Delighted to share our work on reasoning-modulated representations! Contributed talk at @icmlconf SSL Workshop 🎉
arxiv.org/abs/2107.08881
Algo reasoning can help representation learning! See thread👇🧵
w/ Matko @thomaskipf @AlexLerchner @RaiaHadsell @rpascanu @BlundellCharles
arxiv.org/abs/2107.08881
Algo reasoning can help representation learning! See thread👇🧵
w/ Matko @thomaskipf @AlexLerchner @RaiaHadsell @rpascanu @BlundellCharles
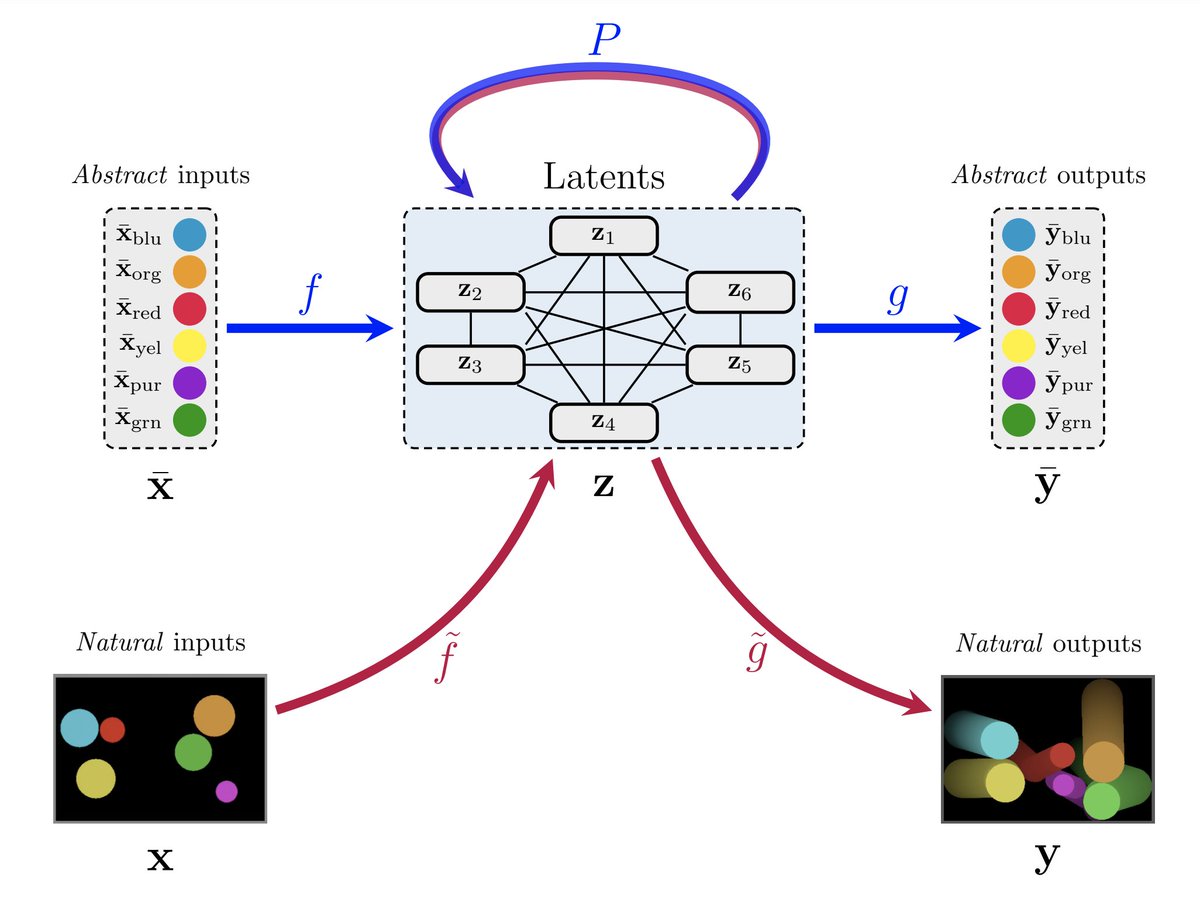
We study a very common representation learning setting where we know *something* about our task's generative process. e.g. agents must obey some laws of physics, or a video game console manipulates certain RAM slots. However...

...explicitly making use of this information is often quite tricky, every step of the way! Depending on the circumstances, it may require hard disentanglement of generative factors, a punishing bottleneck through the algorithm, or necessitate a differentiable renderer!

Algorithmic reasoning blueprint to the rescue!
In RMR, we show that we can encapsulate the x_bar -> y_bar path using a high-dimensional GNN, pre-trained on large quantities of data (which we can usually pre-generate, even synthetically).
This alleviates all of the above issues.
In RMR, we show that we can encapsulate the x_bar -> y_bar path using a high-dimensional GNN, pre-trained on large quantities of data (which we can usually pre-generate, even synthetically).
This alleviates all of the above issues.


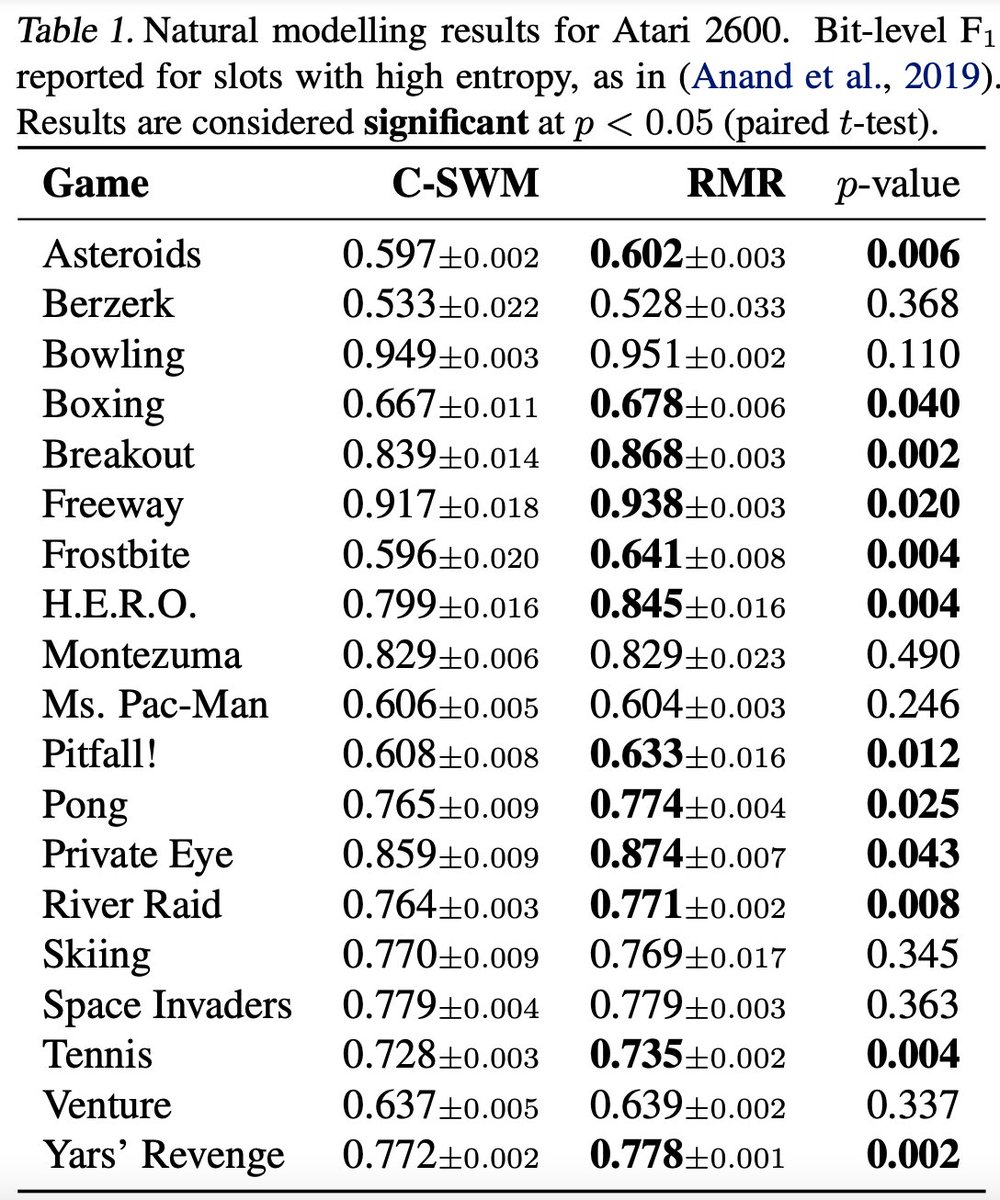
We recover significant improvements over a baseline without pre-training. N.B. RMR still needs to learn how to meaningfully use representations from a completely different task!
Our evaluation spans bouncing balls data (elastic collisions) & Atari trajectories (RAM transitions).
Our evaluation spans bouncing balls data (elastic collisions) & Atari trajectories (RAM transitions).

Lastly, alongside other recent works like XLVIN, we believe this is only one of many exciting uses of algorithmic reasoning to come in the near future! Watch this space 🎆
Any thoughts, comments and feedback is highly welcome! :)
Any thoughts, comments and feedback is highly welcome! :)
• • •
Missing some Tweet in this thread? You can try to
force a refresh