
What actually happens when you call .backwards() in @PyTorch?
Autograd goodness 🪄!
PyTorch keeps track of all of the computations you’ve done on each of your tensors and .backwards() triggers it to compute the gradients and stores them in .grad.
1/3
Autograd goodness 🪄!
PyTorch keeps track of all of the computations you’ve done on each of your tensors and .backwards() triggers it to compute the gradients and stores them in .grad.
1/3
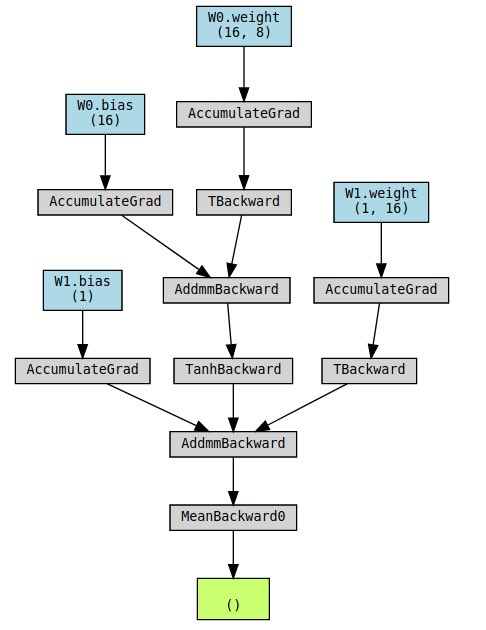
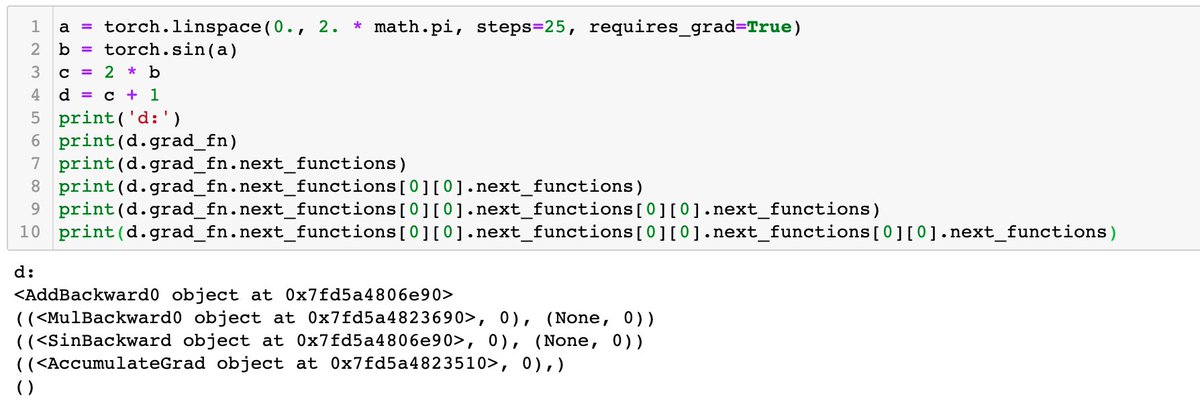
You can see the gradient functions by looking at .grad_fn of your tensors after each computation.
You can see the entire graph by looking at .next_functions recursively.
Or you can use github.com/szagoruyko/pyt… by @szagoruyko5
2/3
You can see the entire graph by looking at .next_functions recursively.
Or you can use github.com/szagoruyko/pyt… by @szagoruyko5
2/3
This is a good video from the @PyTorch YouTube channel that goes through the fundamentals of autograd if you’d like to learn more about it.
3/3
3/3
Another autodiff explanation for those looking for some more info about it.
This has brilliant animations and some of the considerations around the implementation.
This has brilliant animations and some of the considerations around the implementation.
https://twitter.com/ari_seff/status/1289284199157923840
• • •
Missing some Tweet in this thread? You can try to
force a refresh










