

Bart uses a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a left-to-right decoder (like GPT) 

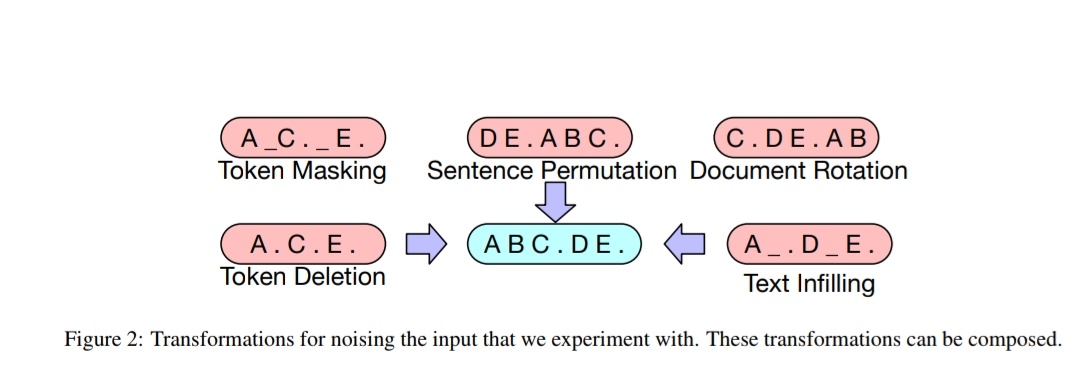
The pretraining task involves randomly shuffling the order of the original sentences and a novel in-filling scheme, where spans of text are replaced with a single mask token.
NLP Benchmark Tasks: BART performs comparably to RoBERTa and
XLNet.
XLNet.

Paper: arxiv.org/abs/1910.13461
• • •
Missing some Tweet in this thread? You can try to
force a refresh


