
Data kamu ada multikolinearitas?🥴😱
Jangan panik, pakai ridge regression aja!
.
.
.
A Thread
Jangan panik, pakai ridge regression aja!
.
.
.
A Thread
Halo guys! Masih inget bahasan multikolinearitas kita kemarin? Mimin udah janji nih mau bahas cara mengatasi multikolinearitas! Siapa yang tahu kenapa perlu mengatasi multikolinearitas?
Mimin ulas sedikit, ya. Jadi, ketika mau menggunakan regresi linear tetapi ternyata terdapat korelasi yang tinggi antar variabel independennya, itu artinya ada multikolinearitas.
Coba lihat gambar ini. Disini, x1 dan x2 gapunya bagian yang sama, artinya mereka independen satu sama lain. 

Tapi kalau di gambar yang ini, hal kebalikannya terjadi. Ternyata ada bagian dari x1 dan x2 yang menyatu. Nah artinya salah satu asumsi regresi linear terkait independensi data antar variabel independen gak terpenuhi, nih.

Lalu, dampaknya apa sih kalau masalah multikolinearitas ini ga terselesaikan?
Jadi gini guys, Kalau terjadi multikolinearitas, maka OLS yang tadinya kita pake di linear regression emang bakal jadi unbiased, tapi variansnya bakal jadi besar. Ini bisa bikin koefisien regresi kita jauh dari nilai sebenarnya.
Kalau begitu, kita harus mengecilkan variansnya kan agar koefisien regresi kita ga melenceng jauh dari yang sebenarnya. Tapi ternyata masalahnya ga selesai disini guys :((
Masih ingat obrolan kita tentang bias dan variance trade-off? Ketika kita mengecilkan bias, maka variansnya akan membesar, begitu pula sebaliknya. Nah, jadi tujuan utama kita di sini adalah mengecilkan varians
Kenapa kita perlu mengecilkan nilai varians? Karena varians yang besar akan membuat model kita jadi overfit dengan data trainingnya dan sulit untuk prediksi data baru

Kita bakal menurunkan varians supaya nantinya, model regresi kita bisa mencapai nilai yang optimal, yaitu tidak terlalu kompleks (jadi overfit) maupun terlalu simpel (underfit) dan bisa menghasilkan koefisien regresi terbaik.

Masih inget bentukan linear regression? Yep, kita punya dependen variabel yaitu y, independen variabel yaitu x, koefisien regresi untuk tiap x yaitu beta_i, dan error term
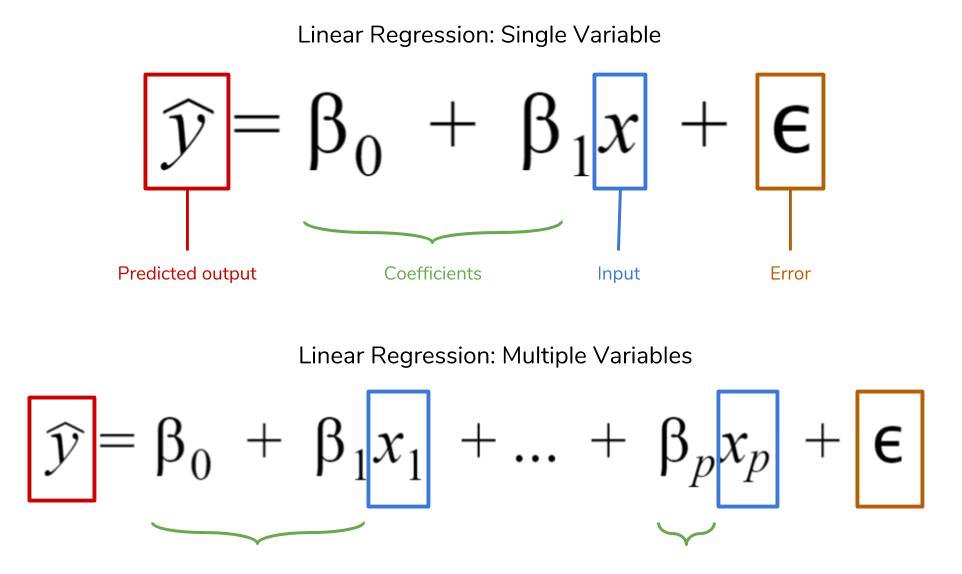
Nah, masih inget bahasan linear regression kita? Jadi kita punya cost function dan tujuan kita adalah untuk meminimalisir nilai dari cost function itu.

Cost function itu mengukur performa model dengan melihat error antara predicted value dan expected value dengan sebuah real number

Biasanya, kita minimize cost function dengan menambah fitur di dalam dataset kita. Masalahnya, semakin banyak fitur, semakin rendah cost functionnya, tapi model kita semakin berpeluang untuk overfit.
Nah, di sini deh fungsi dari ridge regression ini. Ridge regression meminimalisir cost function tanpa meningkatkan peluang model buat overfitting dataset kita.
Lalu, gimana caranya?
Lalu, gimana caranya?
Pertama, kita perlu standarisasi data dulu supaya rentang koefisien regresi dari suatu variabel ga berbeda jauh dari variabel lainnya kayak gini. Kenapa begitu?

Soalnya, kalo salah satu variabel punya nilai dengan rentang yang jauh lebih besar daripada variabel lainnya, nanti interpretasi regresinya akan cenderung memperlihatkan bahwa variabel itu punya efek yang besar terhadap output.
Nah, salah satu pendekatan biar model regresi ini stabil adalah dengan ngubah cost functionnya dengan nambahin cost baru buat variabel yang koefisiennya besar. Cara ini bakal menghasilkan penalized linear regression.

Ini namanya L2 Regularization. Emang apa yang ditambahin? Selain cost function yang ngukur fit model, kita nambahin lagi buat liat magnitude dari koefisiennya. Jadi gini, nih cost functionnya,

Yep! Penambahannya ada di lambda dan sum of square dari error termnya (SSE). Jadi, lambda di atas itu adalah si penaltinya
Kalo ada koefisien yang besar, metode ini bakal nurunin nilai estimasinya menuju 0 dengan membesarkan nilai lambda itu. Nah, metode ini biasanya dikenal dengan nama “shrinkage methods”
Nilai dari lambda, si hyperparameter dari ridge ini, ga secara otomatis ada dari model. Tapi, kita harus nentuin nilai lambda yang paling optimal secara manual. Caranya? Pake grid search!

Oke sekarang kita lihat sedikit ya contoh sederhana penggunaan ridge regression. Kita bakal bikin regresi untuk housing dataset.

Coba yuk kita lihat datanya. Kita bisa lihat ada perbedaan range antar variabelnya nih. Di data ke-4, terlihat rangenya jauh dari data no 9 dan 11.

Untuk ridge regression sendiri sudah tersedia kok, di librari scikit-learn. Tapi di sini, si lambda tadi diubah namanya jadi alpha. Nah, kalau kita ngelakuin full penalized, kita bisa pake alpha=1

Tapi apakah nilai itu bakal menghasilkan koefisien regresi yang optimal? Jelas belum tentu. Makanya, kita bisa pake grid search.

Hasilnya, kita bisa lihat kalau nilai alpha yang optimal adalah 0.51

Gitu deh, kira-kira tentang ridge regression ini! Selain ridge regression, masih ada satu lagi loh cara regularization, yaitu lasso regression dengan menggunakan L1 regularization.
Kalian juga bisa belajar per regresian ini di kelas ekonometrika Non Degree Program Data Scientist Pacmann loh! Pluss, kalian bisa nanya-nanya juga di luar jam kelas melalui discord bersama para lecturer.
Yuk kepoiin fasilitas lainnya di bit.ly/PacamannioTwit…!🤩🙌
Yuk kepoiin fasilitas lainnya di bit.ly/PacamannioTwit…!🤩🙌
• • •
Missing some Tweet in this thread? You can try to
force a refresh












