A short thread introducing new work with @PinchOfData and @phinifa:
“Text Semantics Capture Political and Economic Narratives”
Paper: arxiv.org/abs/2108.01720
Repo: github.com/relatio-nlp/re…
Demo: colab.research.google.com/drive/1Zychi2O…
“Text Semantics Capture Political and Economic Narratives”
Paper: arxiv.org/abs/2108.01720
Repo: github.com/relatio-nlp/re…
Demo: colab.research.google.com/drive/1Zychi2O…

Human beings are storytellers.
It’s no wonder then that social scientists are increasingly interested in narratives -- the stories we tell in fiction, politics, and life -- and how they shape beliefs, behavior, and government policies.
e.g. @RobertJShiller
It’s no wonder then that social scientists are increasingly interested in narratives -- the stories we tell in fiction, politics, and life -- and how they shape beliefs, behavior, and government policies.
e.g. @RobertJShiller

Narratives are obscure to social scientists because they consist of information, so the physical manifestations are spoken or written language.
More specifically, a narrative is an “account of a series of events, facts, etc., given in order and with the establishing of connections between them” (@OED).
Yet existing text-as-data approaches do not account for "who" does "what" to "whom".
Yet existing text-as-data approaches do not account for "who" does "what" to "whom".

We provide an approach for extracting narratives from text.
First, we use semantic role labeling (@ai2_allennlp) to extract the semantic roles of agent, verb, and patient. The agent is the entity that performs an action, while the patient is the entity acted upon.
First, we use semantic role labeling (@ai2_allennlp) to extract the semantic roles of agent, verb, and patient. The agent is the entity that performs an action, while the patient is the entity acted upon.

The set of agents and patients is high-dimensional (typically millions of plain-text phrases).
We use named entity recognition (@spacy_io) to identify specific individuals and organizations. The remaining phrases are embedded (@gensim_py) and then clustered (@scikit_learn).
We use named entity recognition (@spacy_io) to identify specific individuals and organizations. The remaining phrases are embedded (@gensim_py) and then clustered (@scikit_learn).

The resulting unsupervised pipeline takes in a plain-text corpus and outputs interpretable narratives representing the core claims.
In the paper, we construct narratives from floor speeches in U.S. Congress.
In the paper, we construct narratives from floor speeches in U.S. Congress.


Some narratives are simple (e.g. “immigrants steal jobs”), but others are complex and interconnected.
We use a graph-based approach to build networks of connected entities, representing the larger narrative structures — or worldviews — expressed in a corpus.
We use a graph-based approach to build networks of connected entities, representing the larger narrative structures — or worldviews — expressed in a corpus.


Check out this interactive worldview graph constructed from Trump’s tweet archive: sites.google.com/view/trump-nar…
#networkx #pyvis
#networkx #pyvis
The pipeline has a lot going on under the hood. We provide a python package ʀᴇʟᴀᴛɪᴏ that makes it easy to use.
Repo: github.com/relatio-nlp/re…
Demo Notebook: colab.research.google.com/drive/1Zychi2O…
Special thanks to @AndreiPlamada and @ETH_SIS for indispensable contributions to the package!
Repo: github.com/relatio-nlp/re…
Demo Notebook: colab.research.google.com/drive/1Zychi2O…
Special thanks to @AndreiPlamada and @ETH_SIS for indispensable contributions to the package!

In the paper, we apply the method to over a million speeches given in U.S. Congress for the period 1994-2015. We show dynamics, sentiment, and partisanship in the narratives.

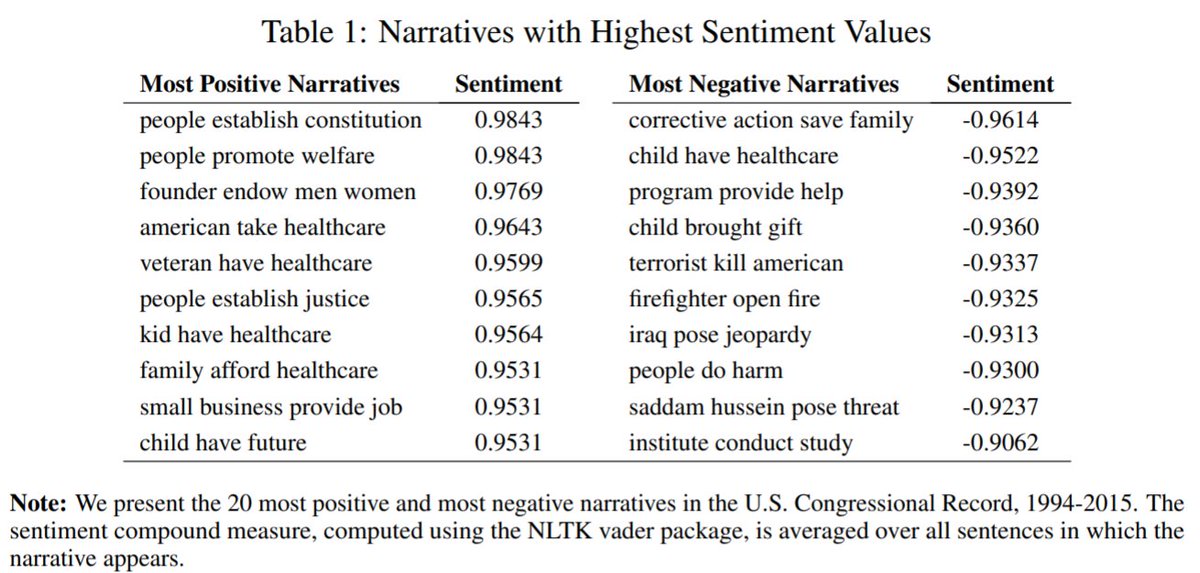


In particular, we show the most divisive policy narratives.
For example, “Oil”: Democrats say “oil makes profit” while Republicans say “oil creates jobs”.
Or “Jobs”: Democrats say “companies ship jobs” while Republicans say “taxes kill jobs”.
For example, “Oil”: Democrats say “oil makes profit” while Republicans say “oil creates jobs”.
Or “Jobs”: Democrats say “companies ship jobs” while Republicans say “taxes kill jobs”.

Section 4 discusses the potential and limitations of the approach. One thing we are excited about is how ʀᴇʟᴀᴛɪᴏ could be used to support qualitative analysis of narratives, not just in social science but also in history and the humanities.
Feedback welcome!
Feedback welcome!
A special shout-out to teammates @phinifa and @PinchOfData, talented upcoming economists, grand co-authors, and a delight to work with.
The project originated at #SICSS Zurich 2019!
@msalganik @chris_bail
And thanks to @snsf_ch for Spark funding.
The project originated at #SICSS Zurich 2019!
@msalganik @chris_bail
And thanks to @snsf_ch for Spark funding.
cc @jurafsky @nlpnoah @KamiarMohaddes @dbamman @Noahpinion @rodrikdani @mollyeroberts @justingrimmer @b_m_stewart @MattGrossmann
• • •
Missing some Tweet in this thread? You can try to
force a refresh