Helping build AI dev tools at @weights_biases. I post about AI, data visualisation and the stuff I’m working on at wandb.

 The plot above shows how each of your experiments performed on the task.
The plot above shows how each of your experiments performed on the task.
 Technical debt is a way of framing the cost of taking shortcuts with your software development.
Technical debt is a way of framing the cost of taking shortcuts with your software development.  Data lineage is the process of keeping track of the origin of your data and tracking versions of it over time.
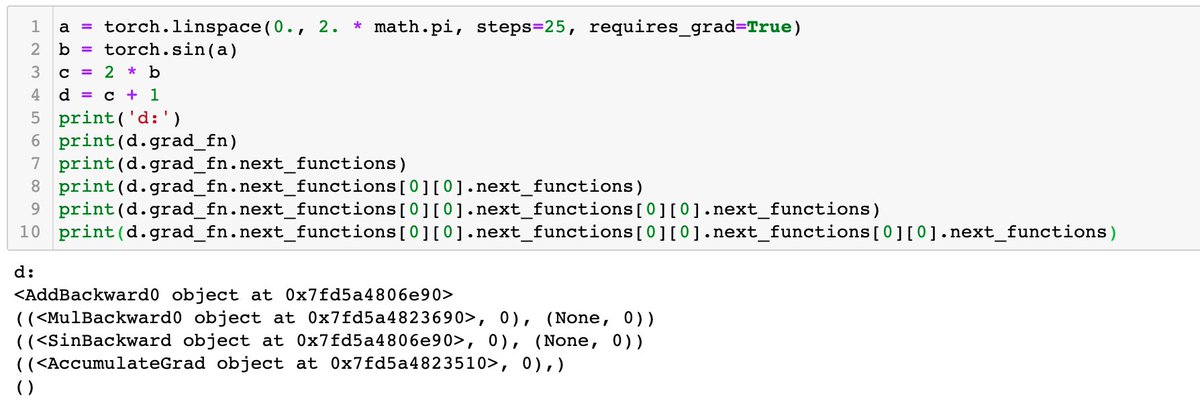
Data lineage is the process of keeping track of the origin of your data and tracking versions of it over time.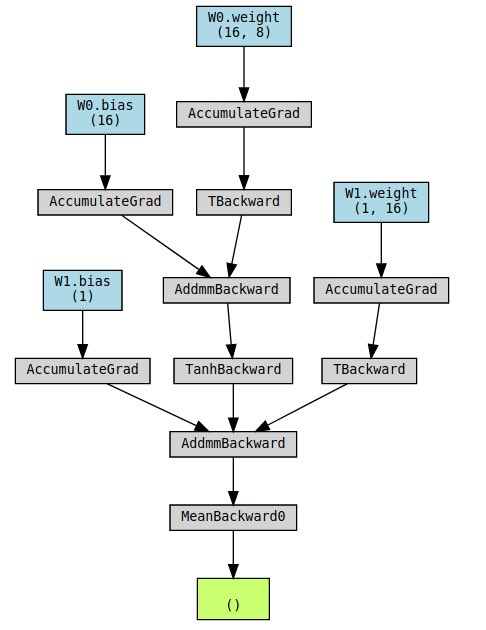 You can see the gradient functions by looking at .grad_fn of your tensors after each computation.
You can see the gradient functions by looking at .grad_fn of your tensors after each computation.