
On X we surface the AI research that matters and explain the ideas behind it. In the newsletter, we connect the dots between AI’s past, present, and future ⬇️
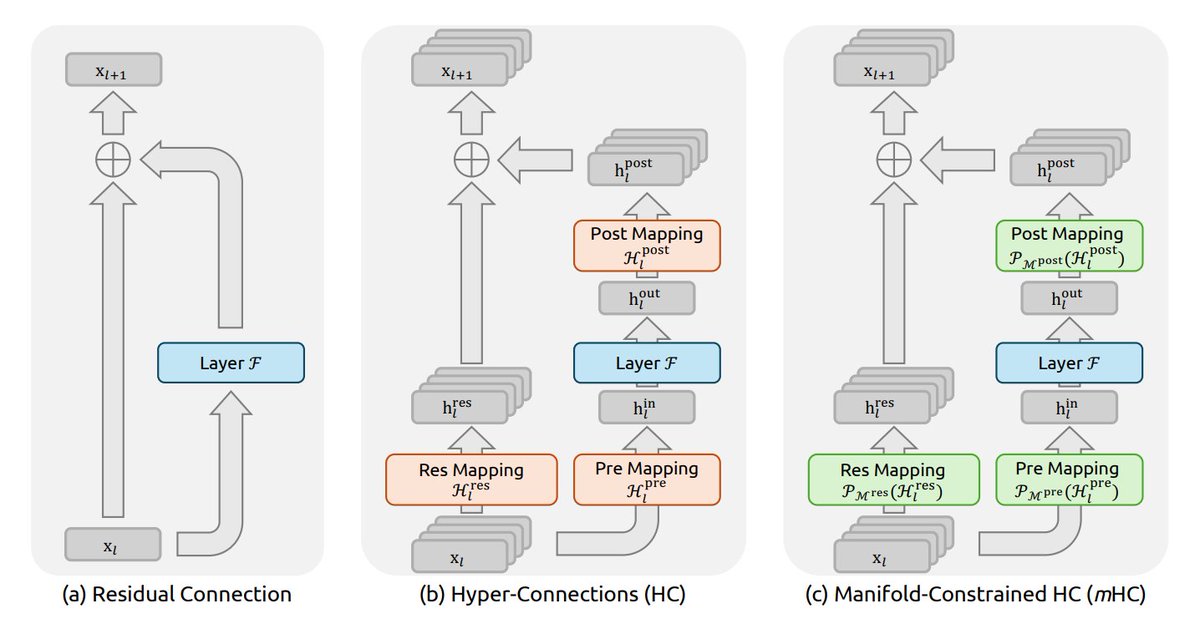 1. Residual connections have been around since ResNets and are still a big reason why Transformers and LLMs train as well as they do. They let information flow through the network unchanged, keeping deep models stable.
1. Residual connections have been around since ResNets and are still a big reason why Transformers and LLMs train as well as they do. They let information flow through the network unchanged, keeping deep models stable.
 Transformers traditionally dominate because they scale well, but they become slow and expensive for long sequences since attention grows quadratically.
Transformers traditionally dominate because they scale well, but they become slow and expensive for long sequences since attention grows quadratically. What's the problem with common methods?
What's the problem with common methods? 1. QeRL builds two RL algorithms for LLMs:
1. QeRL builds two RL algorithms for LLMs:
 1. TRM is built on the idea of the Hierarchical Reasoning Model (HRM).
1. TRM is built on the idea of the Hierarchical Reasoning Model (HRM). RoT works by:
RoT works by: 1. Intern-s1: A scientific multimodal foundation model by Shanghai AI Lab (open-source)
1. Intern-s1: A scientific multimodal foundation model by Shanghai AI Lab (open-source)
 1. Sotopia-RL: Reward Design for Social Intelligence
1. Sotopia-RL: Reward Design for Social Intelligence

 1. Workflow of SingLoRA:
1. Workflow of SingLoRA:


 1. OctoThinker
1. OctoThinker
 1. Aider @aider_chat
1. Aider @aider_chat 1. In CoE:
1. In CoE:
 1. @Google introduced Gemini 2.5 Flash and Pro as stable and production-ready, and launched Gemini 2.5 Flash-Lite in preview – the fastest and most cost-efficient.
1. @Google introduced Gemini 2.5 Flash and Pro as stable and production-ready, and launched Gemini 2.5 Flash-Lite in preview – the fastest and most cost-efficient.


 1. Institutional Books 1.0: A 242B token dataset from Harvard Library's collections, refined for accuracy and usability
1. Institutional Books 1.0: A 242B token dataset from Harvard Library's collections, refined for accuracy and usability


 1. Hugging Face insists, “Bigger isn’t better”
1. Hugging Face insists, “Bigger isn’t better”


 1. Self-Challenging Language Model Agents by @AIatMeta, @UCBerkeley
1. Self-Challenging Language Model Agents by @AIatMeta, @UCBerkeley
 1. Input:
1. Input: 1. Where is AI going these days?
1. Where is AI going these days? 1. HRPO uses reinforcement learning (RL) to train LLMs to reason internally without needing CoT training data.
1. HRPO uses reinforcement learning (RL) to train LLMs to reason internally without needing CoT training data. Architecture:
Architecture: 1. Past milestones and directions
1. Past milestones and directions