
Popular deep learning architectures:
◆ Densely connected neural networks
◆ Convolutional neural networks
◆ Recurrent neural networks
◆ Transformers
Let's talk about these architectures and their suites of datasets in-depth 🧵
◆ Densely connected neural networks
◆ Convolutional neural networks
◆ Recurrent neural networks
◆ Transformers
Let's talk about these architectures and their suites of datasets in-depth 🧵
Machine learning is an experimentation science. An algorithm that was invented to process images can turn out to work well on texts too.
The next tweets are about the main neural network architectures and their suites of datasets.
The next tweets are about the main neural network architectures and their suites of datasets.
1. Densely connected neural networks
Densely connected networks are made of stacks of layers that go from the input to the output.
Generally, networks are organized into layers. Each carry takes input data, processes it, and gives the output to the next layer.
Densely connected networks are made of stacks of layers that go from the input to the output.
Generally, networks are organized into layers. Each carry takes input data, processes it, and gives the output to the next layer.

The units (or neurons) of any layer in that type of network are connected to all other units of the next layer.
That is why dense layers are also called fully connected layers.
That is why dense layers are also called fully connected layers.
Densely connected networks are generally used for tabular data. Tabular data are these kinds of data that are in a tabular fashion.
An example of tabular data is customer records: you have a column of names, roles, data joined, etc...
An example of tabular data is customer records: you have a column of names, roles, data joined, etc...
2. Convolutional Neural Networks (CNNs), a.k.a Convnets
Convnets are widely known as the go-to neural network architectures when it comes to processing images, but they can also be used in other data such as texts and time series.
Image: A typical Convnets architecture
Convnets are widely known as the go-to neural network architectures when it comes to processing images, but they can also be used in other data such as texts and time series.
Image: A typical Convnets architecture
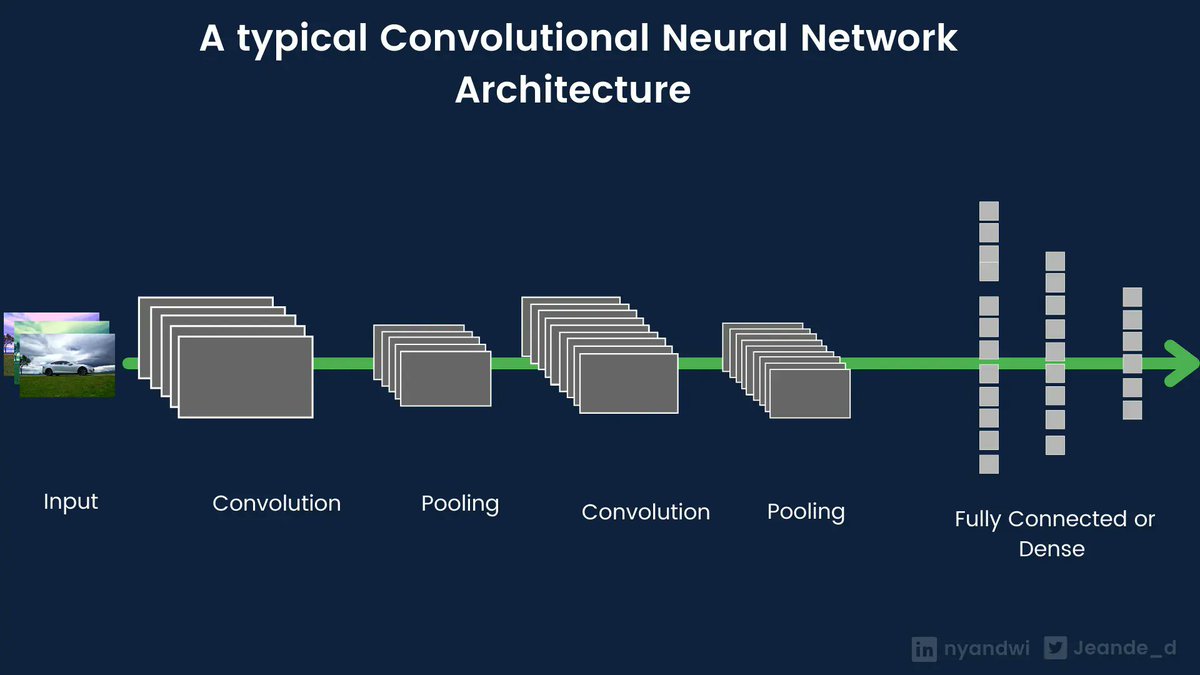
Convnets inputs are of 3 dimensions. The most popular one is Conv2D that is used in images and videos (divided into frames).
Conv1D is used in sequential data such as texts, time series, and sounds. A popular sound architecture called WaveNet is made of 10 stacked 1D Convnets.
WaveNet: deepmind.com/blog/article/w…
Conv3D is used in videos and volumetric images such as CT scans.
WaveNet: deepmind.com/blog/article/w…
Conv3D is used in videos and volumetric images such as CT scans.
3. Recurrent Neural Networks(RNNs)
The standard feedforward network maps the input to output. RNNs go beyond that. They can maintain the recurrence of data at each time step.
Image: Feed forward nets vs RNNs
The standard feedforward network maps the input to output. RNNs go beyond that. They can maintain the recurrence of data at each time step.
Image: Feed forward nets vs RNNs

Due to their ability to preserve the recurrence of information, RNNs are commonly used in sequential data such as texts and time series.
The basic RNN cells are not efficient at handling large sequences due to a short memory problem.
They also suffer from vanishing gradients.
More about vanishing gradients problem 👇
They also suffer from vanishing gradients.
More about vanishing gradients problem 👇
https://twitter.com/Jeande_d/status/1436277279697539074?s=20
The variant of RNNs that is able to handle long sequences is called Long Short Term Memory(LSTM).
LSTM has also the ability to handle the sequences of variable lengths.
Image: LSTM, source: Intro to Deep learning MIT
LSTM has also the ability to handle the sequences of variable lengths.
Image: LSTM, source: Intro to Deep learning MIT

A special design difference about the LSTM cell is that it has a gate which is the basis of why it can control the flow of information over many time steps.
In short, LSTM uses gates to control the flow of information from the current time step to the next time step in the following 4 steps:
◆The input gate recognizes the input sequence.
◆The input gate recognizes the input sequence.
◆Forget gate gets rid of all irrelevant information contained in the input sequence and store relevant information in long-term memory.
◆LTSM cell updates update cell's state values.
◆Output gate controls the information that has to be sent to the next time step.
◆LTSM cell updates update cell's state values.
◆Output gate controls the information that has to be sent to the next time step.
The ability of LSTMs to handle long-term sequences made it a suitable neural network architecture for various sequential tasks such as
◆Text classification
◆Sentiment analysis
◆Speech recognition
◆Image caption generation
◆Machine translation.
◆Text classification
◆Sentiment analysis
◆Speech recognition
◆Image caption generation
◆Machine translation.
Another recurrent neural network that you will see is Gate Recurrent Unit(GRU). GRU is a simplified version of LSTMs, and it's cheaper to train.
RNNs were one of the states of the art networks until the transformers came.
RNNs were one of the states of the art networks until the transformers came.
4. Transformers
Although RNNs are still used for sequential modeling, they have short-term memory problems when used for long sequences, and they are computationally expensive.
Although RNNs are still used for sequential modeling, they have short-term memory problems when used for long sequences, and they are computationally expensive.
The RNN's inability to handle long sequences and expensiveness are the two most motivations of transformers.
Transformers are one of the latest groundbreaking researches in the natural language community.
They are sorely based on the attention mechanisms that learn the relationships between words of the sentence and pays attention to the relevant words.
Image: Transformer
They are sorely based on the attention mechanisms that learn the relationships between words of the sentence and pays attention to the relevant words.
Image: Transformer

One of the most notable things about transformers is that they don't use any recurrent or convolutional layers.
It's just only attention mechanisms and other standard layers like embedding layer, dense layer, and normalization layers.
It's just only attention mechanisms and other standard layers like embedding layer, dense layer, and normalization layers.

They are commonly used in language tasks such as text classification, question answering, and machine translation.
There have been researches that show that they can also be used for computer vision tasks, such as image classification, object detection, image segmentation, and image captioning with visual attention.
More about transformers in vision 👇
arxiv.org/abs/2101.01169
More about transformers in vision 👇
arxiv.org/abs/2101.01169
To learn more about the transformer, check out its paper.
ATTENTION IS ALL YOU NEED!!
arxiv.org/abs/1706.03762
ATTENTION IS ALL YOU NEED!!
arxiv.org/abs/1706.03762
Since when transformers were invented, a lot of good people have tried to take it further.
An example of a state-of-the-art language model called BERT (Bidirectional Encoder Representations from Transformers) is based on transformers.
An example of a state-of-the-art language model called BERT (Bidirectional Encoder Representations from Transformers) is based on transformers.
The pre-trained BERT can be finetuned to handle most NLP (Natural language processing) tasks easily.
BERT is now powering most language apps. If you disassemble most search queries, you can probably find it there.
arxiv.org/abs/1810.04805…
BERT is now powering most language apps. If you disassemble most search queries, you can probably find it there.
arxiv.org/abs/1810.04805…
The invention of transformers also motivated @OpenAI GPT series (Generative Pretrained Transformer) such as GPT, GPT-2, and GPT-3 which is the recent one.
This is the end of the thread. The rests are summary and additional notes
We can summarize the neural networks architectures we discussed by their suites of data:
◆Tabular data: Densely connected neural networks.
◆Images: 2D Convolutional neural networks (a.k.a Convnets).
We can summarize the neural networks architectures we discussed by their suites of data:
◆Tabular data: Densely connected neural networks.
◆Images: 2D Convolutional neural networks (a.k.a Convnets).
◆Texts: Recurrent Neural Networks(RNNs), transformers, or 1D Convnets.
◆Time-series: RNNs or 1D Convnets
◆Videos and volumetric images: 3D Convnets, or 2D Convnets (with video divided into frames)
◆Sound: 1D Convnets or RNNS.
◆Time-series: RNNs or 1D Convnets
◆Videos and volumetric images: 3D Convnets, or 2D Convnets (with video divided into frames)
◆Sound: 1D Convnets or RNNS.
The machine learning research community is so vibrant.
It doesn't take long for a promised technique to fade away, or overlooked techniques to emerge unknowingly.
It doesn't take long for a promised technique to fade away, or overlooked techniques to emerge unknowingly.
Just take an example of recent research that used Multi-Layer Perceptions(MLP-Mixer: An all-MLP Architecture for Vision) for computer vision claiming that Convnets and transformers are not necessary.
MLP-Mixer: arxiv.org/abs/2105.01601
MLP-Mixer: arxiv.org/abs/2105.01601
When RNNs came, the thing was: recurrence is all you need. Then later, when transformer came, attention was all you need,
But a few days ago, another claim was made: You don't need attention, PAY ATTENTION TO MLPs (Perceptron again)
arxiv.org/abs/2105.08050
But a few days ago, another claim was made: You don't need attention, PAY ATTENTION TO MLPs (Perceptron again)
arxiv.org/abs/2105.08050
These recent claims may not necessarily work now but all that speaks to is that this field will keep evolving.
And nobody really knows what's will be relevant 10 years from now.
My hope is that you and I can keep learning!
And nobody really knows what's will be relevant 10 years from now.
My hope is that you and I can keep learning!
Thank you for reading.
You can follow @Jeande_d for more posts like this.
P.S. One of my 2021's goals was to do something tangible for the ML community.
The thing that I am working on touches the practical aspects of nearly all deep learning and shallow learning algorithms!
You can follow @Jeande_d for more posts like this.
P.S. One of my 2021's goals was to do something tangible for the ML community.
The thing that I am working on touches the practical aspects of nearly all deep learning and shallow learning algorithms!
• • •
Missing some Tweet in this thread? You can try to
force a refresh



