
tl;dr: Our findings call for a change in how we evaluate performance on deep RL benchmarks, for which we present more reliable protocols, easily applicable with *even a handful of runs*, to prevent unreliable results from stagnating the field.
arxiv.org/abs/2108.13264 (1/N)
arxiv.org/abs/2108.13264 (1/N)

Most published results on deep RL benchmarks compare point estimates of aggregate performance such as mean and median scores across tasks, ignoring the statistical uncertainty implied by the use of a finite number of training runs. (2/N)

Beginning with the Arcade Learning Environment (ALE), the shift towards computationally-demanding benchmarks has led to the practice of evaluating only a handful of runs per task, exacerbating the statistical uncertainty in point estimates. (3/N)

Using a case study on Atari 100k, we show that commonly reported point estimates of median scores:
(1) exhibit high variability,
(2) are substantially biased,
(2) require 30-50 runs to claim improvement for certain comparisons, infeasible for most research projects! (4/N)
(1) exhibit high variability,
(2) are substantially biased,
(2) require 30-50 runs to claim improvement for certain comparisons, infeasible for most research projects! (4/N)


We also comment on the incompatibility of alternative evaluation protocols involving maximum across runs or during training to end-performance results. On Atari 100k, we find that the two protocols produce substantially different results. (5/N)

So, how do we reliably evaluate performance? We argue that just fixing random seeds is not a solution. Similarly, evaluating more than a few runs is typically infeasible for computationally demanding deep RL benchmarks. (6/N)


Instead of dichotomous statistical significance tests, we emphasize using statistical thinking. As such, performance estimate based on a finite number of runs is a random variable and should be treated as such. (7/N)

Following [1, 2], we recommend using confidence intervals for measuring the uncertainty in results and showing performance improvements over baseline that are compatible with the given data. (8/N)
[1] nature.com/articles/d4158…
[2]tandfonline.com/doi/full/10.10…
[1] nature.com/articles/d4158…
[2]tandfonline.com/doi/full/10.10…
Our proposals are summarized in the table below. We'll walk through them one by one. (9/N)
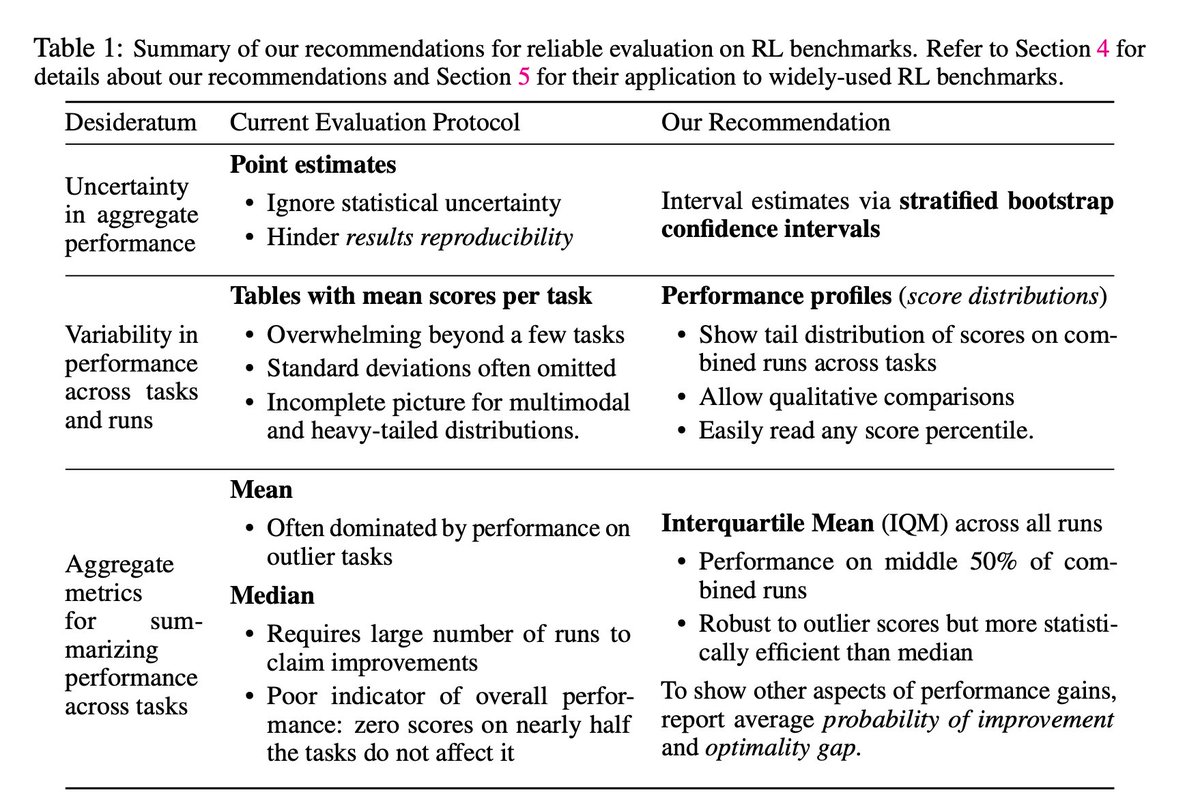
The key trick is with N runs per task on each of M tasks, we have a total of NM random samples. Bootstrapping seems to work well in this scenario for providing reasonably accurate interval estimates. We define interquartile mean (IQM) and optimality gap across runs below. (10/N)

Aggregate metrics conceal variability in performance across runs and tasks, we instead recommend reporting performance profiles. (11/N)
Performance profiles are typically used for comparing solve times of different optimization methods and are robust to outlier runs/tasks. Our profiles correspond to empirical tail distribution function with confidence
bands based on stratified bootstrap. (12/N)
bands based on stratified bootstrap. (12/N)

However, perf profiles often intersect and we need aggregate metrics for quantitative comparisons. Existing metrics are deficient: mean is prone to outliers while median is unaffected by 0 scores on nearly half of the tasks and is statistically inefficient. Our proposals:

*IQM* corresponds to mean score of the middle 50% of the *runs* combined across all tasks. Compared to mean, it is robust to outliers. Compared to median, is a better indicator of overall performance and results in smaller CIs and require fewer runs to claim improvements. (14/N)

On DM Control, there are huge overlaps in 95% CIs of mean normalized scores for most algorithms. These findings suggest that a lot of the reported improvements could be spurious, resulting from randomness in the experimental protocol. (15/N)

Another metric we propose is *probability of improvement* averaged across all tasks -- this answers how likely the improvement over baseline is irrespective of its size! Applying this on Procgen, we find that some of the claimed improvements are only 50-70% likely. (15/N)

To support reliable evaluation in RL research, we have released an easy-to-use Python library, along with a Colab. See arxiv.org/abs/2108.13264 for more results and findings!
Colab: bit.ly/statistical_pr…
Library: github.com/google-researc…
Individual runs: console.cloud.google.com/storage/browse…
Colab: bit.ly/statistical_pr…
Library: github.com/google-researc…
Individual runs: console.cloud.google.com/storage/browse…
• • •
Missing some Tweet in this thread? You can try to
force a refresh


