*Score-based diffusion models*
An emerging approach in generative modelling that is gathering more and more attention.
If you are interested, I collected some introductive material and thoughts in a small thread. 👇
Feel free to weigh in with additional material!
/n
An emerging approach in generative modelling that is gathering more and more attention.
If you are interested, I collected some introductive material and thoughts in a small thread. 👇
Feel free to weigh in with additional material!
/n
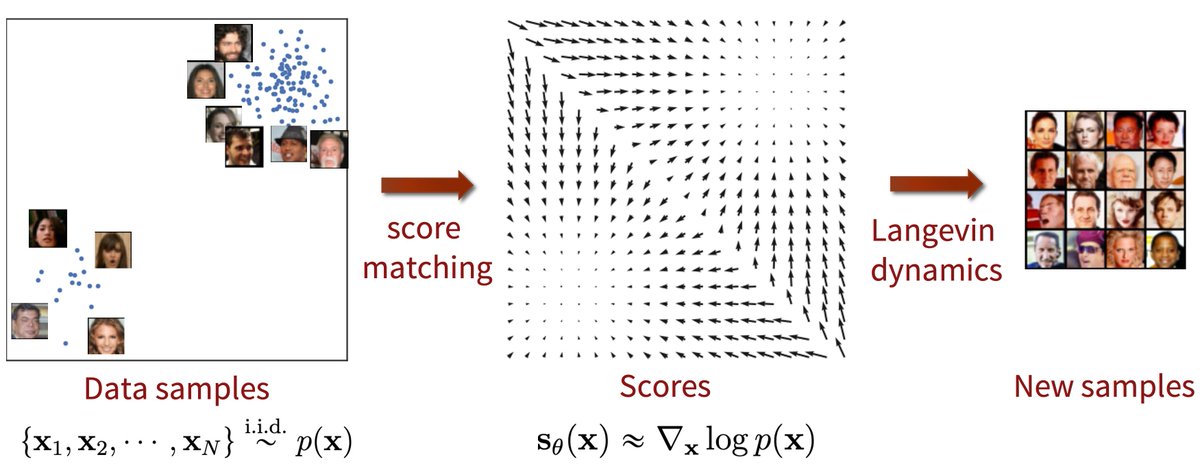
An amazing property of diffusion models is simplicity.
You define a probabilistic chain that gradually "noise" the input image until only white noise remains.
Then, generation is done by learning to reverse this chain. In many cases, the two directions have similar form.
/n
You define a probabilistic chain that gradually "noise" the input image until only white noise remains.
Then, generation is done by learning to reverse this chain. In many cases, the two directions have similar form.
/n

The starting point for diffusion models is probably "Deep Unsupervised Learning using Nonequilibrium Thermodynamics" by @jaschasd Weiss @niru_m @SuryaGanguli
Classic paper, definitely worth reading: arxiv.org/abs/1503.03585
/n
Classic paper, definitely worth reading: arxiv.org/abs/1503.03585
/n

A cornerstone in diffusion models is the introduction of "denoising" versions by @hojonathanho @ajayj_ @pabbeel
They showed how to make diffusion models perform close to the state-of-the-art using a suitable reformulation of their training objective.
/n
They showed how to make diffusion models perform close to the state-of-the-art using a suitable reformulation of their training objective.
/n

It turns out that the improved version is also simpler than the original one!
Roughly, it works by adding noise to an image, and learning to denoise the image itself.
In this way, training is connected to denoising autoencoders, and sampling remains incredibly easy.
/n
Roughly, it works by adding noise to an image, and learning to denoise the image itself.
In this way, training is connected to denoising autoencoders, and sampling remains incredibly easy.
/n

Denoising diffusion turns out to be similar to "score-based" models, pioneered by @YSongStanford and @StefanoErmon
@YSongStanford has written an outstanding blog post on these ideas, so I'll just skim some of the most interesting connections: yang-song.github.io/blog/2021/scor…
/n
@YSongStanford has written an outstanding blog post on these ideas, so I'll just skim some of the most interesting connections: yang-song.github.io/blog/2021/scor…
/n
Score-based models work by learning an estimator for the score function of the distribution (ie, the gradient of the log).
Langevin dynamics allows to sample from p(x) having only access to the estimator of the score function.
Reference paper here: arxiv.org/abs/1907.05600
/n
Langevin dynamics allows to sample from p(x) having only access to the estimator of the score function.
Reference paper here: arxiv.org/abs/1907.05600
/n

Naive score-based models are uncommon, because sampling starts in poorly approximated regions.
The solution is noise-conditional score models, that perturb the original input, and generate data using "annealed" Langevin dynamics.
arxiv.org/abs/2006.09011
The solution is noise-conditional score models, that perturb the original input, and generate data using "annealed" Langevin dynamics.
arxiv.org/abs/2006.09011

Noise-conditional score-based models and denoised diffusion models are almost equivalent, basically a single family of models.
A few additional improvements obtain performance close to BigGAN on complex datasets, as shown by @prafdhar @unixpickle
arxiv.org/abs/2105.05233
/n
A few additional improvements obtain performance close to BigGAN on complex datasets, as shown by @prafdhar @unixpickle
arxiv.org/abs/2105.05233
/n

Interestingly, when the noise variance goes from discrete values to a continuous distribution, score-based models connect to neural SDEs and continuous normalizing flows!
This was shown in a #ICLR2021 paper by @YSongStanford @jaschasd @dpkingma Kumar @StefanoErmon @poolio
/n
This was shown in a #ICLR2021 paper by @YSongStanford @jaschasd @dpkingma Kumar @StefanoErmon @poolio
/n

The field is exploding, too many interesting papers to cite!
For example, a recent one by @YSongStanford @conormdurkan @driainmurray @StefanoErmon shows that a formulation of score-based models is upper-bounding a maximum likelihood objective.
arxiv.org/pdf/2101.09258…
/n
For example, a recent one by @YSongStanford @conormdurkan @driainmurray @StefanoErmon shows that a formulation of score-based models is upper-bounding a maximum likelihood objective.
arxiv.org/pdf/2101.09258…
/n

Another personal favorite: multinomial diffusion and argmax flows extend score-based models and flows to discrete data distributions!
by @emiel_hoogeboom @nielsen_didrik @priyankjaini
Forré @wellingmax
arxiv.org/abs/2102.05379
/n
by @emiel_hoogeboom @nielsen_didrik @priyankjaini
Forré @wellingmax
arxiv.org/abs/2102.05379
/n

I could go on with my new love, but I'll stop. 🙃
Another nice blog post on score-based models: ajolicoeur.wordpress.com/the-new-conten…
Introductive video by @StefanoErmon:
Lots of code in the blog post by @YSongStanford!
Or you can play w/ github.com/lucidrains/den…
Another nice blog post on score-based models: ajolicoeur.wordpress.com/the-new-conten…
Introductive video by @StefanoErmon:
Lots of code in the blog post by @YSongStanford!
Or you can play w/ github.com/lucidrains/den…
• • •
Missing some Tweet in this thread? You can try to
force a refresh