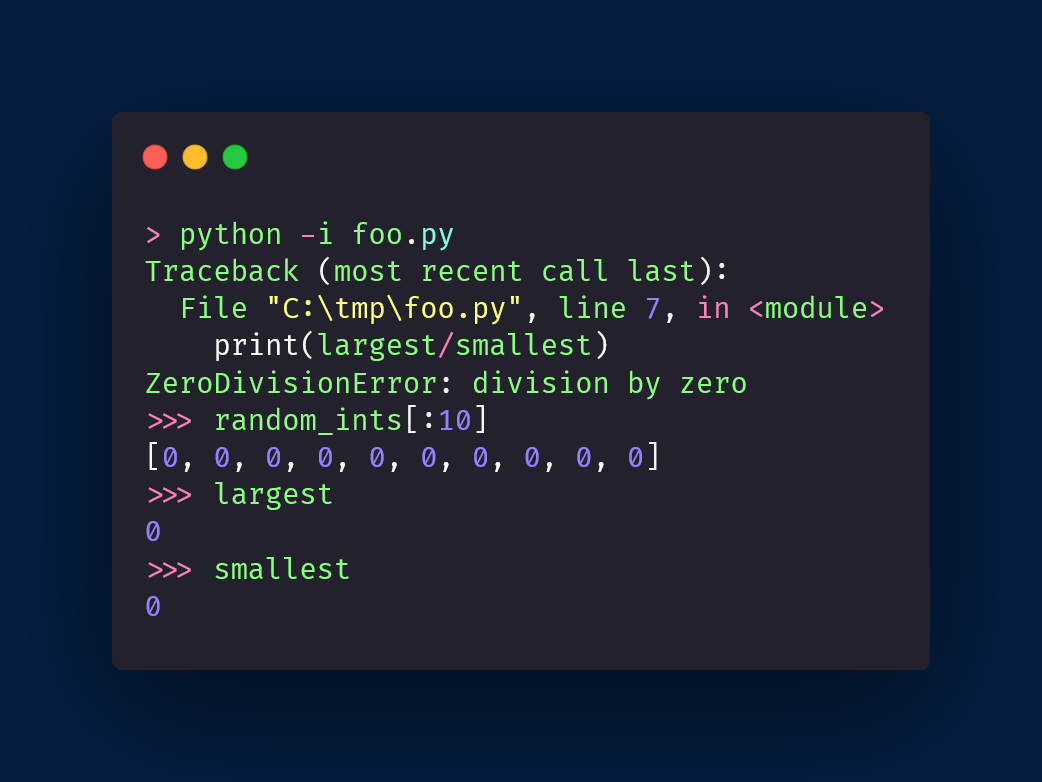
🥇 I challenged you to write a Python 🐍 function `is_pangram`, that checks if a string contains all 26 letters of the English alphabet.
(Original challenge linked below 👇)
I got many amazing suggestions.
Here is a thread 🧵 about different solutions.
(Original challenge linked below 👇)
I got many amazing suggestions.
Here is a thread 🧵 about different solutions.
https://twitter.com/mathsppblog/status/1431980960858480651
Overall, people tended to follow one of 3 approaches:
1. remove irrelevant chars and see if there are 26 letters left (duplicates excluded);
2. check if each letter of the alphabet appears in the string; and
3. check if the alphabet is fully contained inside the input string.
1. remove irrelevant chars and see if there are 26 letters left (duplicates excluded);
2. check if each letter of the alphabet appears in the string; and
3. check if the alphabet is fully contained inside the input string.
Then, I saw two major trends in the solutions people shared, regardless of strategy.
Either they did all the work by hand with a `for` loop or they leveraged tools like Python's `set`.
Here's the archetype for a `for` based solution:
Either they did all the work by hand with a `for` loop or they leveraged tools like Python's `set`.
Here's the archetype for a `for` based solution:

Notice the usage of the `string.ascii_lowercase` built-in that contains the lower case latin alphabet.
This is a built-in, so make use of it!
Might look silly, but you won't believe the amount of incorrect alphabets found on GitHub 🤦♂️🤦♀️
This is a built-in, so make use of it!
Might look silly, but you won't believe the amount of incorrect alphabets found on GitHub 🤦♂️🤦♀️
https://twitter.com/mathsppblog/status/1422181145186377730
Personally, I am not very fond of the “removing what doesn't matter and checking if there's 26 letters left” strategy.
But WHY?
It is very error prone! If you forget to exclude one single type of character, then your solution 💥💥
But if you really wanna go down that road...
But WHY?
It is very error prone! If you forget to exclude one single type of character, then your solution 💥💥
But if you really wanna go down that road...
Then you can do something like the solution below 👇
However, this solution will be hard(er) to patch up if you want to take into account accented letters like ãéô, arbitrary Unicode characters, etc.
However, this solution will be hard(er) to patch up if you want to take into account accented letters like ãéô, arbitrary Unicode characters, etc.

Now, there's a slight semantic difference, but instead of "removing what doesn't matter" you can choose to "keep what matters" with a set comprehension!
With this shift in mindset we can use something like `str.isalpha` to only keep "letter" characters:
With this shift in mindset we can use something like `str.isalpha` to only keep "letter" characters:

Another good archetype of solution is to go through the letters that we want to find and see if they are inside the input string or not.
This solution is easy to understand and IMO superior to the raw `for` loop because it makes idiomatic use of the `all` built-in...
This solution is easy to understand and IMO superior to the raw `for` loop because it makes idiomatic use of the `all` built-in...

But this solution is not optimal!
If you have a really long string and the letters of the alphabet are towards the end of the input, then the usage of `in` will do a lot of work...
Think about strings starting with
`"_" * 1_000_000`,
you have to skip a million irrelevant "_".
If you have a really long string and the letters of the alphabet are towards the end of the input, then the usage of `in` will do a lot of work...
Think about strings starting with
`"_" * 1_000_000`,
you have to skip a million irrelevant "_".
So it really is helpful if we only traverse the input string once, so let's stick to solutions using sets.
There are many ways to phrase the solution using many equivalent formulations using set operations.
Here is an example:
There are many ways to phrase the solution using many equivalent formulations using set operations.
Here is an example:

However, my favourite solution, the one that I find most elegant, just checks if the set of lowercase letters is a subset of the set of all characters of the string!
This entails minimal preparation, it's just a single check:
This entails minimal preparation, it's just a single check:

The <= inequality is akin to the ⊆ in mathematical notation; if A and B are Python sets,
A <= B
checks if A is a subset of B.
This is the same as A.issubset(B).
You can read up on set operations here: docs.python.org/3/library/stdt…
A <= B
checks if A is a subset of B.
This is the same as A.issubset(B).
You can read up on set operations here: docs.python.org/3/library/stdt…
This type of solution also makes it very easy to make our solution much more robust, e.g. handling accents in letters.
For example, let's say that the following should also be a pangram:
àbçdêfghíjklmñõpqrstüvwxyz
Using `unicodedata.normalize` we can handle that!
For example, let's say that the following should also be a pangram:
àbçdêfghíjklmñõpqrstüvwxyz
Using `unicodedata.normalize` we can handle that!

I can't guarantee that the normalisation step above is the ABSOLUTE BEST, especially because I'm not a master of Unicode, but you can read always read the docs.
The normalisation above splits letters and accents:
àêíñõü → a`e^i´n~o~u¨
🔗 docs.python.org/3/library/unic…
The normalisation above splits letters and accents:
àêíñõü → a`e^i´n~o~u¨
🔗 docs.python.org/3/library/unic…
Finally, I'd just like to thank explicitly everyone that contributed to the discussion in the original challenge, submit solutions, etc.
If you like this type of educational content, retweet the beginning of the thread and follow me (@mathsppblog) for more 😉
If you like this type of educational content, retweet the beginning of the thread and follow me (@mathsppblog) for more 😉
In no particular order, credit goes to:
@willmcgugan @althonos @Searge @techaralambous @hugovk @DahlitzF @villares @nikhilkokkula25 @interstar @thp4 @neex_io @kishumds @heyDecency @BPrvn_Rj @andre_roberge
I hope I didn't miss anyone 😢
@willmcgugan @althonos @Searge @techaralambous @hugovk @DahlitzF @villares @nikhilkokkula25 @interstar @thp4 @neex_io @kishumds @heyDecency @BPrvn_Rj @andre_roberge
I hope I didn't miss anyone 😢
P.S. in hindsight, the normalisation call should have been first and only THEN I should've changed the casing of the string to lower case.
• • •
Missing some Tweet in this thread? You can try to
force a refresh