. Find it here: keras.io/examples/visio….
And for more information about autoencoders, you can go here: jeremyjordan.me/autoencoders/.
10/10
I built an example to remove noise. Find it here: keras.io/examples/visio….
And for more information about autoencoders, you can go here: jeremyjordan.me/autoencoders/.
10/10
This thread is an adaptation of an article I posted for my newsletter subscribers.
If you found it helpful, follow me @svpino for more machine learning-related content just like this.
Like/retweet the top tweet of the thread so others can also see it:
If you found it helpful, follow me @svpino for more machine learning-related content just like this.
Like/retweet the top tweet of the thread so others can also see it:
https://twitter.com/svpino/status/1381253209163988998?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh





