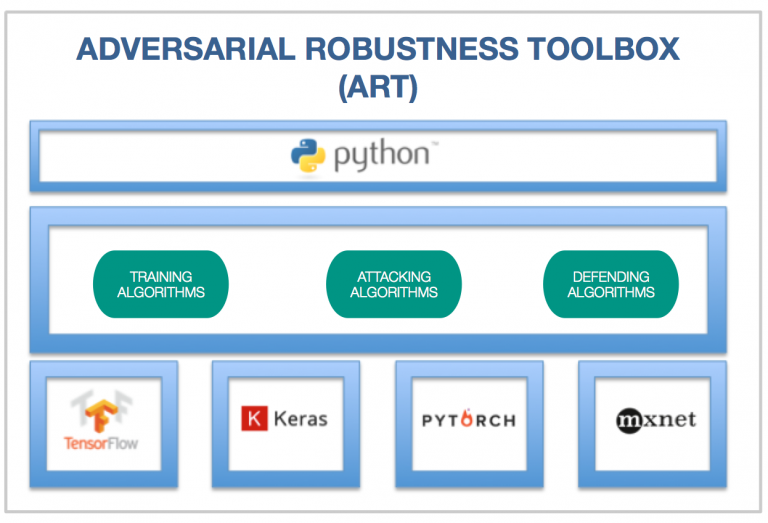
The Adversarial Robustness Toolbox (ART) = framework that uses generative adversarial neural networks (GANs) to protect deep learning models from security attacks
Thread⬇️
Thread⬇️

GANs = the most popular form of generative models.
GAN-based attacks:
+White Box Attacks: The adversary has access to the training environment, knowledge of the training algorithm
+Black Box Attacks: The adversary has no additional knowledge
2/⬇️
GAN-based attacks:
+White Box Attacks: The adversary has access to the training environment, knowledge of the training algorithm
+Black Box Attacks: The adversary has no additional knowledge
2/⬇️

The goal of ART = to provide a framework to evaluate the robustness of a neural network.
The current version of ART focuses on four types of adversarial attacks:
+evasion
+inference
+extraction
+poisoning
3/⬇️
The current version of ART focuses on four types of adversarial attacks:
+evasion
+inference
+extraction
+poisoning
3/⬇️

ART is a generic Python library. It provides native integration with several deep learning frameworks such as @TensorFlow, @PyTorch, #Keras, @ApacheMXNet
@IBM open-sourced ART at github.com/IBM/adversaria….
4/⬇️
@IBM open-sourced ART at github.com/IBM/adversaria….
4/⬇️
If you'd like to find a concentrated coverage of ART, click the link below. You'll move to TheSequence Edge#7, our educational newsletter.
thesequence.substack.com/p/edge7
5/5
thesequence.substack.com/p/edge7
5/5

• • •
Missing some Tweet in this thread? You can try to
force a refresh