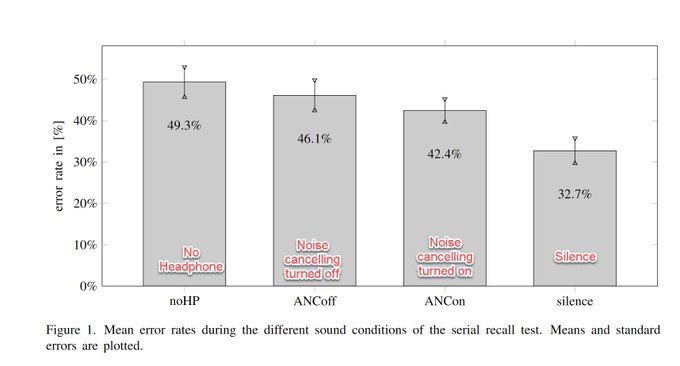
One of my favorite scientific figures is this one of the entropy levels of 100 world cities by the orientation of streets. The cities with most ordered streets: Chicago, Miami, & Minneapolis. Most disordered: Charlotte, Sao Paulo, Rome & Singapore. Paper: appliednetsci.springeropen.com/articles/10.10… 

To illustrate, here is how the maps look for Minneapolis (most ordered) & Charlotte (most disordered), rendered with this amazing tool for showing maps of roads by @anvaka: anvaka.github.io/city-roads/?q=…


Here's the cities organized by alphabetical order from the paper (by @gboeing )

On a related note, here is the alignment of runways around the world, along with a rather amazing global zoomable map 👇 of every runway & how it is oriented.
https://twitter.com/emollick/status/1400609222757392384

To lower your city’s entropy level, use this map extending the streets & avenues of New York’s grid to cover the world. 10 Downing Street is really 3,709th Street & East 10,894th Avenue. All roads meet in Ishkuduk, Uzbekistan, the antipodean anti-New York. extendny.com/#S22.St.4.Ave/9


Also on the topic of roads: 2,000 years later, the paths of Roman roads explain economic development patterns in Europe, but not so much in North Africa, where the general use of camels after 100BCE led to less need for wheeled vehicles. (Cool subway-style maps by @sasha_trub)




• • •
Missing some Tweet in this thread? You can try to
force a refresh