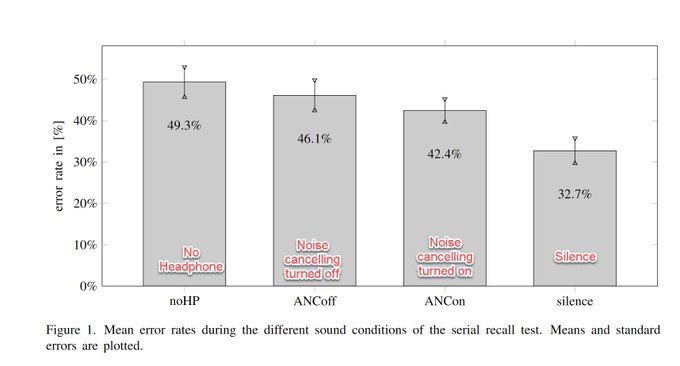
Depressingly, a debunked theory is believed by the vast majority of teachers. The belief in Learning Styles (that some people are auditory learners, visual learners, etc) is not only wrong, it can hurt. But the research shows that when teachers learn why, they change. So, a 🧵1/ 

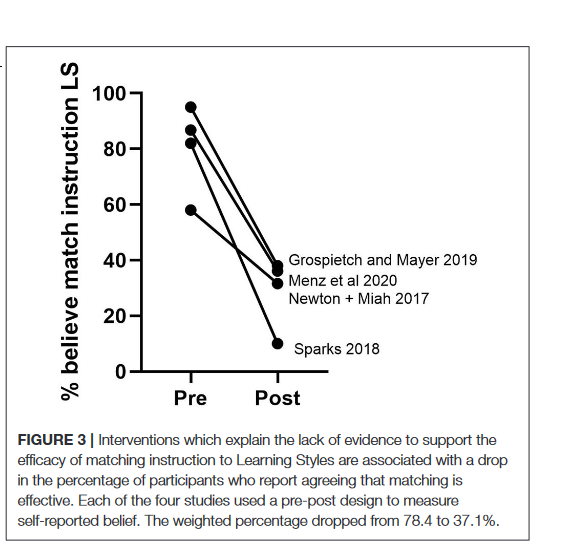

First off, there is just no evidence that teaching to a student's preferred "style" leads to any better teaching outcomes. And nobody really knows what a "learning style" is, over 71 different types have been proposed, but none help. But the belief persists for a reason... 2/


Students *think* they learn more when something matches their style... even though they objectively don’t and students don't even use their preferred styles. You may wonder, "So it doesn't work, what's the harm?"
Except we know that a belief in learning styles can hurt... 3/
Except we know that a belief in learning styles can hurt... 3/


The approach wastes time, and involves teaching to strengths, not weaknesses. People can get better at visual, verbal & other approaches with practice, and this helps overall achievement! But a belief in learning styles discourages improvement & effort. 4/ researchgate.net/publication/31…


And if you want to know what effective teaching methods are backed by research, the Great Teaching Toolkit Evidence Review lays out the state-of-the-art evidence. It is a useful read for anyone who teaches, and covers more than just Learning Styles. 5/ greatteaching.com

• • •
Missing some Tweet in this thread? You can try to
force a refresh