
Regresi buat data kategorik?🧐
Introduction to logistic regression
.
.
.
A thread
Introduction to logistic regression
.
.
.
A thread
Ketika kamu mau bikin model ML pake regresi tapi ternyata data kamu berbentuk kategorik, apa yang kamu lakukan?
Yep, pake regresi buat data kategorik! Loh emang bisa? Bisa dong, tapi pastinya bakal beda sama regresi linear biasa, soalnya kita bakal pake yang namanya regresi logistik. 

Jadi, regresi logistik itu analisis regresi terkhusus buat data yang punya dependen variabel berbentuk kategorik. Independent variabelnya bisa berbentuk nominal, ordinal, interval, atau ratio.
Regresi logistik ada beberapa jenis, loh. Pertama ada binary reglog, yang responnya hanya terdapat dua jenis: 0 atau 1. Misalnya, apakah suatu email itu spam (yes=1) atau engga (no=0).

Terus, ada multinomial reglog yang bisa dipake ketika responnya berupa data dengan lebih dari dua kategori tanpa urutan. Misalnya, ketika mau prediksi celana apa yang paling diminati remaja: jeans, kulot, atau jogger?
Terakhir, ada ordinal reglog. Nah, regresi logistik yang satu ini sama dengan multinomial reglog, tapi kategorinya punya urutan. Misalnya movie rating, bisa dari 1 sampai 5.

Yuk sekarang kita ngomongin regresi logistik jenis pertama: reglog binary! Kita langsung ke case study aja biar lebih enak, ya.

Misal kita punya data tentang apakah seorang siswa lulus ujian atau engga berdasarkan banyaknya waktu buat tidur sama belajar. Dependent variabelnya (passed) itu berbentuk dikotomus: pake reglog!

Terus kalo data ini kita gambarkan jadi plot dengan studied dan slept sebagai sumbunya dan passed kita bedakan dengan perbedaan warna, jadinya bakal seperti ini:
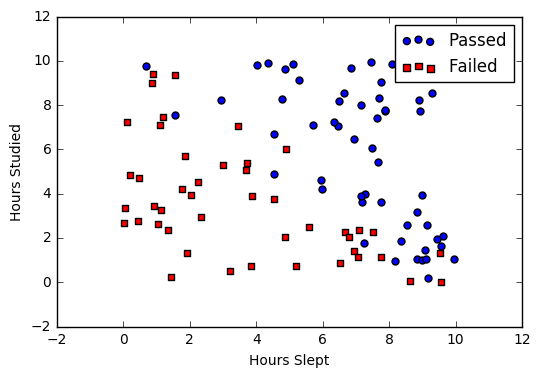
Pertama, kita bakal pake fungsi logistic yang fungsinya buat menyamakan nilai Y pada fungsi linear dengan Y pada fungsi sigmoid. Fungsinya apa? Biar data kita ketransform dalam bentuk fungsi sigmoid.

Nah, kayaknya kita mulai dulu dari fungsi regresi linear, deh. Misal kita notasiin dependen variabelnya itu z, dengan independent variabelnya w, jadi kita punya persamaan ini:

Terus, kita bakal transformasi modelnya jadi fungsi sigmoid biar probabilitasnya ada di antara 0 dan 1, kira kira begini caranya:


Nah kita bakal mapping nilai prediksi ke probabilitasnya, jadi perlu pake fungsi sigmoid buat mapping nilai yang tadi ke value antara 0 dan 1. Hasilnya jadi grafik sigmoid ini:

Nah, sigmoid tadi kan masih berupa nilai probabilitas antara 0 dan 1, jadi kita masih harus mapping datanya jadi kelas diskrit: lulus atau ga lulus ujian. Jadi, kita bakal tentuin batas probabilitas buat masuk ke kelas diskrit kita.
Tapi sayangnya, kita gabisa pake mean square error kayak kalo kita pake buat regresi linear, jadi kita pake cost function yang namanya cross-entropy yang bakal dibagi jadi dua: buat y=1 dan y=0

Kenapa kita pake ini? Karena fungsi dari cross entropy punya bentuk yang monoton atau selalu turun/naik, jadi bakal gampang buat ngukur gradien dan minimalin nilai costnya.

Tujuan kita di sini adalah supaya nilai costnya itu sekecil mungkin. Jadi kita bakal pake gradient descent buat minimize costnya.
erus, kita bakal klasifikasikan nilai probabilitas ini jadi 2 kelas: 1 (lulus ujian) atau 0 (ga lulus ujian). Kita bisa klasifikasin jadi begini:


Nah, kita bakal bikin prediksi pake fungsi prediksi, yang bakal nentuin nilai probabilitas dari suatu observasi adalah yes (lulus=1) atau no (tdk lulus=0). Kita bisa nulis notasinya dengan P(lulus=1).

Terus kita bakal evaluasi model. Kalo model kita bekerja, nilai cost kita seharusnya bakal menurun semakin banyak iterasi yang kita lakukan.

Ternyata, model kita bekerja karena kalo grafik ini semakin menurun semakin banyak iterasi yang kita lakukan.

Kalo disandingin langsung, jadi begini:

Jadi begitulah regresi yang bisa dilakuin buat data yang berbentuk kategorik! Masih banyak yang bisa dieksplore dari regresi logistik ini, loh! Kamu mau belajar cara ngolah data kategorik lebih lanjut?
Bisa banget nih belajar dan langsung praktek di non degree program nya Data Scientist Pacmann.AI! Cek informasi lebih lengkap tentang kurikulumya di bit.ly/PacmannioTwitt…. Yuk daftar, mumpung masih ada potongan diskon 20% loh!

• • •
Missing some Tweet in this thread? You can try to
force a refresh












