
I fall in love with a new #machinelearning topic every month 🙄 |
Researcher @SapienzaRoma | Author: Alice in a diff wonderland https://t.co/A2rr19d3Nl
 It all started from her belief that "very few things indeed were really impossible". Could AI truly be below the corner? Could differentiability be the only ingredient that was needed?
It all started from her belief that "very few things indeed were really impossible". Could AI truly be below the corner? Could differentiability be the only ingredient that was needed?
 *Flow Network based Generative Models for Non-Iterative Diverse Candidate Generation*
*Flow Network based Generative Models for Non-Iterative Diverse Candidate Generation*
 Here is my overview of everything that can happen when we have > 1 "task": fine-tuning, pre-training, meta learning, continual learning...
Here is my overview of everything that can happen when we have > 1 "task": fine-tuning, pre-training, meta learning, continual learning...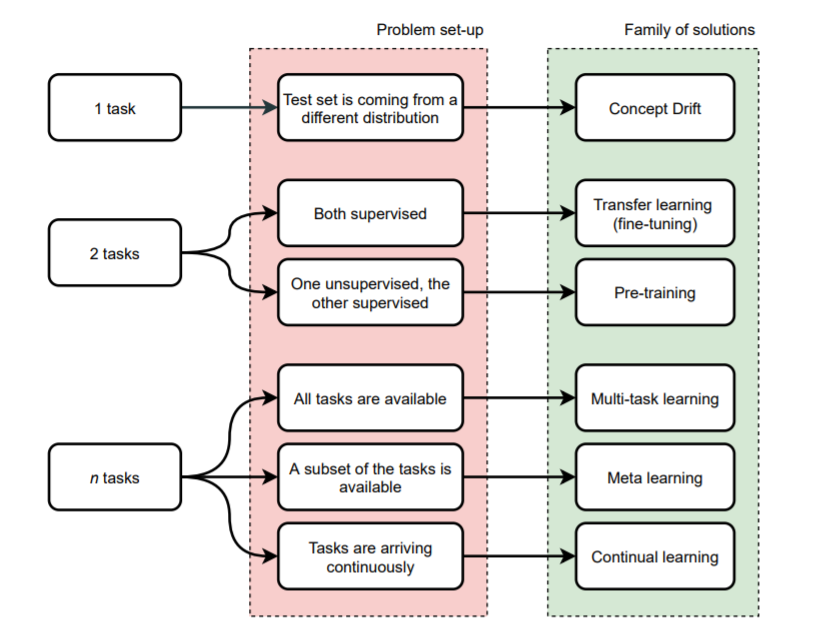
 CNNs are a great way to show how considerations about the data can guide the design of the model.
CNNs are a great way to show how considerations about the data can guide the design of the model.
 Thanks to their work, you'll find practical examples of fine-tuning parameters using @OptunaAutoML, AX (from @facebookai), @raydistributed Tune, and Auto-PyTorch and Talos coming soon.
Thanks to their work, you'll find practical examples of fine-tuning parameters using @OptunaAutoML, AX (from @facebookai), @raydistributed Tune, and Auto-PyTorch and Talos coming soon.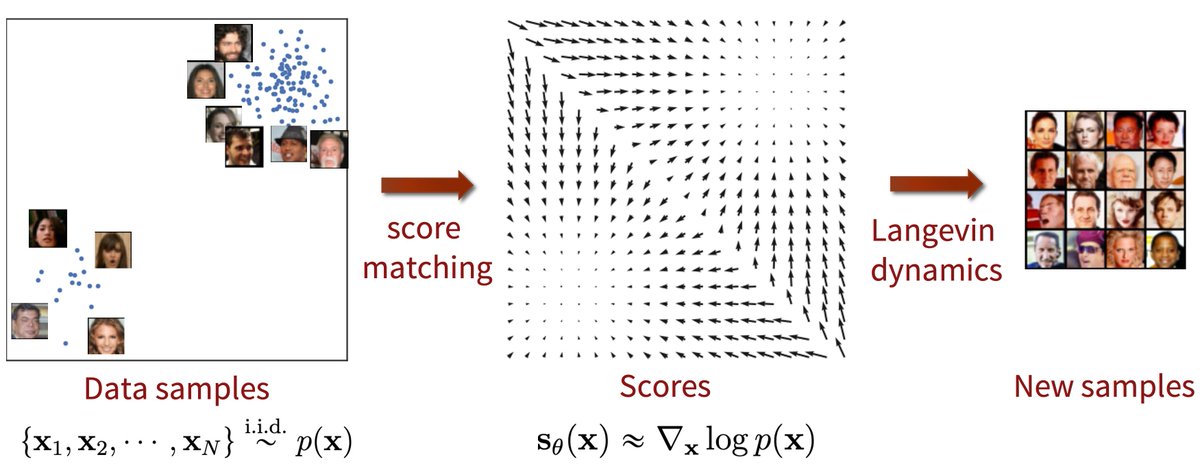 An amazing property of diffusion models is simplicity.
An amazing property of diffusion models is simplicity.
 The key idea is to use a single GD step to define auxiliary local targets for each layer, either at the level of pre- or post-activations.
The key idea is to use a single GD step to define auxiliary local targets for each layer, either at the level of pre- or post-activations. 
 Reproducibility is associated to production environments and MLOps, but it is a major concern today also in the research community.
Reproducibility is associated to production environments and MLOps, but it is a major concern today also in the research community.
 The paper considers simplicial complexes, nice mathematical objects where having a certain component (e.g., a 3-way interaction in the graph) means also having all the lower level interactions (e.g., all pairwise interactions between the 3 objects). /n
The paper considers simplicial complexes, nice mathematical objects where having a certain component (e.g., a 3-way interaction in the graph) means also having all the lower level interactions (e.g., all pairwise interactions between the 3 objects). /n 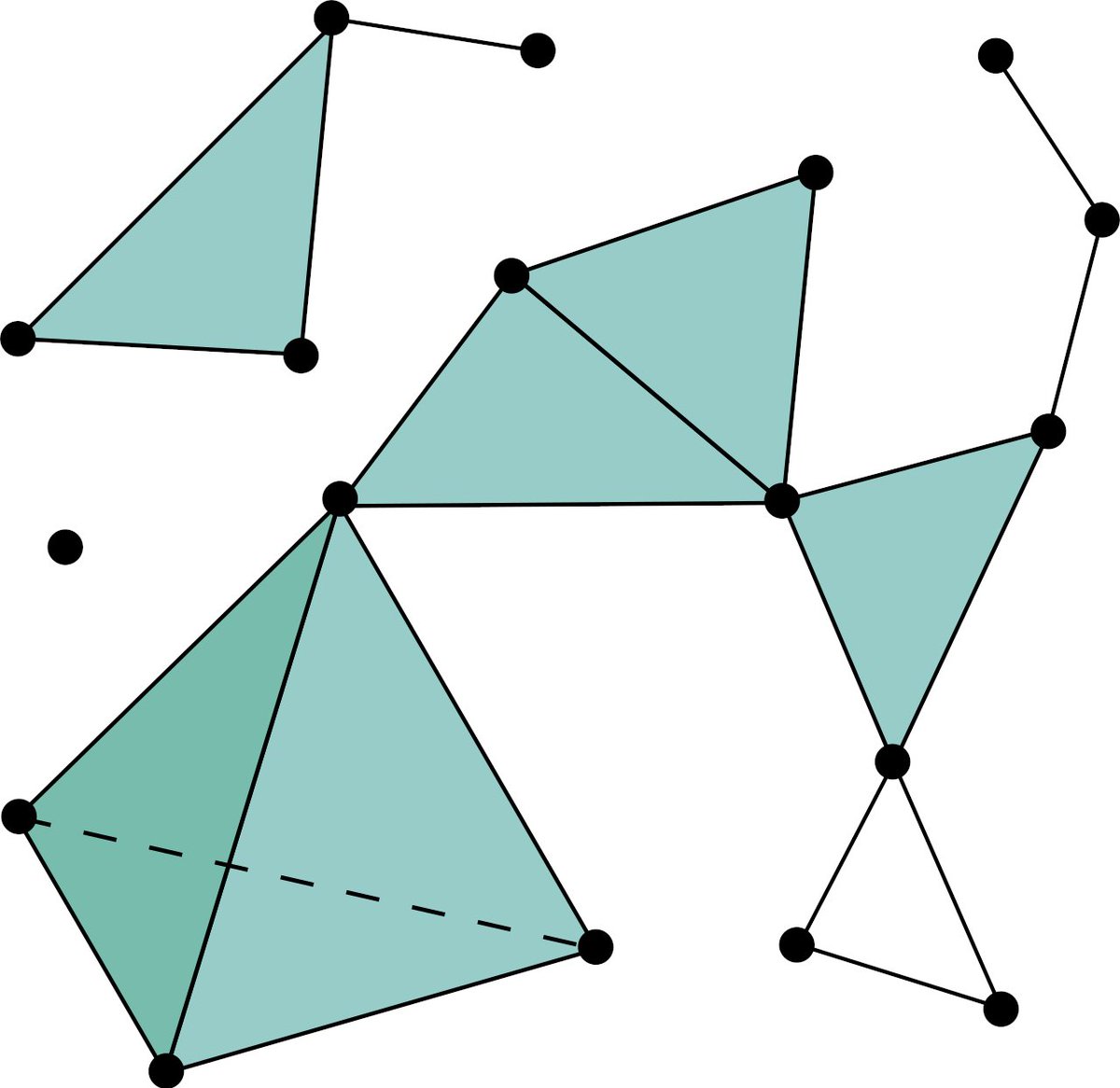
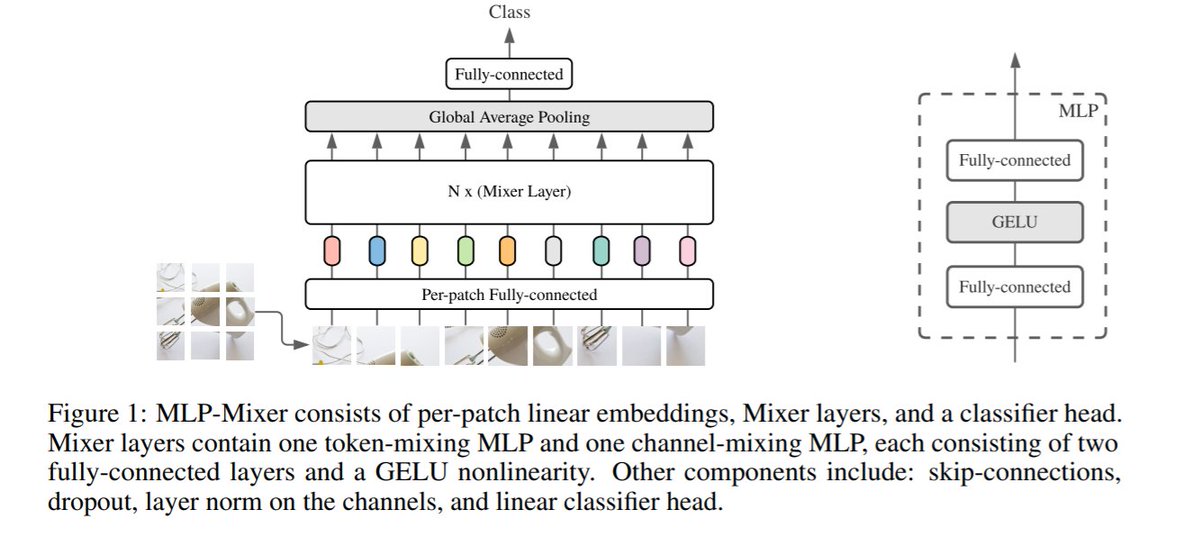 The idea is strikingly simple:
The idea is strikingly simple: