
@amaarora really explained #convolutions very well in #fastbook week 12 session which can be viewed here
I wasn't able to write a blog post explaining my learnings from the stream but would threfore write a 🧵
I wasn't able to write a blog post explaining my learnings from the stream but would threfore write a 🧵
2/n
After going through 1st part of #convolutions chapter, have cleared a concept and was introduced to two new concepts.
1. How depthwise convolutions work (3/n)
2. Dilated convolutions (7/n)
3. Alternate interpretation of #stride (9/n)
After going through 1st part of #convolutions chapter, have cleared a concept and was introduced to two new concepts.
1. How depthwise convolutions work (3/n)
2. Dilated convolutions (7/n)
3. Alternate interpretation of #stride (9/n)
3/n
When we have a n-channel input and a m-channel output, we need to convolve over not only 2-Dimensions (W x H) but also across the depth D.
An RGB image for example has 3 channels
Let us consider we want to derive 10 feature maps from this input.
When we have a n-channel input and a m-channel output, we need to convolve over not only 2-Dimensions (W x H) but also across the depth D.
An RGB image for example has 3 channels
Let us consider we want to derive 10 feature maps from this input.
4/n
We shall then have 10 kernels each 3-D with different activations across the depth dimension.
We can look at each kernel one at a time and we observe that it's shape is in_channels x k x k
#DL
We shall then have 10 kernels each 3-D with different activations across the depth dimension.
We can look at each kernel one at a time and we observe that it's shape is in_channels x k x k
#DL

5/n
The way it gets applied is each input channel is multiplied with a corresponding kernel channel.
Then the results of these individual computations are just plainly added and we get the final (1 x h x w) or (1 x fraction of h x fraction of w) resultant feature map.
#DL
The way it gets applied is each input channel is multiplied with a corresponding kernel channel.
Then the results of these individual computations are just plainly added and we get the final (1 x h x w) or (1 x fraction of h x fraction of w) resultant feature map.
#DL

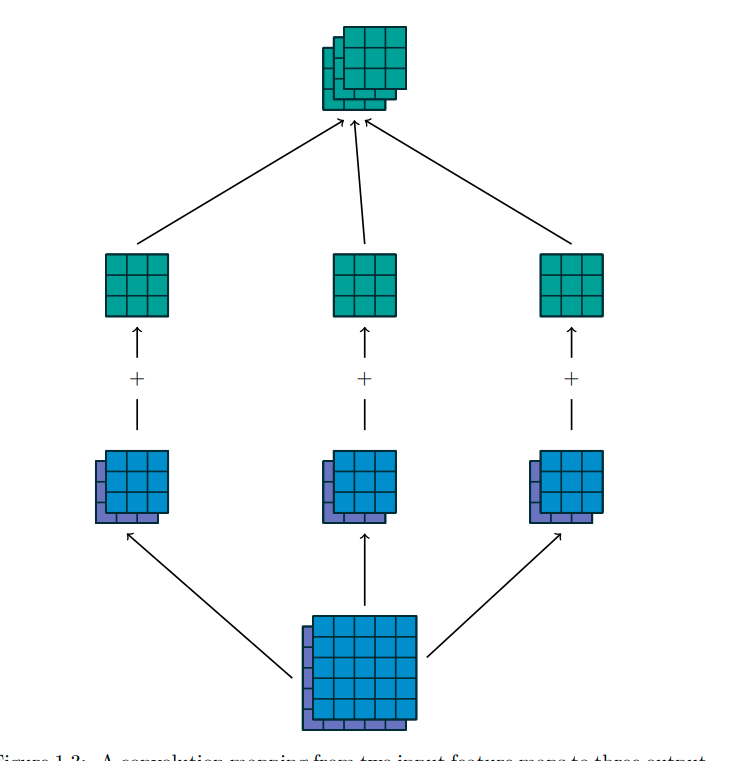
7/n
This paper also talks about dilation convolutions which is basically IMHO convolution with holes.
What this allows a neural network is increased receptivity so even the shallower layers are looking at a larger portion of the image plus we get dimensionality redx
This paper also talks about dilation convolutions which is basically IMHO convolution with holes.
What this allows a neural network is increased receptivity so even the shallower layers are looking at a larger portion of the image plus we get dimensionality redx

8/n
Which means no need of pooling or taking larger strides. This was indeed a new way of thinking about convolutions and I hope to try it out in the near future.
#CV #DL
Which means no need of pooling or taking larger strides. This was indeed a new way of thinking about convolutions and I hope to try it out in the near future.
#CV #DL
9/n
Another beautiful perspective of looking at a high stride convolution is presented in this paper.
A stride of > 1 is just applying convolution with stride 1 and only retaining some elements in the output feature map which we get.
#ComputerVision
Another beautiful perspective of looking at a high stride convolution is presented in this paper.
A stride of > 1 is just applying convolution with stride 1 and only retaining some elements in the output feature map which we get.
#ComputerVision

10/n
The above really helps understand the implications when we compare pooling vs higher stride for reducing the feature map size deeper down the network.
The above really helps understand the implications when we compare pooling vs higher stride for reducing the feature map size deeper down the network.
• • •
Missing some Tweet in this thread? You can try to
force a refresh


